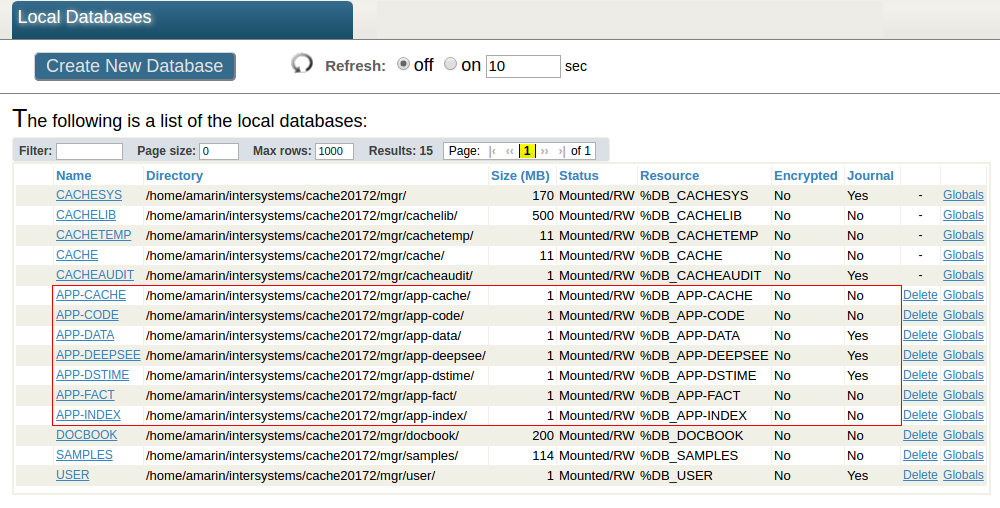
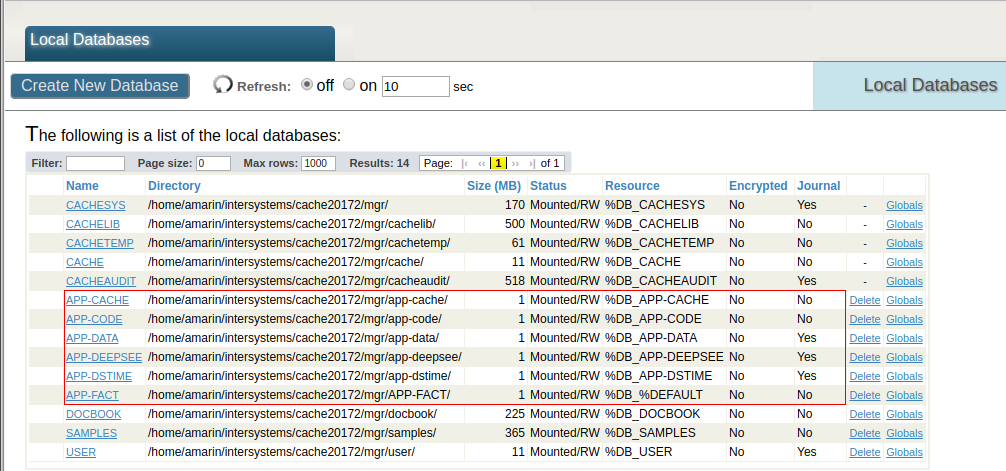
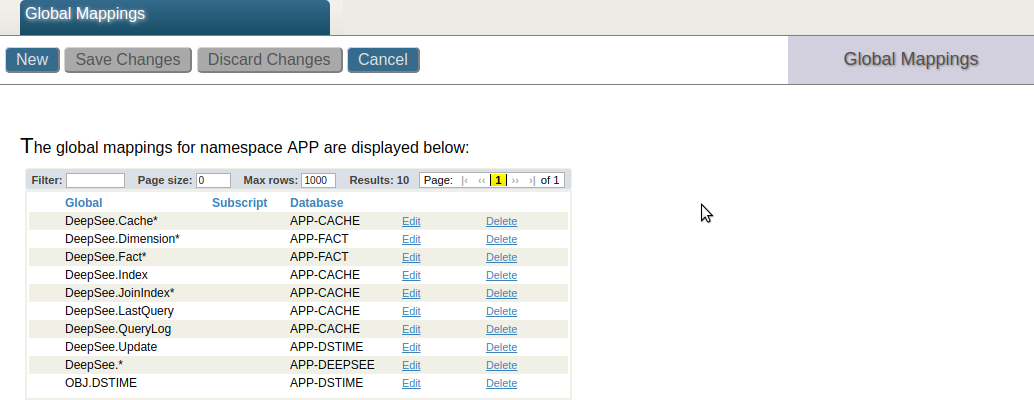
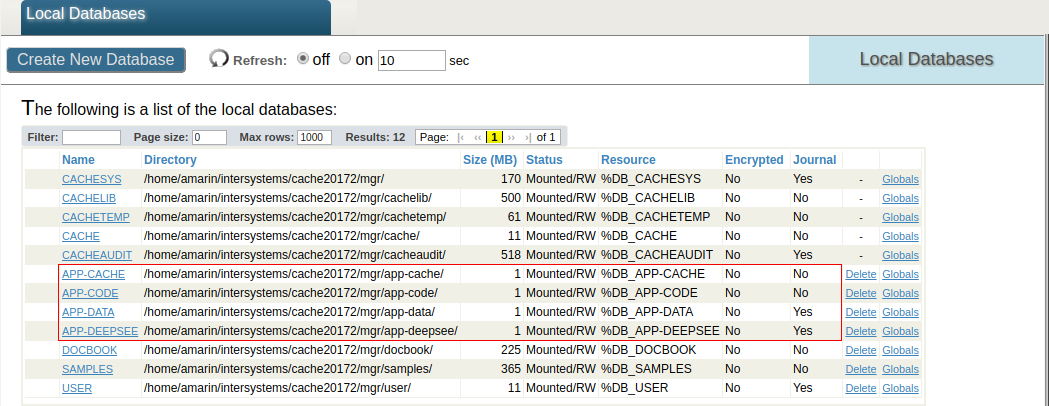
Power BI
データソースへの接続
AtScale に接続するために、SQL Server Analysis Services データベースを使用します。 Power Query エディターで開いてみましょう。 これを行うには、 Home から Transform Data を選択します。

表示されたウィンドウで、Home を選択し、New Source を展開して Analysis Services を選択します。
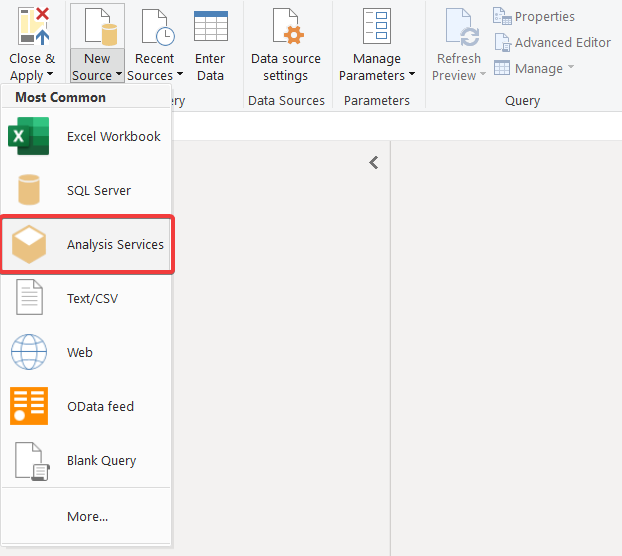
Server 行に、AtScale に公開されたプロジェクトへの MDX リンクを指定する必要があります。 必要に応じて、Database 行にプロジェクトの名前をすぐに指定することもできます。

次に、Basic タイプの認証を選択し、AtScale のログイン/パスワードを指定します。

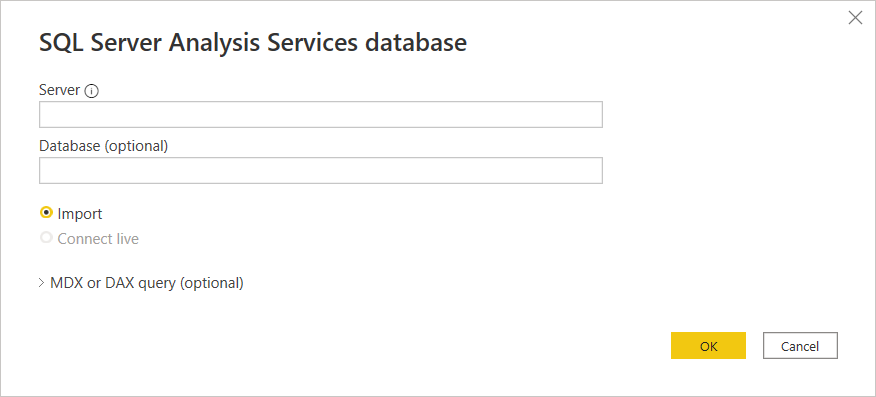
Navigator に、必要なメジャーとディメンションを指定する必要があります(フィールド間に関係性がない場合、正しいクエリを作成できないことに注意してください)。 タスクに応じて、キューブを複数のテーブルに分割することもお勧めします。 パフォーマンスを向上させ、エラーを回避するのに役立ちます。
自動更新をセットアップするには、Power BI Gateway と Windows 認証を使用する必要があります。 この記事では、この手順を省略します。
このトピックについては、AtScale ドキュメントをお読みください。
Power Query でクエリを作成する機能
列を追加したら、テーブルに変更を適用できます(列名やデータ型の変更、列の追加/変更、値の置換など)。
たとえば、列の名前を変更してみましょう。 これを行うには、列名をダブルクリックします。 数値に空のフィールドがないことを確認することをお勧めします。 すべての空の値は、null としてマークされている必要があります。 空のフィールドがある場合は、フィールド型を上書きします。 これを行うには、列名の左にある型アイコンをクリックし、必要な型を選択します。
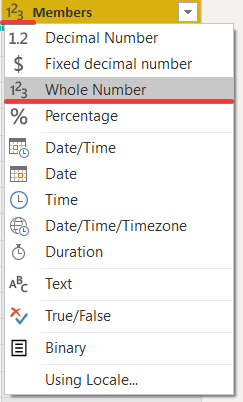
Power Query がデータ型を正しく認識しない場合があります。 この例では、日付フォーマットが誤って認識されています。
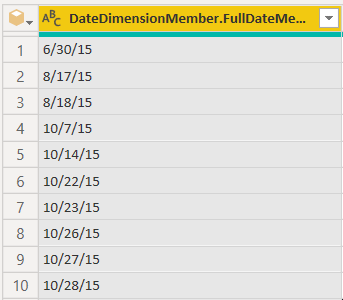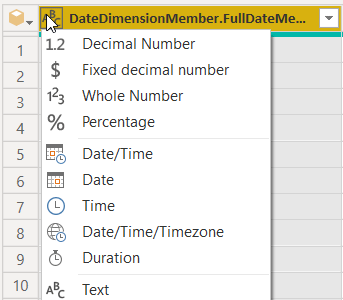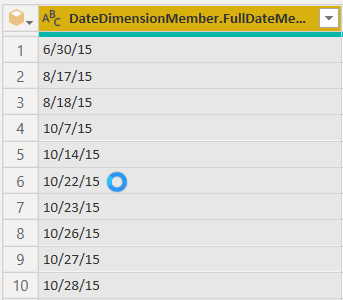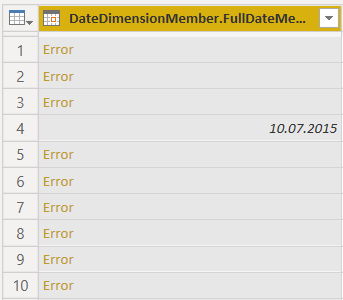
これを修正するには、特定の日付フォーマットを指定します。 指定するには、データ型のアイコンをクリックし、Use Locale… を選択します。

この場合には、Date と英語(米国)ロケールを選択しました。

これで日付が正しく表示されるようになりました。
Power Query での操作については、公式ドキュメントをご覧ください。
Power BI の操作と可視化の作成
DAX 関数を使って日付テーブルを作成する
テーブルを日付で関連付けるために、組み込みの DAX 言語を使用して、利用可能な日付に基づいてカレンダーを作成します。
日付テーブルを作成するための 1 つの方法として、組み込みの DAX 関数の使用が推奨されます。社員の誕生日といった、追加の開始日と終了日が含まれているため、手動で CALENDAR に設定することをお勧めします。 これらの関数は、最小の日付と最大の日付の間のすべての日を返します。
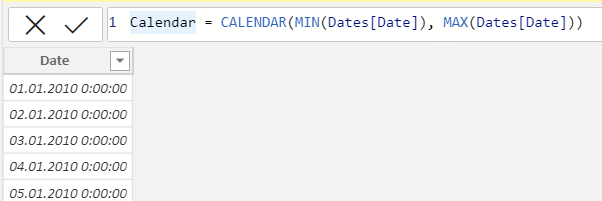
Calendar = CALENDAR(<start_date>, <end_date>))
次に、年と目的の月の名称を含む列を追加しましょう。 日付階層を使用して、年と月の名称を取得できます。 Column Tools で New Column ボタンをクリックし、式を記述します。
Month = 'Calendar'[Date].[Year]

DAX では、この式の前に列名があります。 = は式の開始を表します。 その後に式自体が記述されます。 このケースでは、単純にカレンダーの日付から [Year] を取得しています。 テーブル名を記述することが常に推奨されますが、[Date].[Year] のみを書いても構いません。 Power BI はテーブル内の既存の Date 列を参照します。
(MMM-YYYY) フォーマットで、列を追加しましょう。 これには、FORMAT 関数を使用します。
Month-Year = FORMAT('Calendar'[Date], "MMM-YYYY")
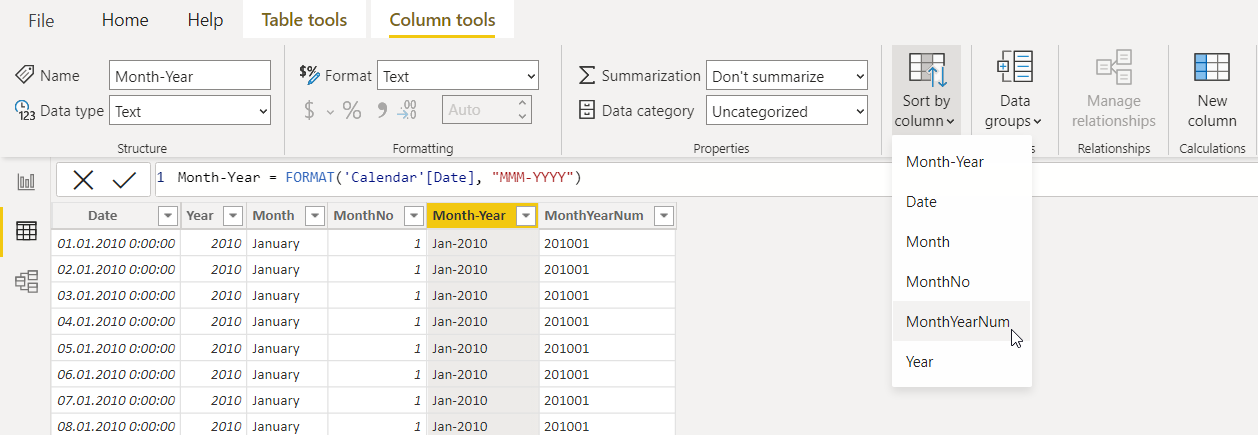
ただし、Month フィールドと Month-Year フィールドはテキストフィールドであるため、アルファベット順に並べ替えられます。 並べ替えを正しく行えるように、Month 列の月の数値を持つ MonthNum と、Month-Year 列の MonthYearNum という列を作成しましょう。
MonthYearNum = FORMAT('Calendar'[Date], "YYYYMM")
次に、並べ替え基準の列を設定する必要があります。 Column Tools に移動し、Sort by を選択して、必要な列を選択します。 テキストフィールドのある残りの列にも同じ操作を行いましょう。
DAX の式をよく理解するには、Microsoft 公式サイトのレッスンを利用することができます。
データの管理
Power BI Desktop の Model ビューを使うと、テーブルやアイテムのリレーションを視覚的に定義することができます。 この場合、関連データを含む 2 つ以上のテーブルがリンクされます。 これにより、ユーザーは複数のテーブルにまたがって関連するデータにアクセスできるようになります。 Model ビューでは、データの概略図を確認できます。
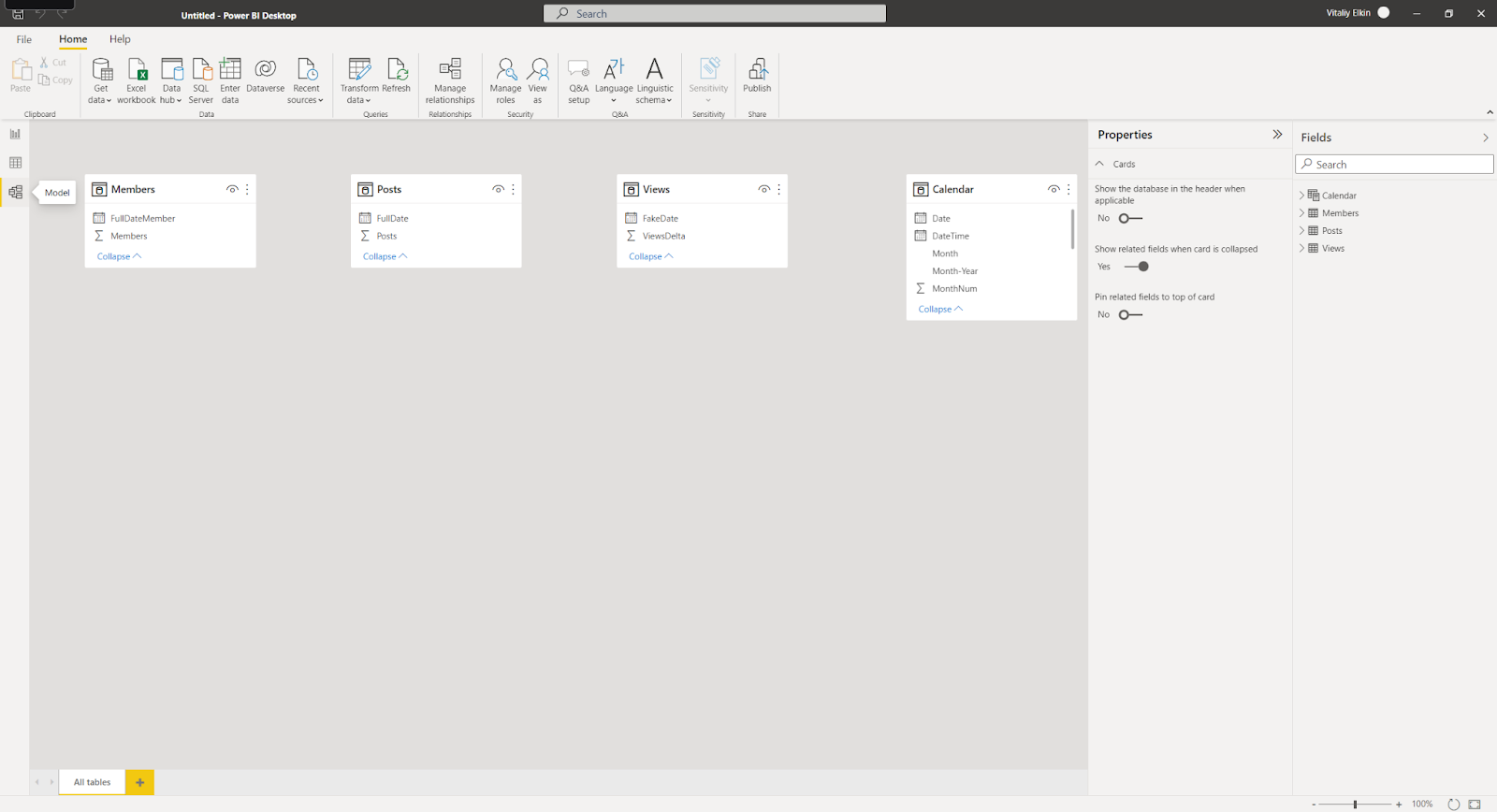
リンクの追加と削除は非常に簡単です。 リンクを作成するには、リンクに使用するフィールドをテーブル間でドラッグします。 リンクを削除するには、右クリックして Delete を選択します。
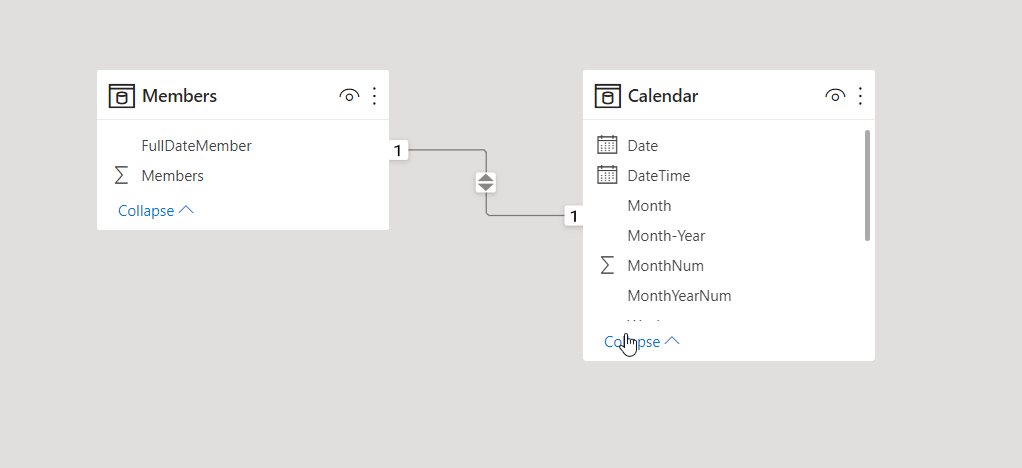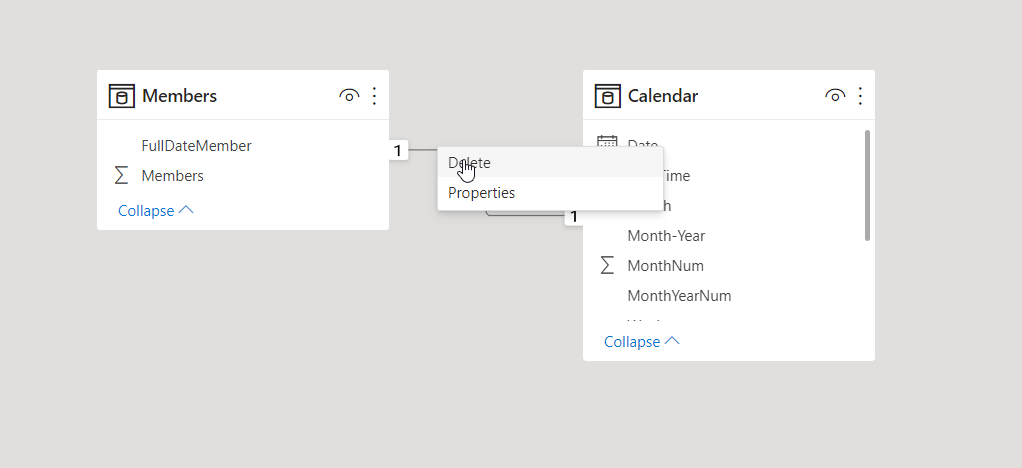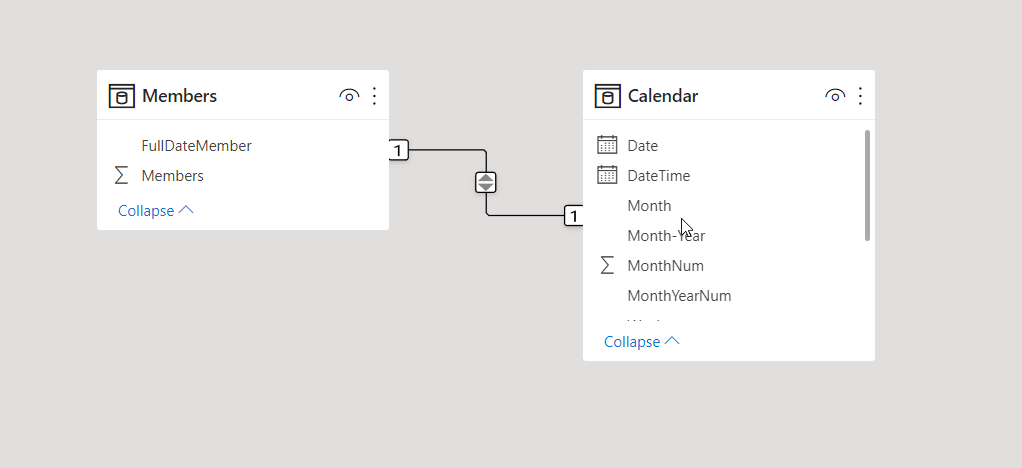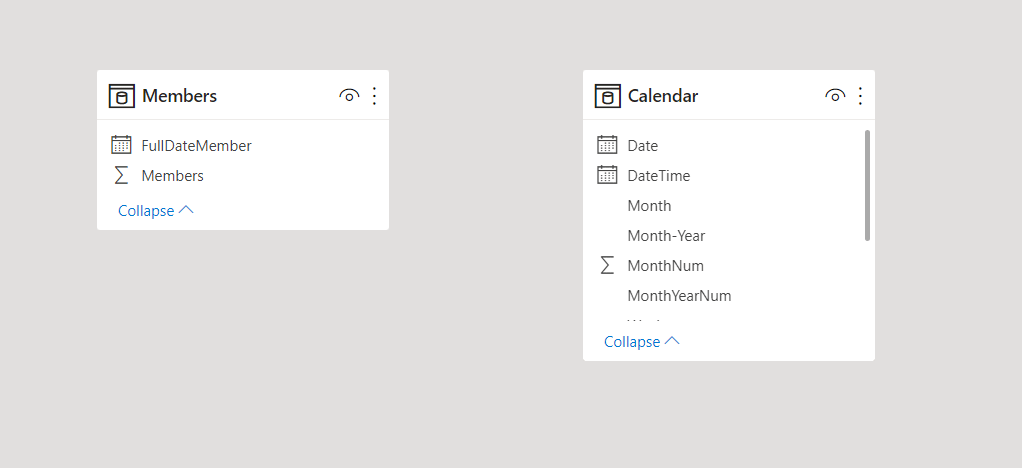
Data Link の詳細については、Home タブから Manage relationships に移動します。 Manage ダイアログボックスには、視覚的なダイアグラムではなく、リストでリンクが表示されます。 このダイアログボックスで、Autodiscover を選択し、新しいデータまたは湖心されたデータのリレーションを調べることができます。 Edit を選択すると、リンクを手動で変更できます。 編集セクションには、リンクの多重度やクロスリンク の方向を設定できます。

カーディナリティのオプションについて、以下の表で説明します。
<colgroup><col width="129"><col width="471"></colgroup> |
カーディナリティのオプション
| <td>
例
</td>
</tr>
<tr>
<td>
多対一
</td>
<td>
最も一般的なデフォルトのリレーションです。 同じテーブル内の列には、値の複数のインスタンスがあります。 関連付けられたテーブル(またはルックアップテーブル)には、値のインスタンスが 1 つしかありません。
</td>
</tr>
<tr>
<td>
一対一
</td>
<td>
1 つのテーブル内の列には、特定の値のインスタンスが 1 つしかなく、別の関連するテーブルには、特定の値のインスタンスが 1 つしかありません。
</td>
</tr>
一般に、双方向リレーションの使用を制限することをお勧めします。 モデルの毛売りパフォーマンスに悪影響がある可能性があり、レポートユーザーに混乱を招く可能性があります。
データ間に正確なリレーションを設定することで、複数のデータ要素に渡って複雑な計算を作成できます。
データモデルに関する詳細は、こちらをご覧ください。
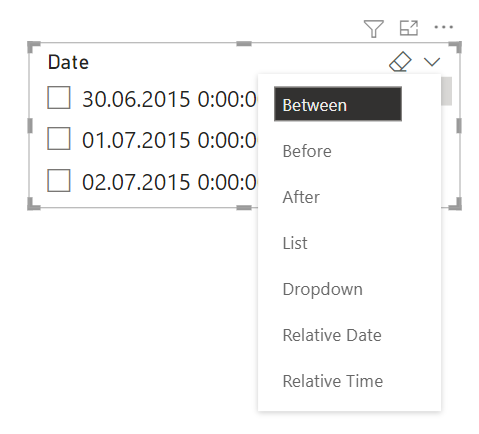
スライサー
レポートページで直接使用できる単純なフィルタは、スライサーと呼ばれます。 スライサーは、レポートページで視覚的に結果をフィルタする方法に関するヒントを提供します。 スライサーには、数値、カテゴリ別、日付別など、様々なタイプがあります。 スライサーを使用すると、ページ上のすべてのビジュアルをまとめて簡単にフィルタすることができます。

この GIF は、標準的なスライスの作業を示します。 様々なオプションを選択する際に、Ctrl を使用せずに、複数の選択範囲を設定できます。
これを行うには、スライサーを選択してから Visualizations パネルで Format visual タブを選択します。Selection を開き、Multiple selection pick Ctrlをオフにします。

スライサーの外観を変更することもできます。 変更するには、スライサー要素の右上にある下矢印を選択します。
ページに視覚的要素を追加する
視覚的要素を追加するには、Visualizations で要素を選択します。
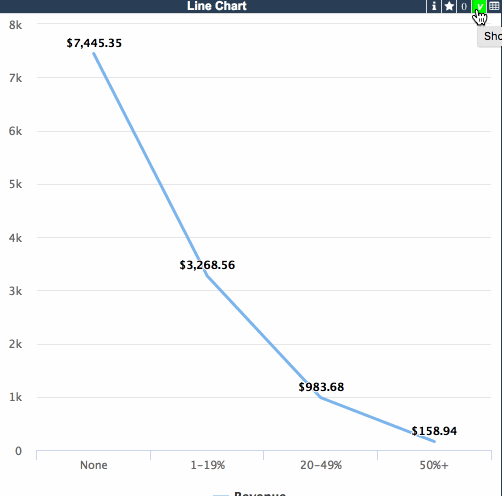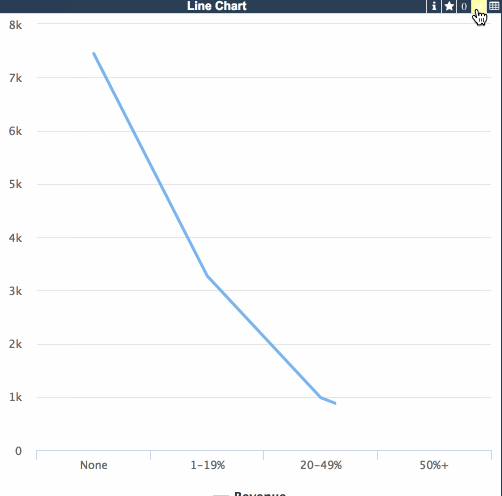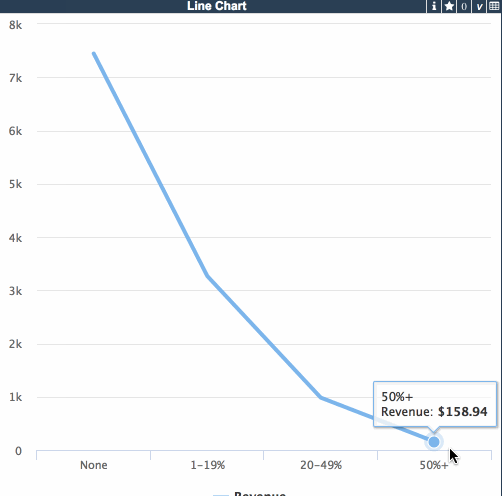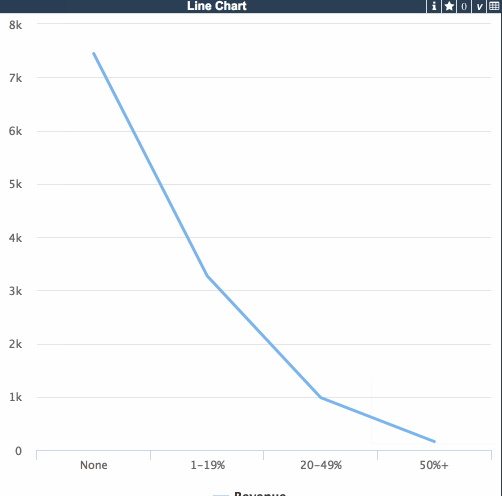
Stacked column chart(積み上げ縦棒グラフ)を追加しましょう。
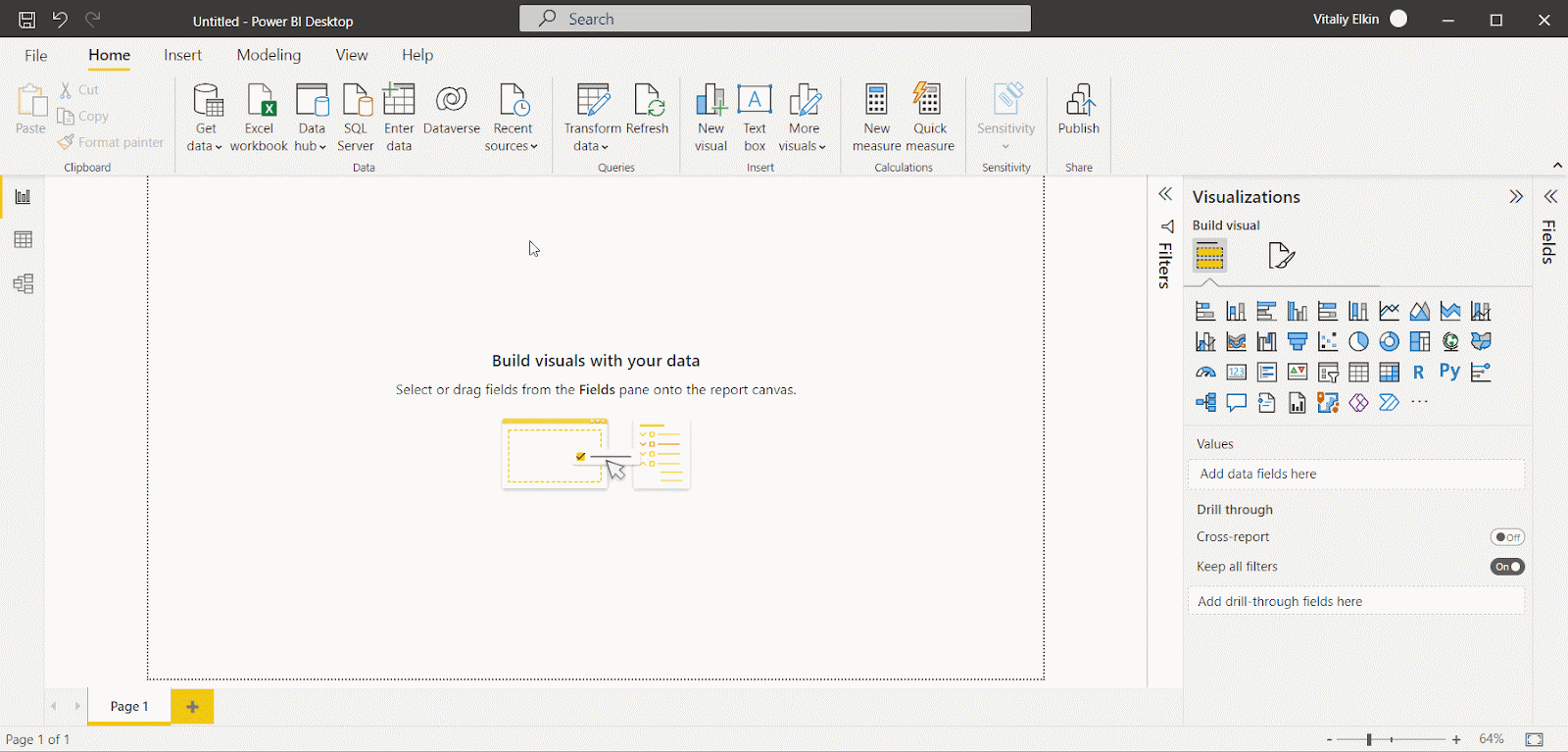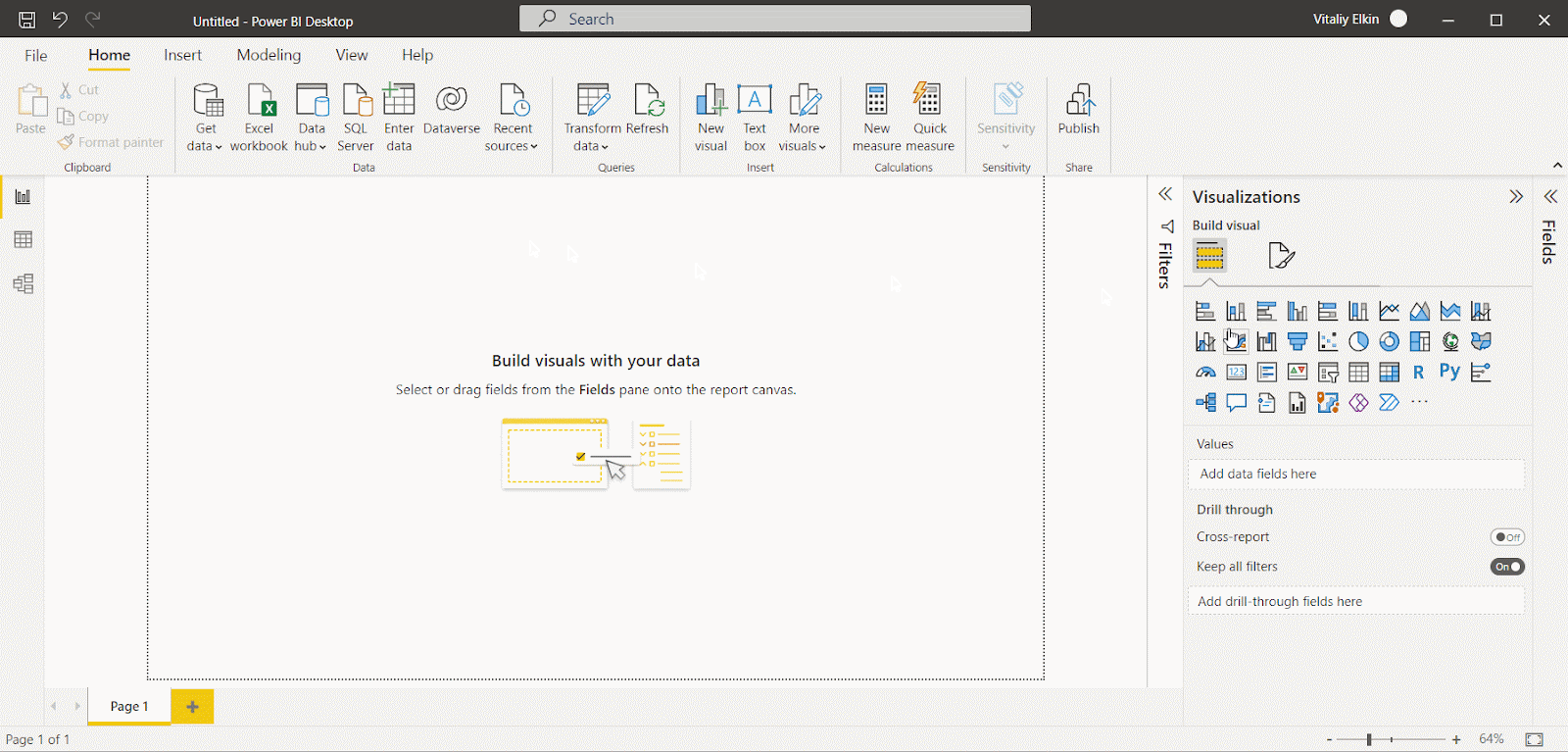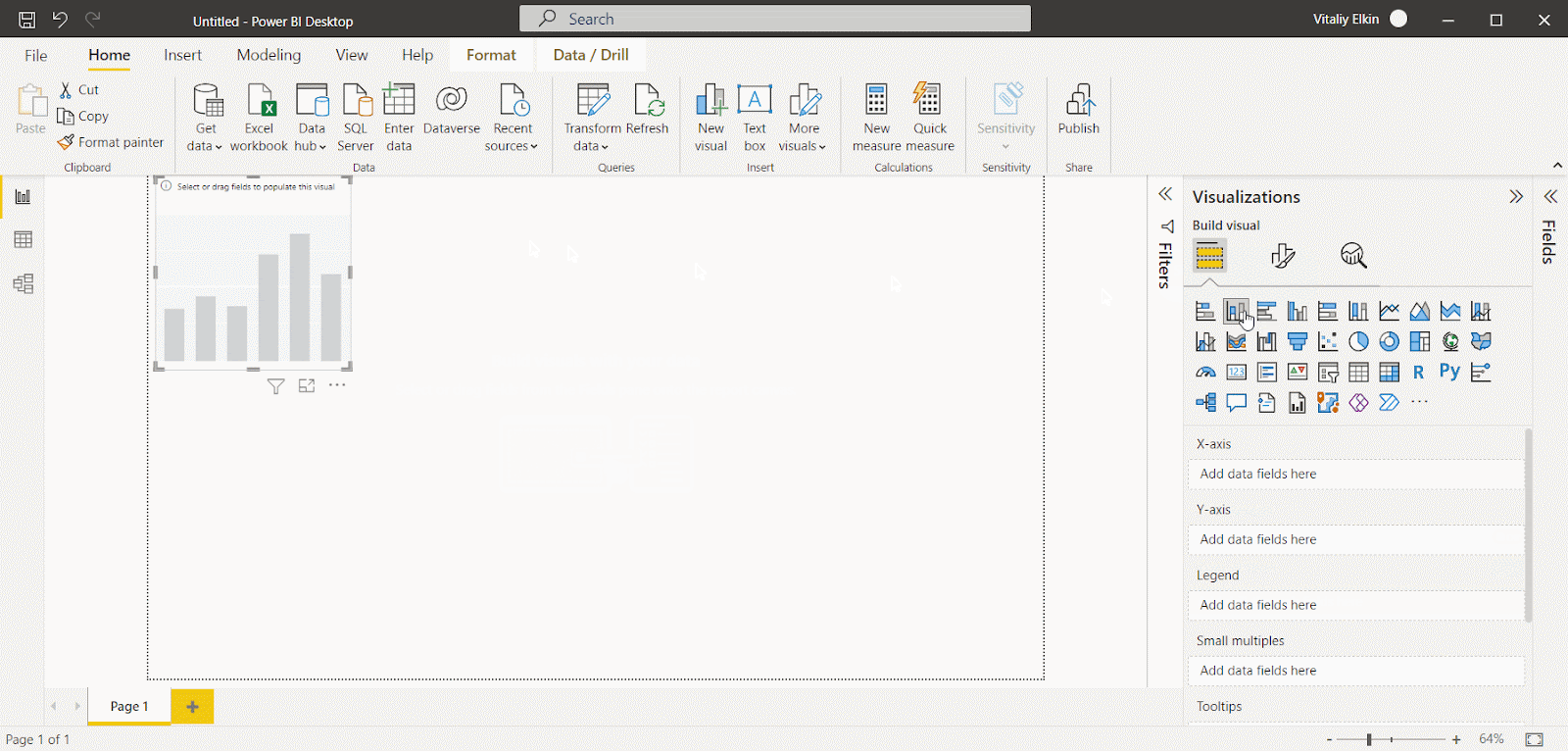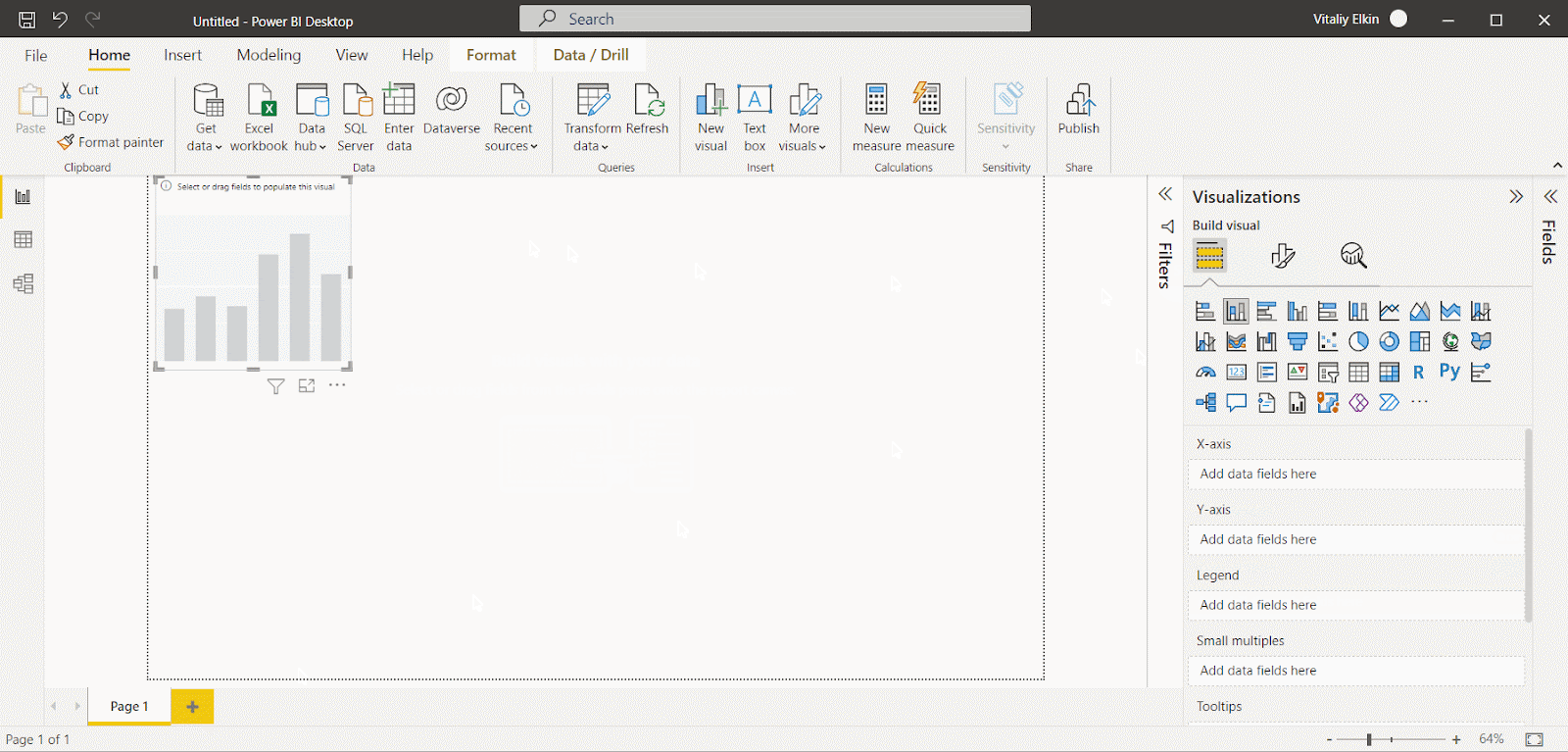
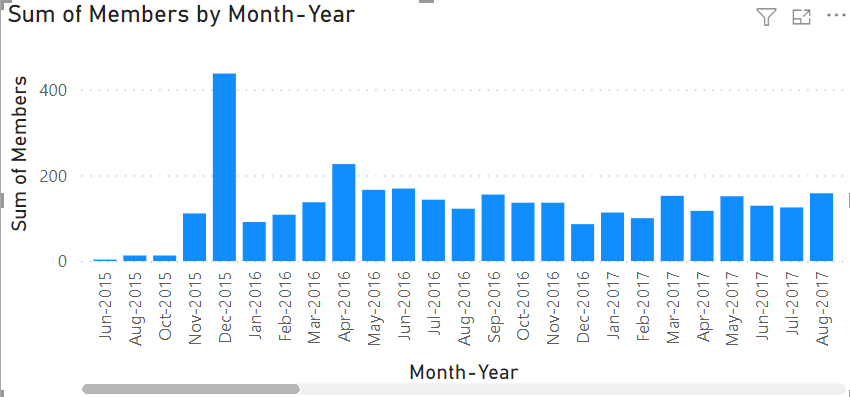
次に、表示するフィールドを選択します。 Calendar から Month-Year フィールドを追加し、テーブルから別の数値を追加しましょう。
以下のようになります。
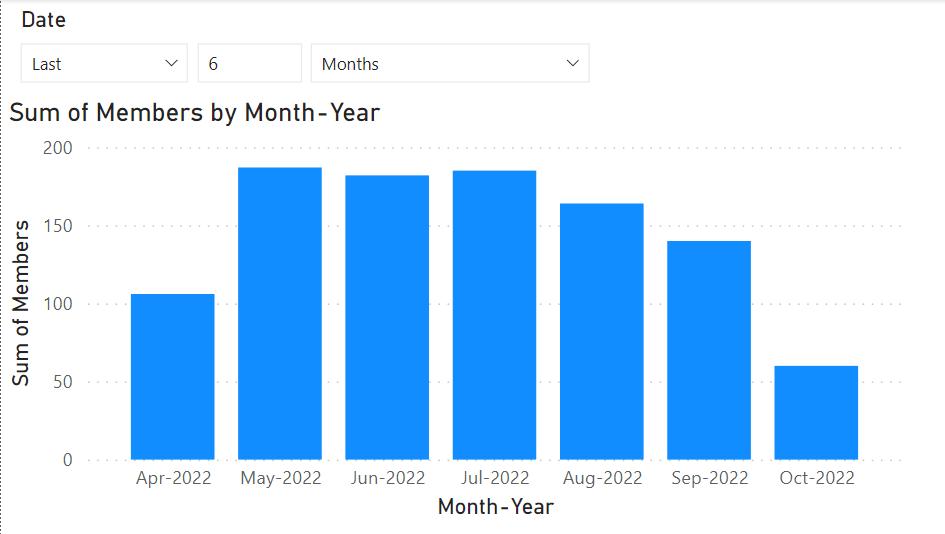
データを切り捨てるために、日付によるフィルタを追加します。 Calendar から Date フィールドを抽出し、可視化タイプをスライサーに変更してから、標準の階層を削除して通常の日付フォーマットを使用しましょう。 ビュータイプをすぐに relative date に変更します。

これで、過去 6 か月に絞り込むフィルタを適用できるようになりました。
可視化のビューは Formatting タブで変更できます。 それぞれに視覚的要素には、特別なパラメーターがあります。 これについての詳細は、こちらをお読みください。

タイトルや背景といった全般オプションを指定できるタブもあります。

さらにいくつかの可視化を追加して、外観を少し変更してみましょう。
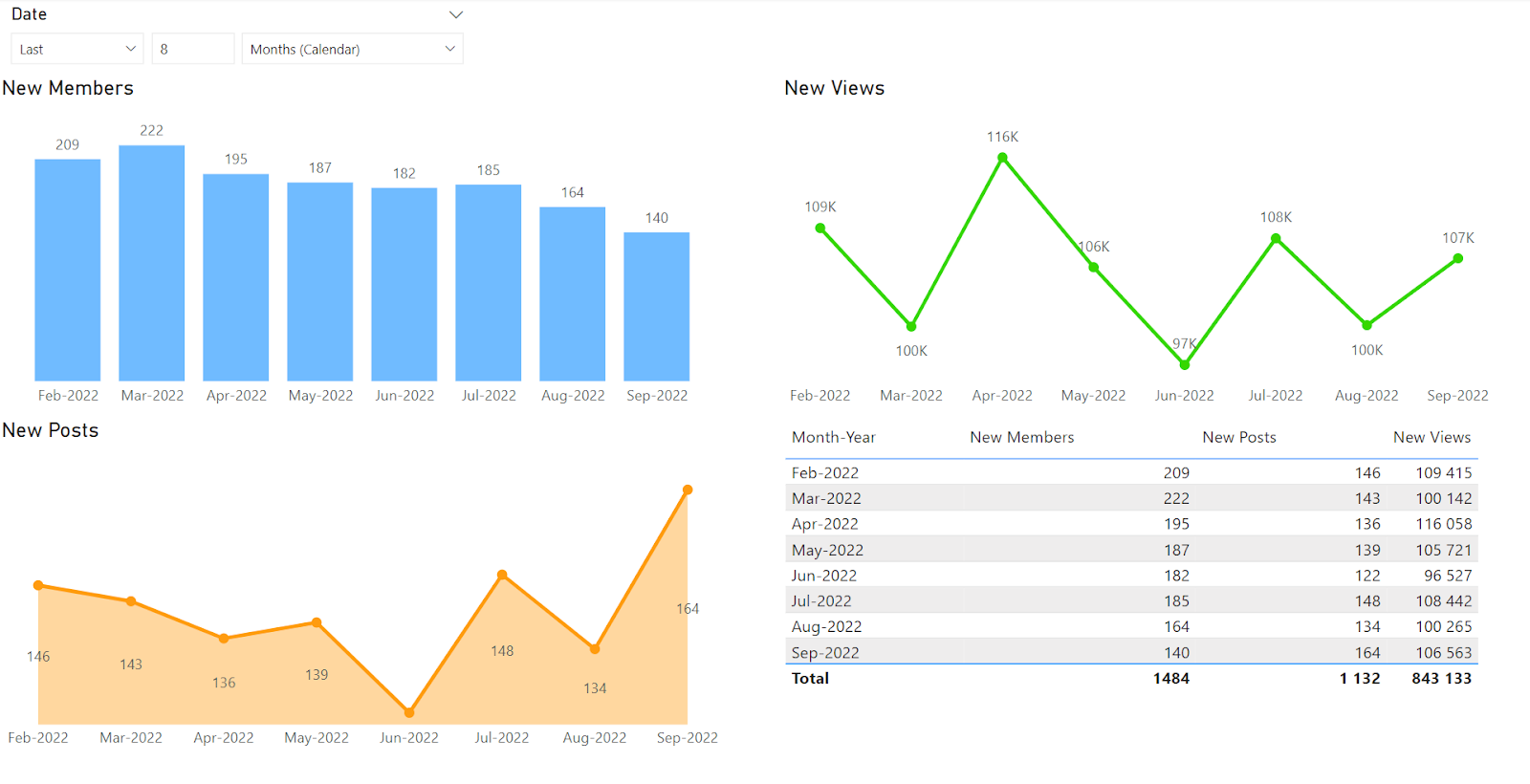
これで、簡単なダッシュボードの例ができました。
app.powerbi.com でレポートを公開する
レポートは必ず https://app.powerbi.com/home にあるポータルに公開されます。
したがって、アカウントがあり、Power BI Desktop で承認されている必要があります。
公開するには、Publish をクリックして、必要に応じてワークスペースを選択します。

正しく公開されたら、ポータルにアクセスし、レポートを確認します。
これらのレポートは調整できますが、制限が適用されます。 主に、新しい列またはメジャーを追加できないという事実に関連したものです。 ただし、これによって、既存の列に基づいて可視化を追加できなくなることはありません。
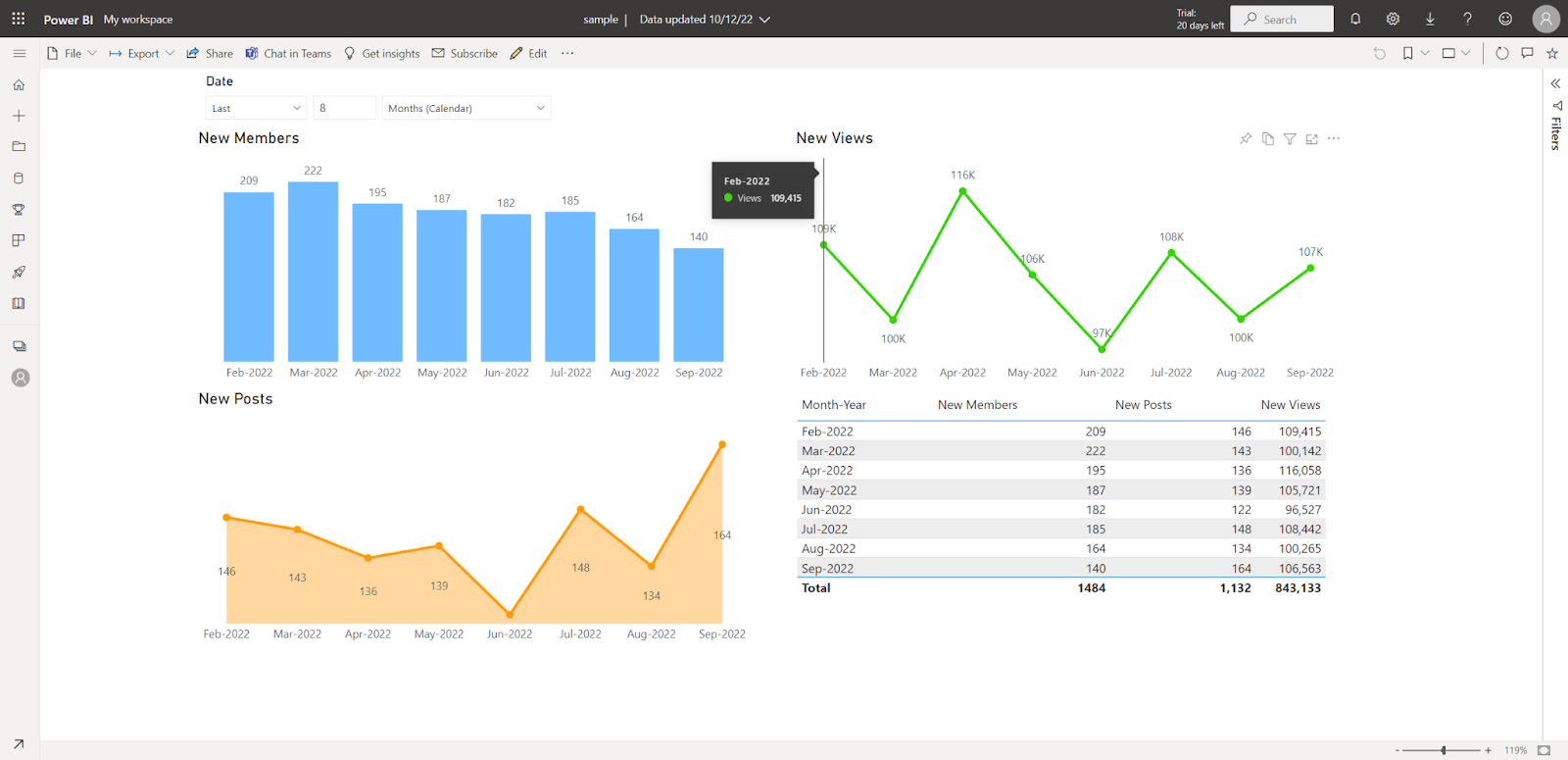
このレポートは、アクセス権を提供された Power BI ユーザーのみが使用できます。 レポートを他のユーザーと共有するには、次のオプションを使ってウェブに公開します: Publish to web (public)
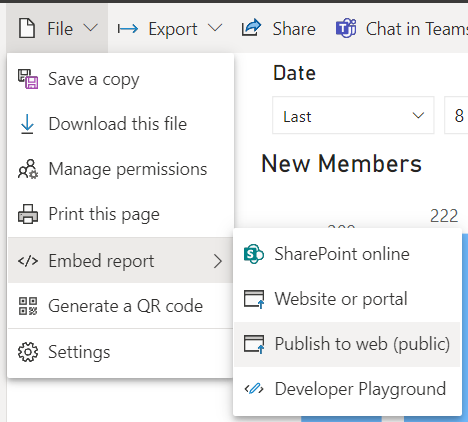
データの更新
まだ Power BI Gateway をセットアップしていないため、自動更新を有効にできません。 データは手動でのみ更新可能です。 これを行うには、Refresh ボタンをクリックしてもう一度公開します。

Tableau
事前の準備
接続するためのドライバーが必要です。 Cloudera Hive を使用します。 公式サイトからダウンロードできます(登録が必要です)。 最適なバージョンのダウンロードを選択するには、OS とビット深度を調べておく必要があります。 インストールは簡単です(説明は不要です)。
キューブへの接続
キューブを Tableau レポートに接続するには、接続ファイルをダウンロードする必要があります。 これには、Projects ページで目的の Published プロジェクトを選択してから、Connect タブに移動し、Tableau オプションを選択します。
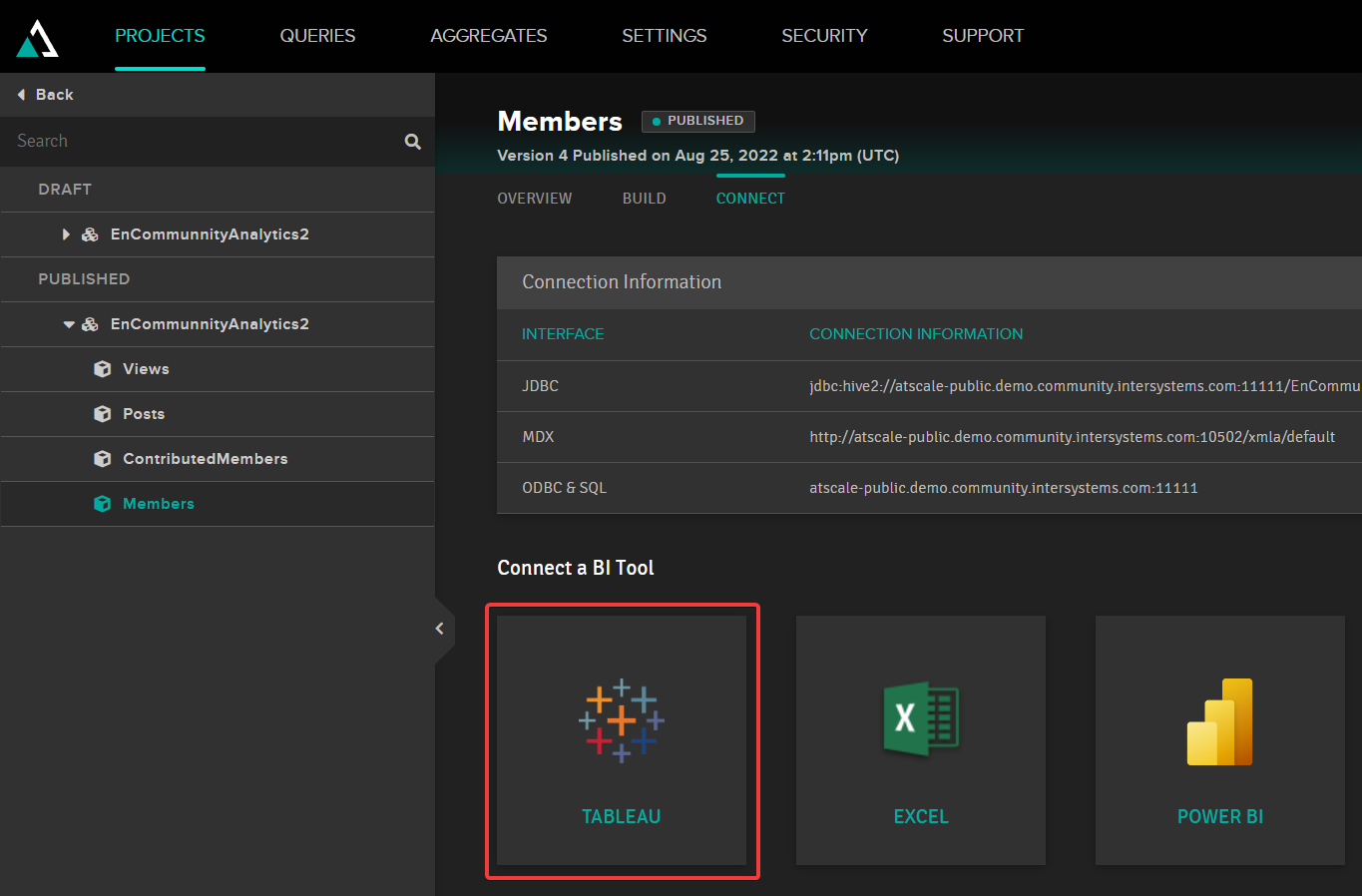
表示されるウィンドウで、[DOWNLOAD TDS]を選択します。

Tableau を起動する際に、左のメニューのリストから[Connect]> [To a File]>[More...]を選択し、先にダウンロードしていた .tds ファイルを開きます。
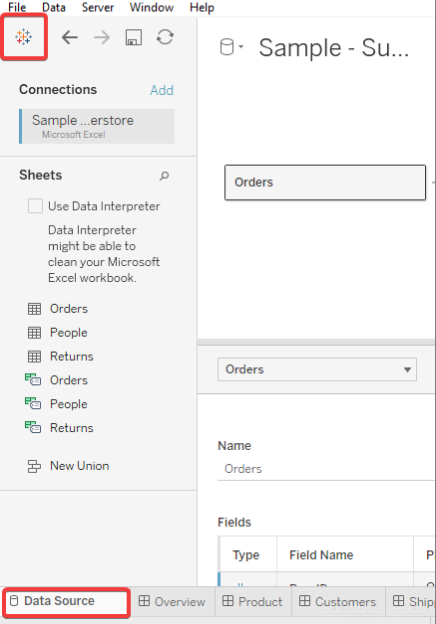
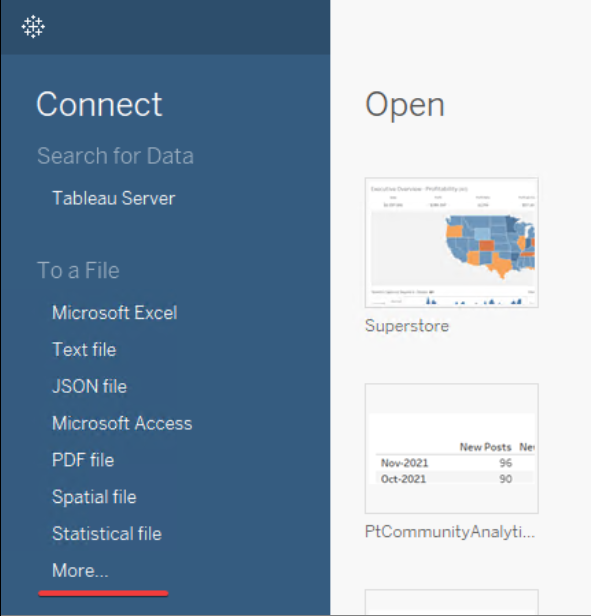
Tableau から、AtScale のユーザー名とパスワードを入力するように求められます。 認証が完了したら、キューブがデータソースに表示され、作業を開始できるようになります。
可視化を作成する
Power BI とは異なり、各ビジュアルは個別のページに作成されます。 ただし、後でワークシートにまとめることは可能です。 Tableau には行と列がありますが、インターフェースはディメンションとメジャーの配置場所によって異なります。
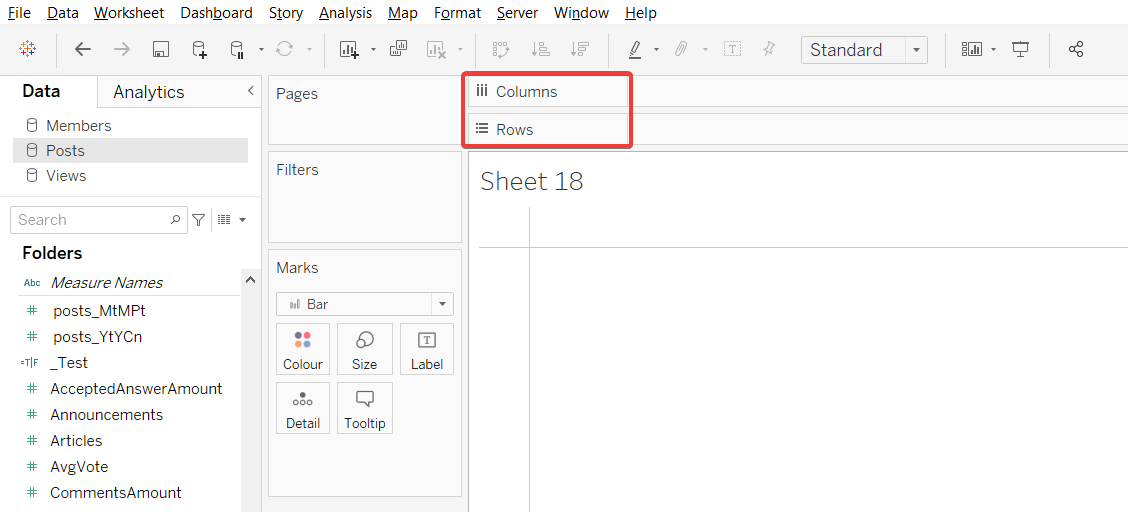


可視化のタイプを選択するには、画面の右上にある[Show Me]をクリックします(可視化のタイプを変更する際に、選択された値の場所が変わる可能性があります)。

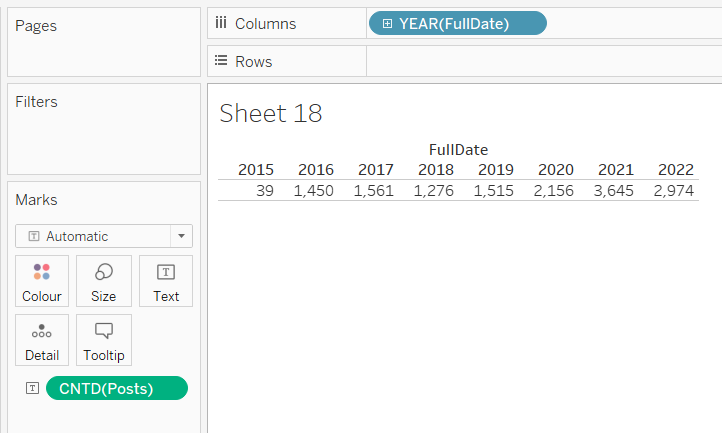
データをフィルタリングするためのデフォルトのフィールドは、左側のカードにあります。
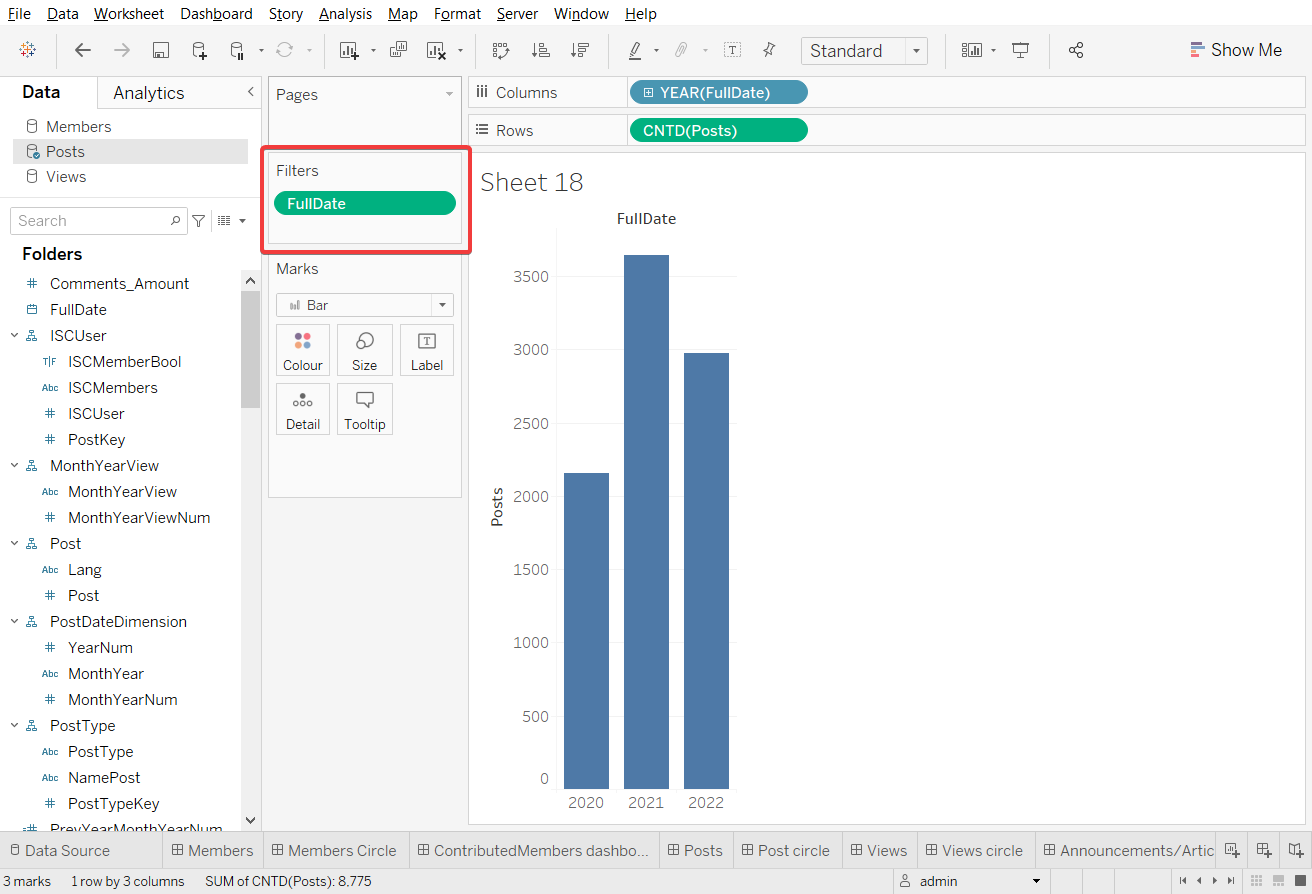
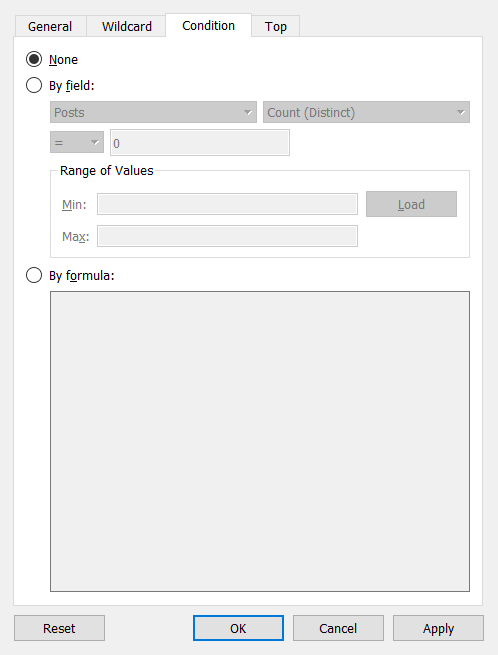
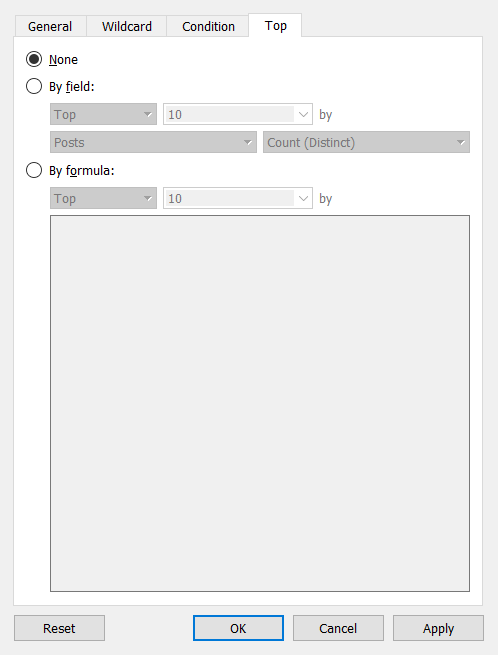
値は、Wildcard、Condition、または Top(Bottom)を基準に手動でフィルタできます。 また、これらのタイプのフィルタリングを組み合わせることも可能です。
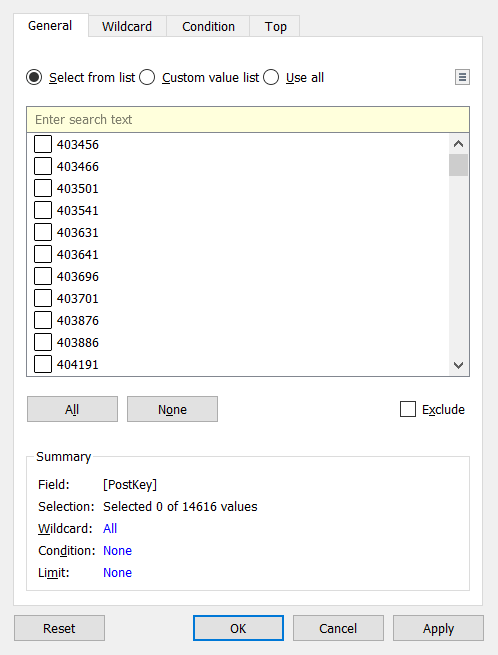
可視化フォーマットは、Marks で変更できます。

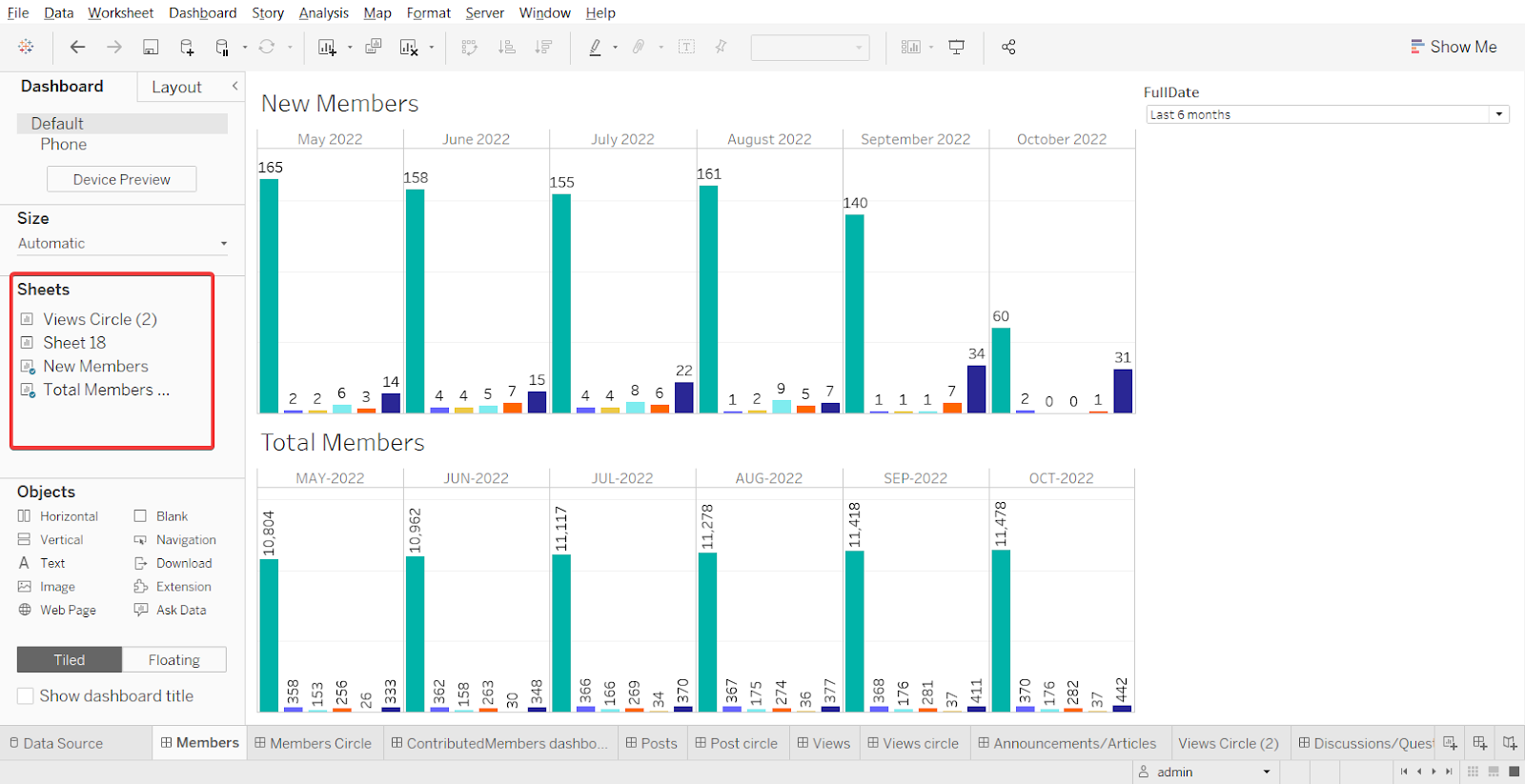
ワークシートはシートをグループ化するのに使用されます。 左側には、必要に応じてドラッグしてグループできる、使用可能なすべてのシートのリストがあります。 また、Objects カードのワークシートでは、テキストや画像の選択や追加が可能です。
サーバーに公開する
Tableau では、Tableau Puclic、Tableau Online、および Tableau Server にレポートを公開できます。 最後の 2つのプログラムには同じ機能が備わっていますが、 Tableau Online が Tableau 自体によって維持されているのに対し、Tableau Server は組織側で維持されるという点が唯一異なります。 ライブ接続を使用して、そこにレポートを公開し、公開済みのレポートを機能の制限なく変更したり、公開済みのレポートを Tableau Desktop で編集したりすることが可能です。 Server には、サーバーに登録されていない人とはレポートを共有できないというデメリットがあります。 つまり、このレポートは組織内だけでの利用を意図したものです。Tableau Public では、リンクを持つ人のみにレポートを共有できますが、ダイレクトデータ接続は使用できません。
ここでは、Tableau Server に接続します。
まず、サインインが必要です。
目的のサーバーを選択して、認証を実施します。 そして次を選択します: Publish Workbook
必要なパラメーターを指定します。表示しやすくするには、[Show sheets as tabs]をオンにすることをお勧めします。

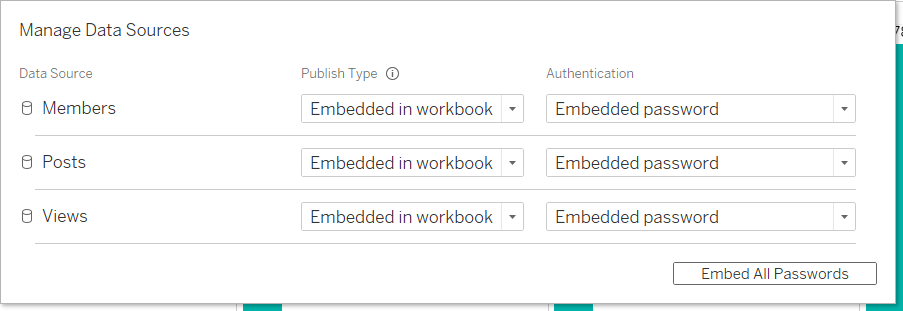
希望であれば、パスワードを埋め込むことができます。 そうでなければ、アカウントにアクセスするたびに、データソースのログインとパスワードを指定する必要があります。すべてのパスワードは、[Embed All Passwords]をクリックするとまとめて埋め込まれます。
ようやくサーバーにアクセスします。[Explore]アイテムを選択し、ブックを探しましょう。
.png)
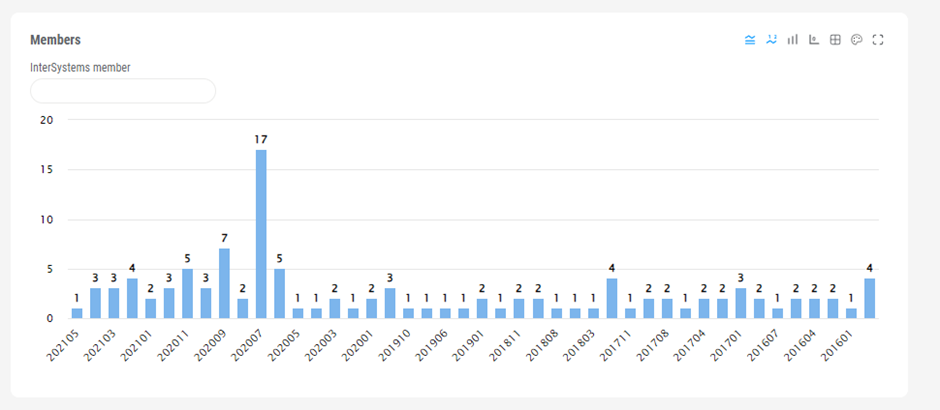










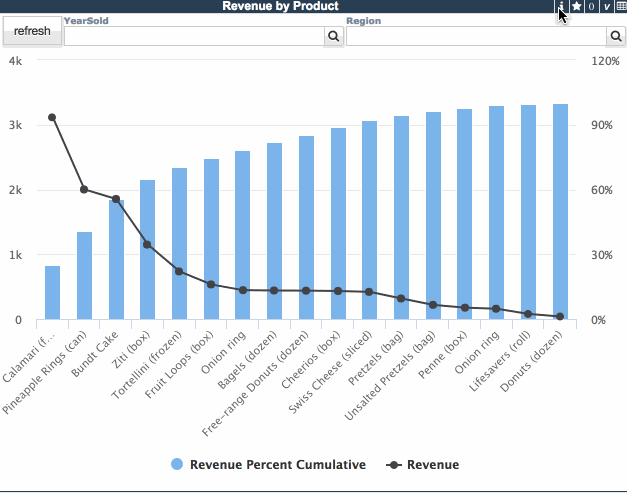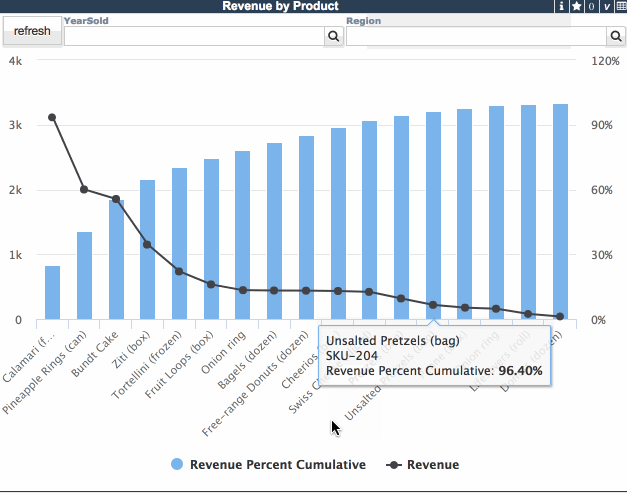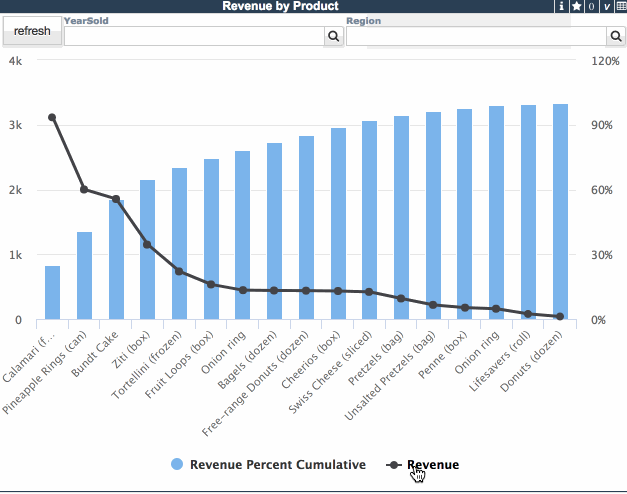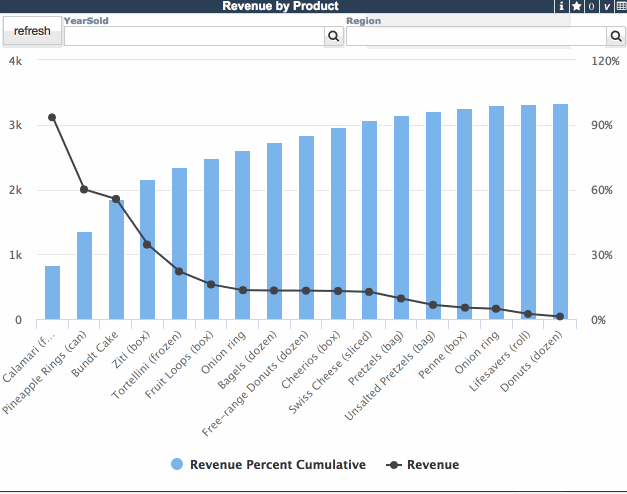
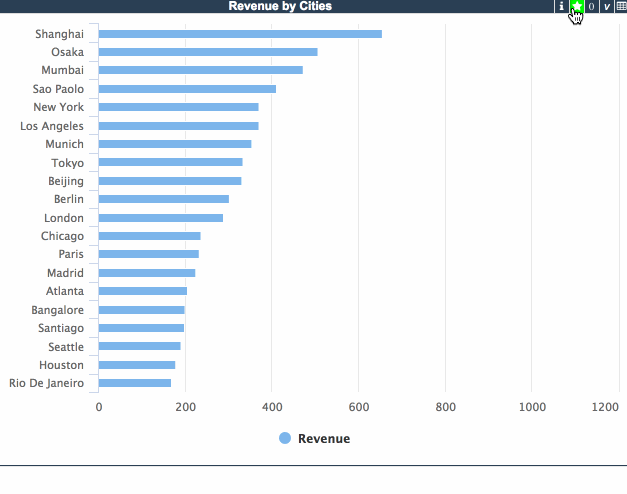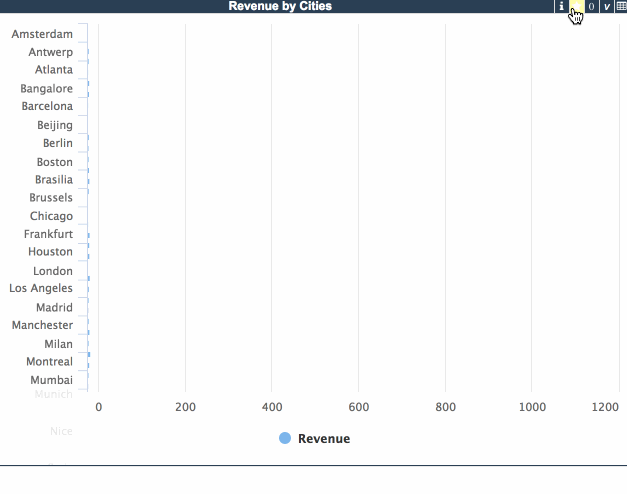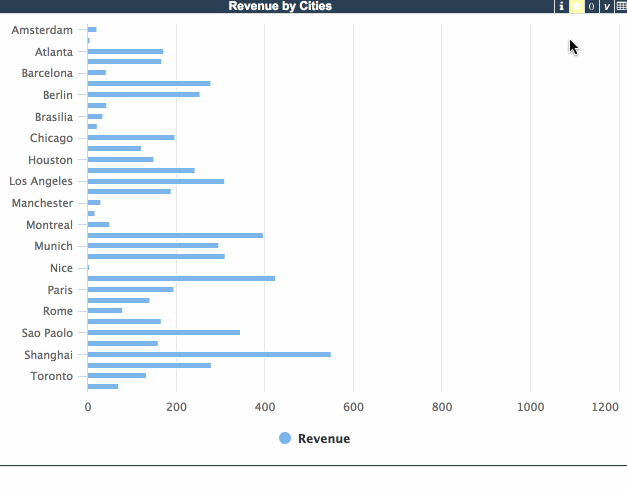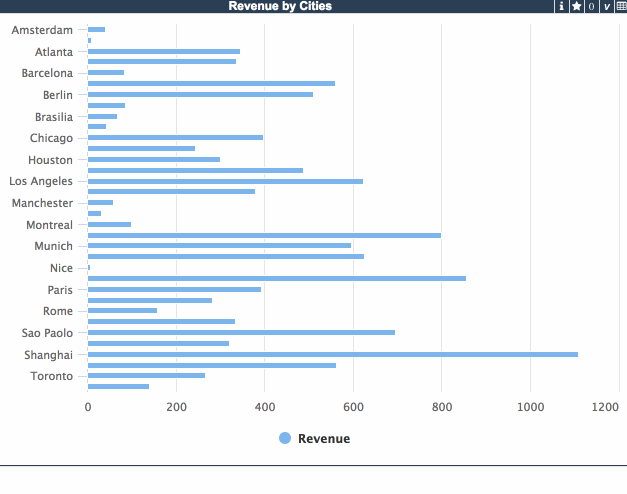 ウィジェットに行数コントロールを導入すると、上位切り替えは上位/全部の値を自動的に使用するようになります。 当然、一般的な行カウント/列カウントコントロールを追加して、特殊な上位フィルタの動作を導入することも可能です。
ウィジェットに行数コントロールを導入すると、上位切り替えは上位/全部の値を自動的に使用するようになります。 当然、一般的な行カウント/列カウントコントロールを追加して、特殊な上位フィルタの動作を導入することも可能です。