開発者の皆さん、こんにちは!
第 13 回 InterSystems IRIS プログラミングコンテスト(AI)への応募、投票が全て終了しました。コンテストへのご参加、またご興味お持ちいただきありがとうございました。
今回のお知らせでは、見事受賞されたアプリケーションと開発者の方々を発表します!

人工知能(AI)は、機械、特にコンピューターシステムによる人間の知能プロセスのシミュレーションです。 これらのプロセスには、学習(情報の取得と情報を使用するためのルール)、推論(概算または明確な結論に到達するためのルールを使用)、および自己修正が含まれます。 詳細はこちら。
開発者の皆さん、こんにちは!
第 13 回 InterSystems IRIS プログラミングコンテスト(AI)への応募、投票が全て終了しました。コンテストへのご参加、またご興味お持ちいただきありがとうございました。
今回のお知らせでは、見事受賞されたアプリケーションと開発者の方々を発表します!
開発者の皆さん、こんにちは!
第 13 回 InterSystems IRIS プログラミングコンテスト(AI)にご応募いただいた作品に対して加点されたテクノロジーボーナスをご紹介します!
開発者の皆さん、こんにちは!
今日から、第13回 InterSystems IRIS プログラミングコンテスト(AI) の投票が始まりました!
これだ 🔥 と思う作品への投票、よろしくお願いします!
🔥 投票はこちらから! 🔥

投票方法については、以下の通りです。
開発者の皆さん、こんにちは!
第 13 回 InterSystems IRIS プログラミングコンテスト(AI編)のテクノロジーボーナス🍆が発表されました!
ボーナスポイントを獲得して 💰賞金💰 をゲットしてください!
AI/ML ソリューションに InterSystems IntegratedML を利用すると4ポイント獲得できます。
ご利用いただくときは、IRISのバージョンが2021.1以上であることをご確認ください。ZPMパッケージマネージャを含めた最新のMLイメージは以下イメージ名です。
intersystemsdc/iris-ml-community:2021.1.0.215.0-zpm
intersystemsdc/irishealth-ml-community:2021.1.0.215.0-zpm
InterSystems IRIS 2021リリースには、R ゲートウェイと Python ゲートウェイの 2 つの新機能が含まれています。
Rゲートウェイの使用方法に関するテンプレートを公開しています。使い方の簡単なデモはこちらのビデオをご覧ください。
開発者の皆さん、こんにちは!次のコンテストのテーマが発表されました!
🏆 InterSystems AI Programming Contest 🏆
応募期間は 2021年6月28日~7月18日 です!
💰 賞金総額: $8,750 💰
(投票期間は 2021年7月19日~7月25日、勝者発表は 7月26日を予定しています)
優勝特典
1、審査員から多く票を集めたアプリケーションには、以下の賞金が贈られます。
🥇 1位 - $4,000
🥈 2位 - $2,000
🥉 3位 - $1,000
2、開発者コミュニティで多く票を集めたソリューションには、以下の賞金が贈られます。
🥇 1位 - $1000
🥈 2位 - $500
🥉 3位 - $250
複数の参加者が同数の票を獲得した場合、全参加者が勝者となり賞金は勝者間で分配されます。
参加資格
どなたでもご参加いただけます!(InterSystems 開発者コミュニティのアカウントを作成するだけでご応募いただけます)
👥 開発者がチームを組んで共同でアプリケーションを作成し、応募することもできます! 1チーム 2~5名 までご参加いただけます。
チームでご応募いただく場合は、アプリケーションの README にチームメンバー名の記載をお忘れなく!!(開発者コミュニティのプロファイルのリンクもお願いします)
コンテストのスケジュール
皆さん、こんにちは。 今日は、Jupyter Notebook をインストールして、Apache Spark と InterSystems IRIS に接続したいと思います。
注記: 以下にお見せする作業は Ubuntu 18.04 で Python 3.6.5 を使って実行しました。
Apache Zeppelin の代わりに認知度が高く、よく普及していて、主に Python ユーザーの間で人気というノートブックをお探しの方は、 Jupyter notebookをおすすめします。 Jupyter notebook は、とてもパワフルで優れたデータサイエンスツールです。 大きなコミュニティが存在し、使用できるソフトウェアや連携がたくさんあります。 Jupyter Notebook では、ライブコード、数式、視覚化インターフェース、ナレーションテキストを含む文書を作成、共有できます。 機能としてデータクリーニングや変換、数値シミュレーション、統計モデリング、データの視覚化、機械学習などが含まれています。 最も重要なこととして、問題に直面したときにその解決を手伝ってくれる大きなコミュニティが存在します。
何かうまく行かないことがあれば、一番下の「考えられる問題と解決策」をご覧ください。
まずは、Java 8 がインストールされていることを確認してください (java -version で "1.8.x" が返される)。 次に、apache spark をダウンロードし、解凍します。 それから、ターミナルで以下のコマンドを実行します。
pip3 install jupyter
pip3 install toree
jupyter toree install --spark_home=/path_to_spark/spark-2.3.1-bin-hadoop2.7 --interpreters=PySpark --user
では、ターミナルを開き、vim ~/.bashrc を実行してください。 一番下に次のコードをペーストします (これは環境変数です)。
export JAVA_HOME=/usr/lib/jvm/installed java 8
export PATH="$PATH:$JAVA_HOME/bin"
export SPARK_HOME=/path to spark/spark-2.3.1-bin-hadoop2.7
export PATH="$PATH:$SPARK_HOME/bin"
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"

それから、source ~/.bashrc を実行します。
それでは、Jupyter Notebook を起動しましょう。 ターミナルで、pyspark を実行します。

返された URL をブラウザーで開きます。 次の画像のような画面が表示されると思います。

new をクリックし、Python 3 を選択したら、次のコードをパラグラフにペーストします。
import sys
print(sys.version)
sc
以下のような出力が見られるはずです。

ターミナルで ctrl-c を実行して Jupyter を停止します。
注意: 独自のjar ファイルを追加する場合は、好きな jar ファイルを $SPARK_HOME/jars に移動します。
intersystems-jdbc と intersystems-spark を使いたいので (jpmml ライブラリも必要)、 必要な jar ファイルを Spark にコピーします。 ターミナルで次のコードを実行します。
sudo cp /path to intersystems iris/dev/java/lib/JDK18/intersystems-jdbc-3.0.0.jar /path to spark/spark-2.3.1-bin-hadoop2.7/jars
sudo cp /path to intersystems iris/dev/java/lib/JDK18/intersystems-spark-1.0.0.jar /path to spark/spark-2.3.1-bin-hadoop2.7/jars
sudo cp /path to jpmml/jpmml-sparkml-executable-version.jar /path to spark/spark-2.3.1-bin-hadoop2.7/jars
問題がないことを確認してください。 ターミナルでもう一度 pyspark を実行し、(前回の記事でご紹介した) 次のコードを実行します。
from pyspark.ml.linalg import Vectors
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
from pyspark.ml import Pipeline
from pyspark.ml.feature import RFormula
from pyspark2pmml import PMMLBuilderdataFrame=spark.read.format("com.intersystems.spark").\
option("url", "IRIS://localhost:51773/NAMESPACE").option("user", "dev").\
option("password", "123").\
option("dbtable", "DataMining.IrisDataset").load() # load iris dataset(trainingData, testData) = dataFrame.randomSplit([0.7, 0.3]) # split the data into two sets
assembler = VectorAssembler(inputCols = ["PetalLength", "PetalWidth", "SepalLength", "SepalWidth"], outputCol="features") # add a new column with featureskmeans = KMeans().setK(3).setSeed(2000) # clustering algorithm that we use
pipeline = Pipeline(stages=[assembler, kmeans]) # First, passed data will run against assembler and after will run against kmeans.
modelKMeans = pipeline.fit(trainingData) # pass training datapmmlBuilder = PMMLBuilder(sc, dataFrame, modelKMeans)
pmmlBuilder.buildFile("KMeans.pmml") # create pmml model
出力は以下のようになりました。

出力ファイルが jpmml kmeans model になっていますので、 すべて完璧です!
考えられる問題と解決策
開発者の皆さんこんにちは!
第8回 InterSystems IRIS プログラミングコンテスト(Analytics コンテスト) への応募、投票が全て終了しました。コンテストへのご参加、またご興味をお持ちいただきありがとうございました。
今回のお知らせでは、見事受賞されたアプリケーションと開発者の方々を発表します!
🏆 Experts Nomination - 特別に選ばれた審査員から最も多くの票を獲得したアプリケーションに贈られます。
🥇 1位 - $2,000 は iris-analytics-notebook を開発された @José Roberto Pereira さんに贈られました!
🥈 2位 - $1,000 は website-analyzer を開発された @YURI MARX GOMES さんに贈られました!
🥉 3位 - $500 は iris-analytics-package を開発された @Henrique Dias Gonçalves Dias さんに贈られました!
🏆 Community Nomination - 最も多くの票を獲得したアプリケーションに贈られます。
🥇 1位 - $1,000 は iris-analytics-package を開発された @Henrique Dias Gonçalves Dias さんに贈られました!
開発者の皆さん、こんにちは。
2020年最後の IRIS プログラミングコンテストの投票が始まりました!
🔥 これだ!と思う一押し作品に投票お願いします! 🔥
投票方法は?
今回から投票方法が新しくなりました!
Expert Nomination または Community Nomination を選択いただき、どの作品がどの順位になるかを指定しながら投票します。
Community Leaderboard:
| 順位 | ポイト |
|---|---|
| 1位 | 3点 |
| 2位 | 2点 |
| 3位 | 1点 |
そして、エキスパートノミネーションからの投票は以下の通りとなりました。
Experts Leaderboard:
|
エキスパートレベル |
順位 | ||
| 1位 | 2位 | 3位 | |
| GM、モデレーター、プロダクトマネージャーのVIPレベル | 9点 | 6点 | 3点 |
| グローバルマスターズのエキスパートレベル | 6点 | 4点 | 2点 |
| グローバルマスターズのスペシャリストレベル | 3点 | 2点 | 1点 |
エキスパートリーダーボードの投票はコミュニティリーダーボードにもポイント(1位3点、2位2点、3位1点)が加算されます。
投票方法について
投票は Open Exchange コンテストページで行われ、Open Exchange にサインインする必要があります。
みなさん、こんにちは。 昨日、Apache Spark、Apache Zeppelin、そして InterSystems IRIS を接続しようとしたときに問題が発生したのですが、有用なガイドが見つからなかったので、自分で書くことにしました。
Apache Spark と Apache Zeppelin とは何か、そしてどのように連携するのかを理解しましょう。
Apache Spark はオープンソースのクラスタコンピューティングフレームワークです。暗黙的なデータ並列化と耐障害性を備えるようにクラスタ全体をプログラミングするためのインターフェースを提供しています。そのため、ビッグデータを扱う必要のある場合に非常に役立ちます。 一方の Apache Zeppelin はノートブックです。分析や機械学習に役立つ UI を提供しています。組み合わせて使う場合、IRIS がデータを提供し、提供されたデータを Spark が読み取って、ノートブックでデータを処理する、というように機能します。
注意: 以下の内容は、Windows 10 で行っています。
では、必要なすべてのプログラムをインストールしましょう。
まず、Apache Zeppelin の公式サイトから Apache Zeppelin をダウンロードします。私は zeppelin-0.8.0-bin-all.tgz を使用しました。このファイルには、ApacheSpark、Scala、および Python が含まれます。
ダウンロードファイルを任意のフォルダに解凍します。解凍後、Zeppelin フォルダのルートから \bin\zeppelin.cmd を呼び出して、Zeppelin を起動します。 「Done, zeppelin server started」が表示されたら、ブラウザでhttp://localhost:8080 を開きます。 すべてうまくいった場合、「Welcome to Zeppelin!」メッセージが表示されます。
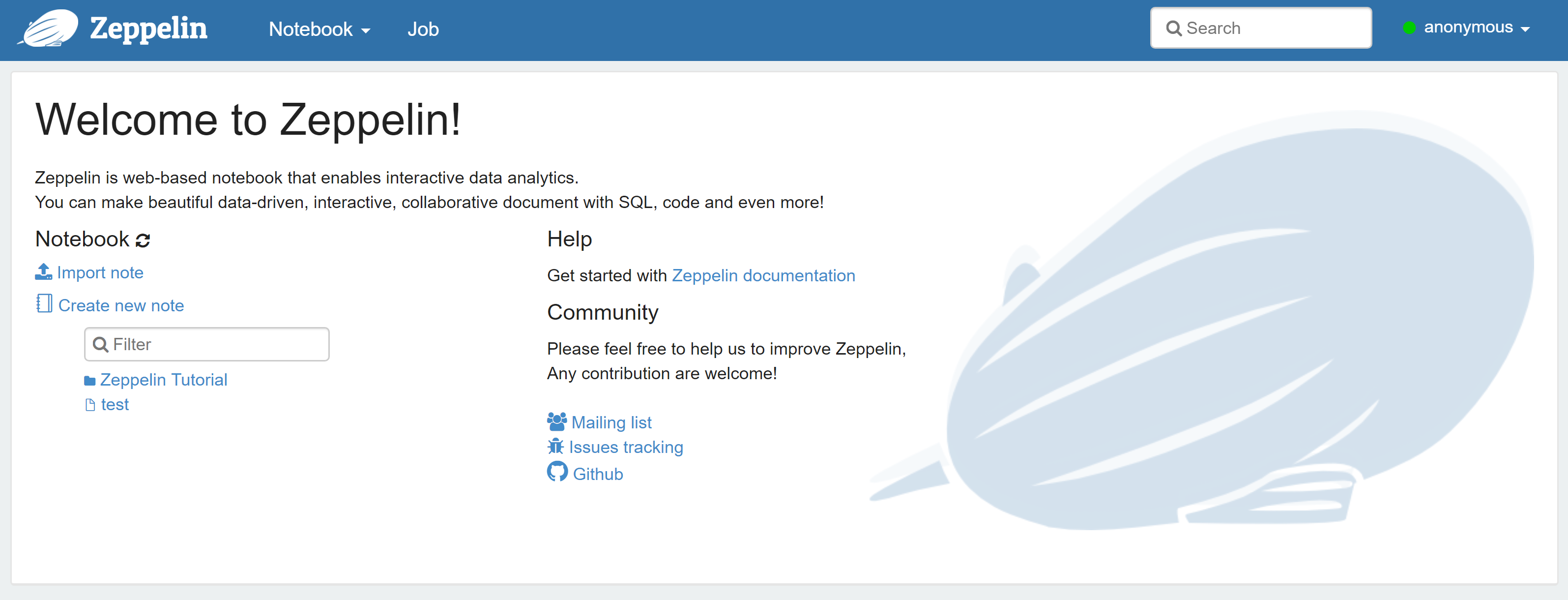
注意: InterSystems IRIS がインストール済みであることを前提としています。まだインストールしていない場合は、次のステップに進む前に IRIS をダウンロードしてインストールしてください。
ブラウザウィンドウに Zeppelin ノートブックが開いている状態です。右上の「anonymous」をクリックし、「Interpreter」をクリックします。下にスクロールして「spark」を見つけてください。

「spark」の横に「 edit 」ボタンがあるので、それをクリックしましょう。 下にスクロールして、intersystems-spark-1.0.0.jar と intersystems-jdbc-3.0.0.jar に依存関係を追加します。 私の環境は InterSystems IRIS を C:\InterSystems\IRIS\ ディレクトリにインストールしているため、追加しなければならないものは以下の場所にあります。


私の環境でのファイルは以下の通りです。
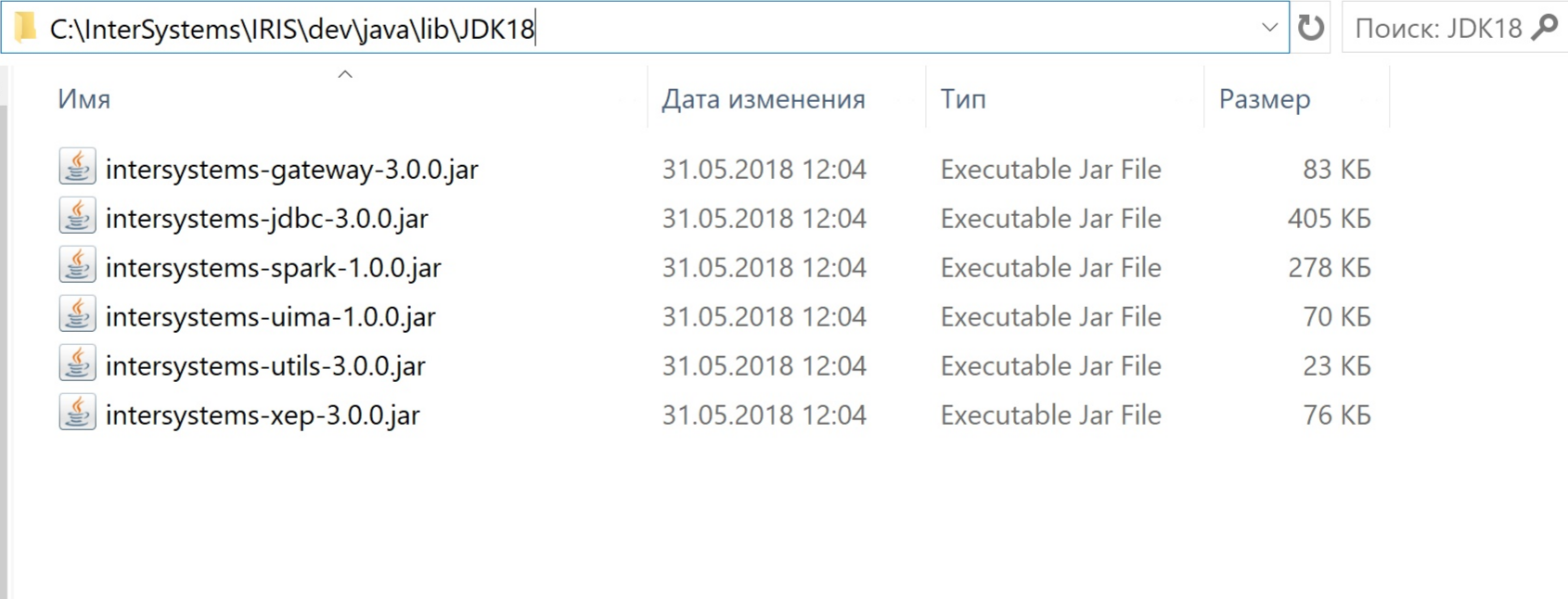
そして保存します。
動作確認してみましょう。 新しいノートを作成し、段落に次のコードを貼り付けます。
var dataFrame=spark.read.format("com.intersystems.spark").option("url", "IRIS://localhost:51773/NAMESPACE").option("user", "UserLogin").option("password", "UserPassword").option("dbtable", "Sample.Person").load()
// dbtable - name of your table
URL - IRIS アドレスを 次の書式で指定します。IRIS://ipAddress:superserverPort/namespace

この段落を実行しましょう。 うまくいけば、「FINISHED」が表示されます。
私のノートブックでの実行例です。

この記事の内容をまとめると、Apache Spark、Apache Zeppelin、および InterSystems IRIS がどのように連携できるかがわかりました。 次の記事では、データ分析についてお話しします。
みなさん、こんにちは。 今回は ML モデルを IRIS Manager にアップロードしてテストしようと思います。
注意: Ubuntu 18.04、Apache Zeppelin 0.8.0、Python 3.6.5 で以下を実行しました。
最近では実にさまざまなデータマイニングツールを使用して予測モデルを開発し、これまでにないほど簡単にデータを分析できるようになっています。 InterSystems IRIS Data Platform はビッグデータおよび高速データアプリケーション向けに安定した基盤を提供し、最新のデータマイニングツールとの相互運用性を実現します。
この連載記事では、InterSystems IRIS で利用できるデータマイニング機能について説明します。最初の記事ではインフラストラクチャを構成し、作業を開始する準備をしました。2 番目の記事では、Apache Spark と Apache Zeppelin を使用して花の種を予測する最初の予測モデルを構築しました。 この記事では KMeans PMML モデルを構築し、InterSystems IRIS でテストします。
Intersystems IRIS は PMML の実行機能を提供しています。 そのため、モデルをアップロードし、SQLクエリを使用して任意のデータに対してそのモデルをテストできます。 正解率、適合率、F スコアなどが表示されます。
まず、jpmml をダウンロードし(表を確認して適切なバージョンを選択してください)、それを任意のディレクトリに移動します。 Scala を使用しているのであれば、それで十分でしょう。

Python を使用している場合は、ターミナルで次のコマンドを実行してください。
pip3 install --user --upgrade git+https://github.com/jpmml/pyspark2pmml.git
正常にインストールされたことを確認したら Spark Dependencies に異動し、ダウンロードした jpmml に次のように依存関係を追加してください。

PMML ビルダーはパイプラインを使用しますので、ここでは以前の記事で書いたコードに若干の変更を加えました。 次のコードを Zeppelin で実行します。
%pyspark
from pyspark.ml.linalg import Vectors
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
from pyspark.ml import Pipeline
from pyspark.ml.feature import RFormula
from pyspark2pmml import PMMLBuilderdataFrame=spark.read.format("com.intersystems.spark").\
option("url", "IRIS://localhost:51773/NEWSAMPLE").option("user", "dev").\
option("password", "123").\
option("dbtable", "DataMining.IrisDataset").load() # iris データセットをロード(trainingData, testData) = dataFrame.randomSplit([0.7, 0.3]) # データを 2 セットに分割
assembler = VectorAssembler(inputCols = ["PetalLength", "PetalWidth", "SepalLength", "SepalWidth"], outputCol="features") # features を含む新しいカラムを追加kmeans = KMeans().setK(3).setSeed(2000) # 使用するクラスタリングアルゴリズム
pipeline = Pipeline(stages=[assembler, kmeans]) # 渡されたデータはまず assembler に対して実行され、その後に kmeans に対して実行されます。
modelKMeans = pipeline.fit(trainingData) # トレーニングデータを渡すpmmlBuilder = PMMLBuilder(sc, dataFrame, modelKMeans)
pmmlBuilder.buildFile("KMeans.pmml") # pmml モデルを作成
上記により、PetalLength / PetalWidth / SepalLength / SepalWidth を特徴として使用して Species を予測するモデルが作成されます。 このモデルは PMML フォーマットを使用します。
PMML は XML ベースの予測モデル交換フォーマットであり、分析アプリケーションがデータマイニングおよび機械学習アルゴリズムによって生成された予測モデルを記述し、交換する方法を提供します。 これにより、モデルの構築とモデルの実行を切り離すことができます。
出力には PMML モデルへのパスが表示されます。

IRIS Manager から [Menu] -> [Manage Web Applications] を開き、目的のネームスペースをクリックしてから [Analytics] を有効にしてから [Save] をクリックします。
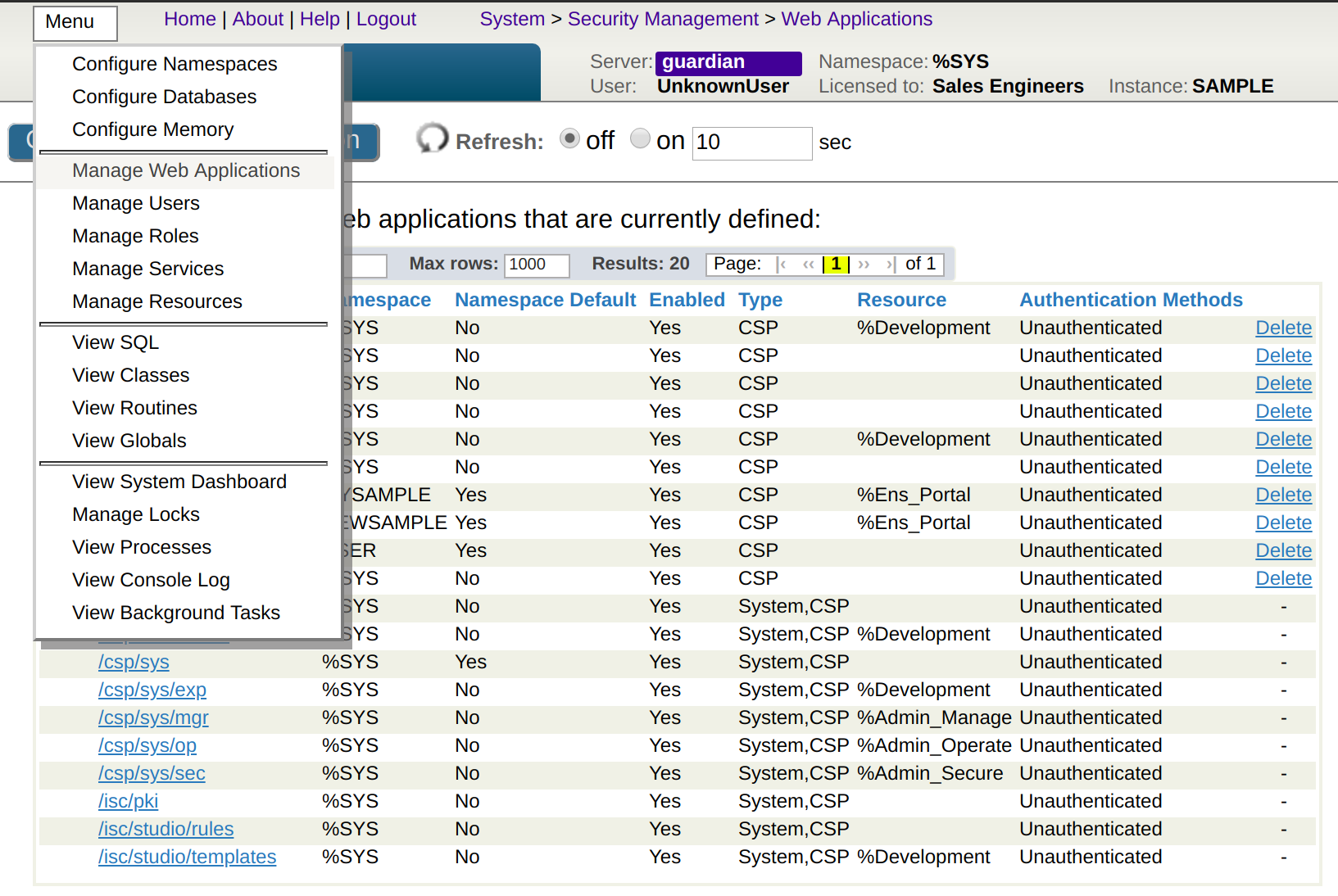

次に、[Analytics] -> [**Tools **] -> [PMML Model Tester] に移動します。
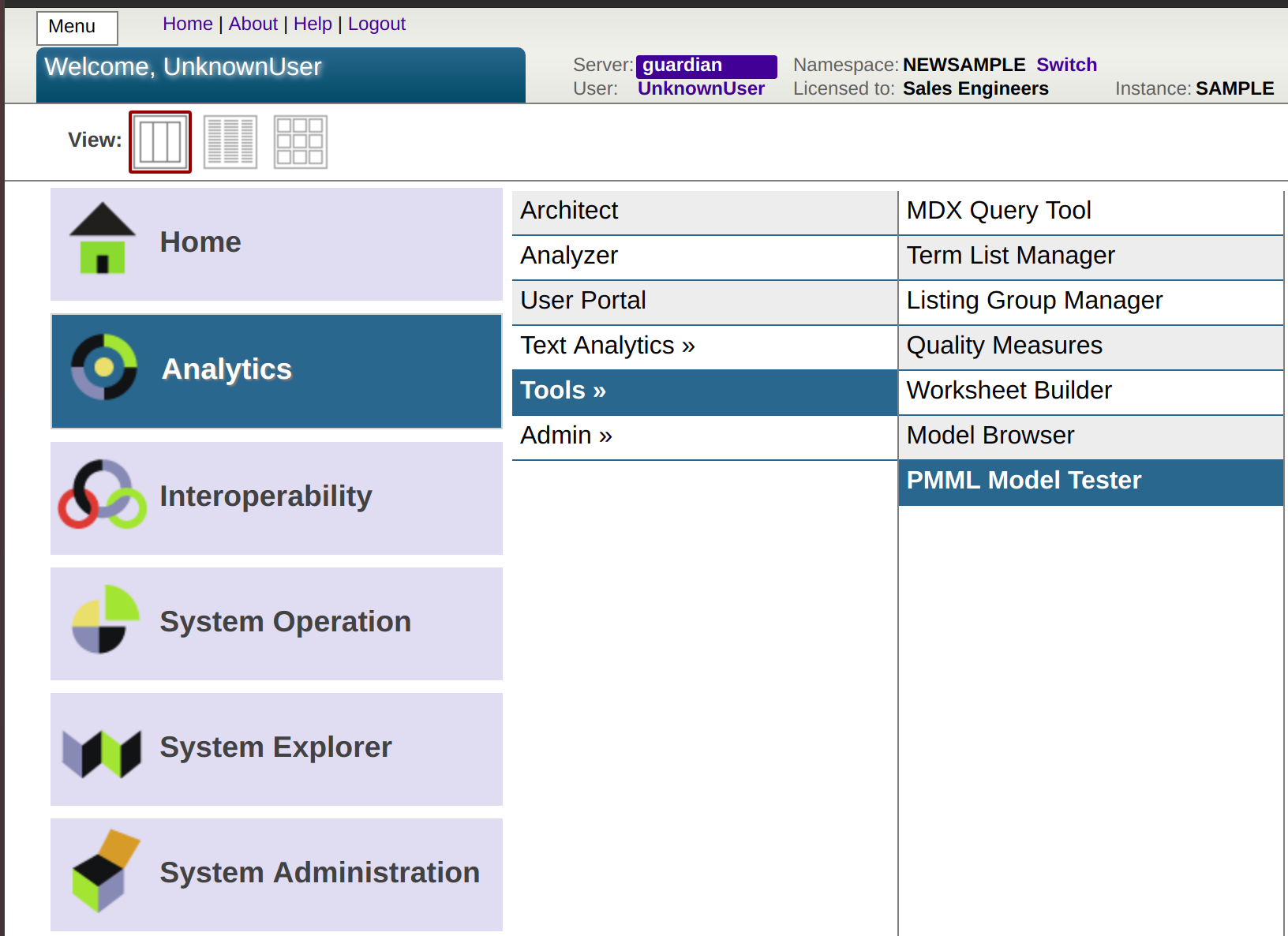
次の画像のように表示されるはずです。
[New] をクリックしてクラス名を書き、PMML ファイル(パスは出力に表示されていました)をアップロードし、[Import] をクリックします。その後、次の SQL クエリを [Custom data source] に貼り付けます。
SELECT PetalLength, PetalWidth, SepalLength, SepalWidth, Species,
CASE Species
WHEN 'Iris-setosa' THEN 0
WHEN 'Iris-versicolor' THEN 2
ELSE 1
END
As prediction
FROM DataMining.IrisDataset
KMeans クラスタリングではクラスタが数値(0、1、2)として返されるため、ここでは CASE を使用しています。また、種を数値に置換しなかった場合は誤ってカウントされてしまいます。クラスタの番号を種の名前に置換する方法をご存じの方はコメントをお願いします。
結果は以下のとおりです。
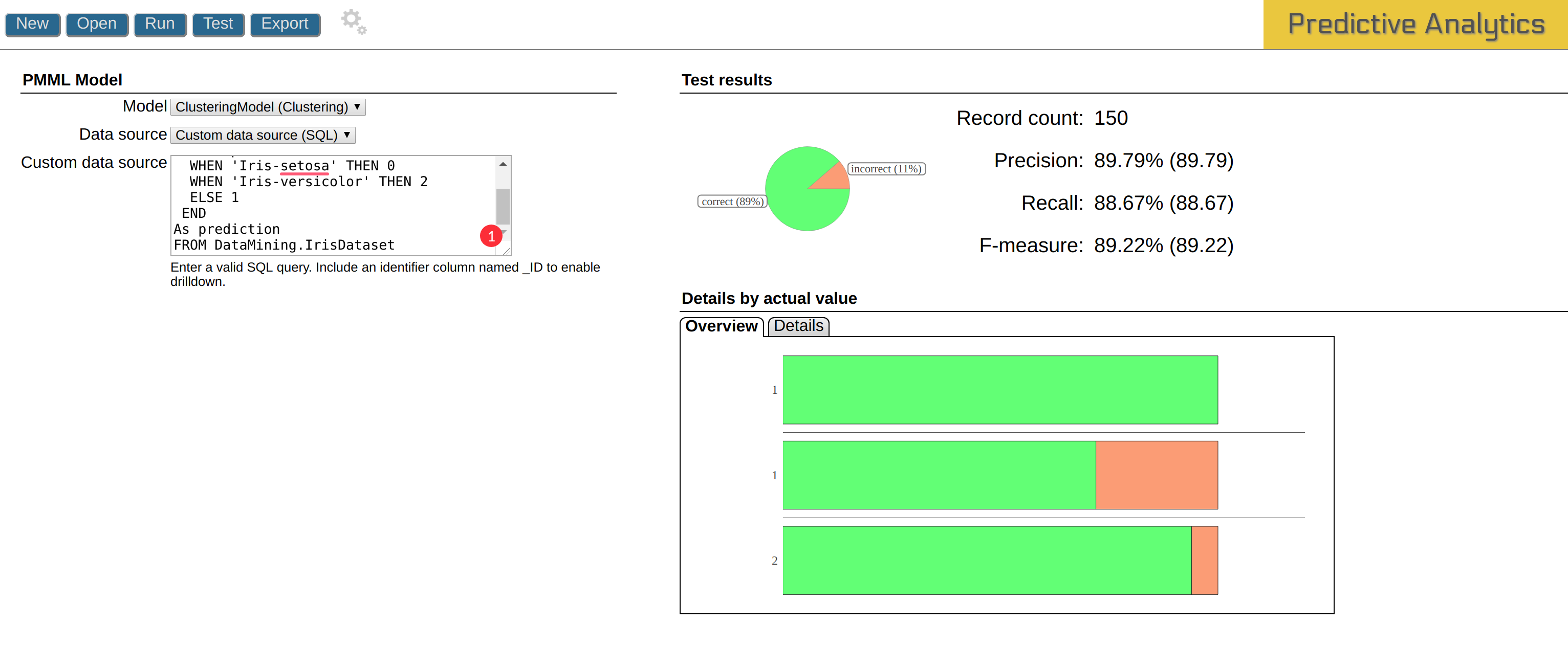
結果には詳細な分析データが表示されています。
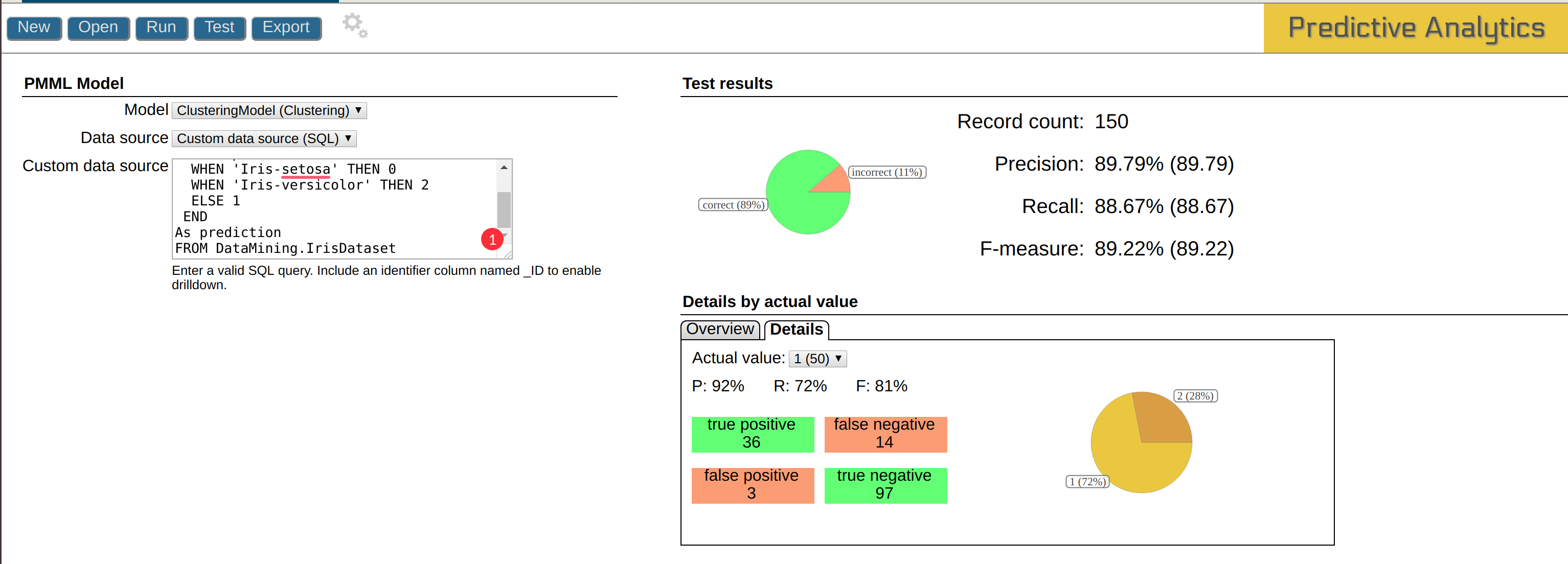
真陽性や偽陰性などの知識を深めたい方は、「適合率と再現率」を参照してください。
PMML Model Tester がデータに対してモデルをテストできる非常に便利なツールであることが分かりました。 このツールは詳細な分析データ、グラフ、SQL 実行機能を提供しますので、 別途ツールを用意しなくてもモデルをテストすることができます。
皆さんこんにちは。
第4回 InterSystems IRIS プログラミングコンテスト(AI/MLコンテスト) への応募は終了しました。コンテストへのご参加、またご興味をお持ちいただきありがとうございました。
この記事では、見事受賞されたアプリケーションと開発者の方々を発表します!
🏆 審査員賞 - 特別に選ばれた審査員から最も多くの票を獲得したアプリケーションに贈られます。
🥇 1位 - $2,000 は iris-integratedml-monitor-example を開発された José Roberto Pereir さんに贈られました!
🥈 2位 - $1,000 は iris-ml-suite を開発された Renato Banza さんに贈られました!
🥉 3位 - $500 は ESKLP を開発された Aleksandr Kalinin さんに贈られました!
🏆 開発者コミュニティ賞 - 最も多くの票を獲得したアプリケーションに贈られます。
🥇 1位 - $1,000 は iris-ml-suite を開発された Renato Banza さんに贈られました!
🥈 2位 - $250 は iris-integratedml-monitor-example を開発された José Roberto Pereir さんに贈られました!
この連載記事では、InterSystemsデータプラットフォーム用のPython Gatewayについて説明します。 また、InterSystems IRISからPythonコードなどを実行します。 このプロジェクトは、InterSystems IRIS環境にPythonの力を与えます。
現時点での連載計画です(変更される可能性があります)。
この記事はPython Gatewayをインストールするのに役立ちます。Python Gatewayをインストールして使用する方法はいくつか存在します。
IRISでは、複数ノードでクラスターを構成し、ワークロードのスケールアウト、データボリュームのスケールアウトやトランザクション処理と分析処理を異なるノードで処理するマルチワークロードを実現しています。
しかし、クラスターを構成するための設定は、ノード数が増えるにつれ煩雑になり、それらを人手の作業に全て委ねると設定ミス等を招きやすいといえます。
また、クラスタの構成を処理負荷の増加に基づいて拡張する、または逆に縮小する、あるいは、データ冗長性を追加するためにミラーリングの構成を追加するなど構成変更は、想定するより多いかもしれません。
しかもクラスタ毎に同様の設定を毎回行うとなると、人手による作業では、煩雑性だけでなく俊敏性に欠けると言わざるを得ません。
そこで、IRISには、クラスター構成作業を自動化する新しいツールICM(InterSystems Cloud Manager)が用意されました。
ここでは、ICMを使用したクラウド上でのIRIS構成の自動化の手順について説明します。
以下の作業を行うためには、InterSystemsが用意している2つのDocker Imageを事前に取得する必要があります。
この連載記事では、InterSystemsデータプラットフォーム用のPython Gatewayについて説明します。 また、InterSystems IRISの最新のAI/MLツールを利用してPythonコードなどを実行します。 このプロジェクトは、InterSystems IRIS環境にPythonの力を与えます。
現時点での連載計画です(変更される可能性があります)。
アイリスデータセットのK平均クラスタリング
みなさん、こんにちは。 今回はアイリスデータセットでk平均アルゴリズムを使用します。
注意:Ubuntu 18.04、Apache Zeppelin 0.8.0、python 3.6.5で以下を実行しました。
K平均法は、クラスタリングの問題を解決する最も単純な教師なし学習アルゴリズムの1つです。 このアルゴリズムは、同じグループ内のオブジェクト(グループはクラスターです)が他のグループ内のオブジェクトよりも(意味的に)互いに類似するようにすべてのオブジェクトをグループ化します。 例えば、緑の芝生に赤いボールのある画像があるとします。 K平均法はすべてのピクセルを2つのクラスターに分割します。 1番目のクラスターにはボールのピクセルが含まれ、2番目のクラスターには芝生のピクセルが含まれます。
アイリスデータセットは、3種のアイリスの花の特徴をいくつか含むテーブルです。 種には「Iris-setosa」、「Iris-versicolor」、「Iris-virginica」があります。 それぞれの花には5つの特徴(花びらの長さ、花びらの幅、がく片の長さ、がく片の幅、種 )があります。
まず、すべての要件を確認しましょう。 次のように、ターミナルに「which python3」貼り付けてください。
優勝特典
1、審査員から多く票を集めたアプリケーションには、以下の賞金が贈られます。
🥇 1位 - $2,000
🥈 2位 - $1,000
🥉 3位 - $500
2、Developer Community で多く票を集めたソリューションには、以下の賞金が贈られます。
🥇 1位 - $1,000
🥈 2位 - $500
複数の参加者が同数の票を獲得した場合、全参加者が勝者となり賞金は勝者間で分配されます。
参加資格
どなたでもご参加いただけます。
コンテストのスケジュール
6月29日~7月12日 応募期間
7月13日~7月19日 投票
7月20日 優秀者発表
コンテストの課題
AI / ML
InterSystems IRIS を使った AI/ML ソリューションの開発。
InterSystems IRIS を使用して開発された AI/ML ソリューションの中から、優秀アプリケーションに賞が贈られます。
アプリケーションは、ライブラリ、パッケージ、ツール、または InterSystems IRIS を使用した AI/ML ソリューション等です。
先週、私たちはInterSystems IRIS Data Platformを発表しました。これは、トランザクション、分析、またはその両方に関係なく、あらゆるデータの取り組みに対応する新しい包括的なプラットフォームです。 CachéとEnsembleでお客様が慣れ親しんでいる多くの機能が取り込まれていますが、この記事では、プラットフォームの新機能の1つであるSQLシャーディングについてもう少し詳しく説明します。これはスケーラビリティに関する強力な新機能です。
ちょうど4分41秒の時間がある方は、スケーラビリティに関するこちらの詳しい動画をご覧ください。 ヘッドホンがない方や聞き心地の良いナレーションが同僚の方の迷惑になると思う方は、どうぞ読み進めてください!
1日に何百万件という株取引を処理する場合でも、1日に数万人の患者を治療する場合でも、このような業務を支えているデータプラットフォームは、こういった大きなスケールに透過的に対処できなければなりません。 「透過的に」というのは、プラットフォームがスケーリングの面を請け負い、開発者やビジネスユーザーは処理量を気にすることなく、それぞれが専門とする業務とアプリケーションに専念することができるという意味です。