これはInterSystems FAQサイトの記事です。
質問:
オンラインバックアップの保存先にネットワークドライブ(NAS等)を指定することはできますか?
回答:
バックアップの保存先に指定することはできますが、推奨はしておりません。
推奨しない理由は、
オンラインバックアップの最終フェーズにDBアクセスを禁止して処理が実行されますが、 このとき、万一ネットワークエラー等でバックアップ処理がハングアップすることがあれば、システム全体に影響が及ぶリスクがあるからです。
情報技術においては、バックアップまたはバックアップのプロセスは、コンピュータのデータのコピーとアーカイブのことを指しており、データが損失してしまう出来事の後に元のデータを復元するために使用できます。 InterSystemsデータプラットフォームバックアップは、データベースファイルのデータのバックアップ手順およびバックアップとリカバリの途中でアプリケーションデータが失われないことを保証するすべての関連手順を意味します。
これはInterSystems FAQサイトの記事です。
質問:
オンラインバックアップの保存先にネットワークドライブ(NAS等)を指定することはできますか?
回答:
バックアップの保存先に指定することはできますが、推奨はしておりません。
推奨しない理由は、
オンラインバックアップの最終フェーズにDBアクセスを禁止して処理が実行されますが、 このとき、万一ネットワークエラー等でバックアップ処理がハングアップすることがあれば、システム全体に影響が及ぶリスクがあるからです。
これはInterSystems FAQサイトの記事です。
質問:
データベースファイルが存在するフォルダ全体をコピーしたとき、コピーしたデータベースファイルをマウントできません。なぜですか?
回答:
コピーした データベースファイル(iris.dat / cache.dat)のあるフォルダに、拡張子lck(iris.lck / cache.lck)のファイルが存在していないでしょうか?
InterSystems製品を停止せずに(もしくは、ディスマウントせずに)データベースファイルをコピーした場合、コピー前の情報を保持したままの lckファイルが残ってしまい、コピー後にマウントできない状況になります。
また、InterSystems製品を停止せずにコピーしたデータベースファイルは正しい状態ではないので、問題が生じる可能性があります。
コピー元のInterSystems製品を停止(もしくはディスマウント)した後、再度データベースファイルををコピーし直してください。
InterSystems製品のバックアップ方法の中の4つの目方法は「コールドバックアップ」です。
InterSystems製品を停止できるときに利用できるバックアップ方法です。別サーバに環境を移植するときや、コミュニティエディションから製品版キットのインストール環境にデータベースを移植する場合などにもお使いいただけます。
1. InterSystems製品を停止する
2. バックアップしたいデータベースを退避する
3. InterSystems製品を開始する
既存環境から新環境へ移植する場合などの手順
1. 既存環境のInterSystems製品を停止する。
既存環境の設定など含めて全てを新環境に移植する場合は、以下記事の退避内容をご確認いただき、ご準備ください。
2. 新環境にInterSystems製品をインストールする。
1. の手順でコピーしていた情報をもとに、新環境の構成を設定します。
3. 新環境のInterSystems製品を停止する。
4. 既存環境のデータベースファイル(.DAT)を新環境の対象となるデータベースディレクトリに配置する(置換する)
対象:ユーザ用DB
5. 新環境のInterSystems製品を開始する。
InterSystems製品のバックアップ方法の中の3つの目方法は、「並行外部バックアップ」についてです。
この方法は外部バックアップと異なり、スナップショットなどのストレージ機能がない環境に向いている方法でオンラインバックアップよりも高速にバックアップできます。(古いバージョンのInterSystems製品でも利用できるバックアップ方法です。)
ただし、バックアップやリストア手順が複雑になります。
並行外部バックアップの利用を検討される際は、事前にリストア手順についてもテスト環境などでご確認いただくことを推奨します。
データベースファイル(.DAT)を通常のコピーコマンドなどで退避します。
データベースファイルのサイズによってはコピー時間が長くなります。外部バックアップの方法を利用するとライトデーモン凍結時間のタイムアウトを迎えてしまうため、バックアップを正しく完了できません。
そのため並行外部バックアップでは、ライトデーモンの凍結を行わずデータベースのダーティコピーを行う方法を採用しています。
ダーティコピーのバックアップファイルだけでは不完全であるため、最後にオンラインバックアップの差分バックアップを行うことで完全なバックアップを取得します。
最後の手順に差分バックアップを行うため、オンラインバックアップと同様にデータベースリストを事前に作成する必要があります。
この記事は、「インターシステムズ製品をバックアップする前に確認したいこと」に続く記事で、InterSystems製品のバックアップの手法の中の「オンラインバックアップ」の仕組みと、バックアップ・リストア手順について解説します。
オンラインバックアップは、InterSystems製品が用意するバックアップ機能を利用する方法で、バックアップ対象に設定した全データベースの使用済ブロックをバックアップする方法です。
InterSystems製品のデータベースには、サーバ側で記述したコード、テーブル定義/クラス定義、データ(レコード、永続オブジェクト、グローバル)が格納されていますので、これらすべてが1つのファイルにバックアップされます。
開発者の皆さん、こんにちは。
この記事は、「インターシステムズ製品をバックアップする前に確認したいこと」に続く記事で、InterSystems製品のバックアップの手法の中の「外部バックアップ」の仕組みと、バックアップ・リストア手順について解説します。
まず、「外部バックアップ」とは、InterSystems製品の専用ルーチン使用せず、InterSystems製品以外のバックアップソリューションを使用してデータベースをバックアップする方法で、現時点の推奨されるバックアップ方法です。
詳細な説明、手順については、ドキュメント「外部バックアップ」をご参照ください。
外部バックアップでは、主に、論理ディスク・ボリュームの有効な "スナップショット" を迅速に作成するテクノロジと共に使用します。
例えば、
スナップショット・テクノロジが使用できないシステムであっても、後述する「特別な考慮」で対応できればご利用いただけます。
それでは早速、外部バックアップの前後で必要となるIRIS側の手続きと、バックアップとリストアについて確認していきましょう!
開発者の皆さん、こんにちは。
この記事では、InterSystems製品のバックアップ方法(4種類)のご紹介と、バックアップを行う前に確認しておきたい内容について解説します。
また、この記事に続くシリーズ記事では、それぞれのバックアップの仕組みと操作例を交えたバックアップとリストア手順を解説していきます。
シリーズ記事の中で行っているバックアップ練習、リストア練習の内容については、インターシステムズの講師付きトレーニングコースの中でも取り入れている内容で、一人1環境の演習環境内で実際にお試しいただいています。
参加者の皆さんと一緒に演習を進めて行きますと、データベースリストアの後に行うジャーナルリストアについては、ユーティリティから出力される確認項目が多いため、皆さん慎重に確認されながらリストアの指示を入力されています。そのため、リストア開始前の手続きや準備に意外と時間がかかっています。(実行例)
これは InterSystems FAQ サイトの記事です。
外部バックアップ機能と、SANソリューションが提供するスナップショット(スナップクローン、ミラークローンなど呼び方はベンダ毎に異なります)などのテクノロジを利用することで、バックアップ時のインスタンス停止時間を最短にすることができます。
操作手順概要は以下の通りです。
%SYS>set status=##class(Backup.General).ExternalFreeze()%SYS>set status=##class(Backup.General).ExternalThaw()
【ご参考】
ExternalFreeze() の処理は以下のようになります。
1. ジャーナルファイルの切り替え
2. データベースバッファ上の書き込み待ちバッファをすべてデータベースファイルに書き出す
3. ライトデーモンをサスペンド状態にする
これは InterSystems FAQ サイトの記事です。
バックアップ先に、共有フォルダを指定することは可能ですが、推奨しません。
バックアップの最終フェーズのDBアクセスを禁止する箇所で万一ネットワークエラー等で、バックアップがハングアップすることがあれば、システム全体に影響が及ぶリスクがあります。
記事で使用されているすべてのソースコード: https://github.com/antonum/ha-iris-k8s

前の記事では、従来型のミラーリングではなく分散ストレージに基づいて、高可用性のあるk8sでIRISをセットアップする方法について説明しました。 その記事では例としてAzure AKSクラスタを使用しました。 この記事では引き続き、k8sで可用性の高い構成を詳しく見ていきますが、 今回は、Amazon EKS(AWSが管理するKubernetesサービス)に基づき、Kubernetes Snapshotに基づいてデータベースのバックアップと復元を行うためのオプションが含まれます。
早速作業に取り掛かりましょう。 まず、AWSアカウントが必要です。AWS CLI、kubectl、およびeksctlツールがインストールされている必要があります。 新しいクラスタを作成するために、次のコマンドを実行します。
eksctl create cluster \ --name my-cluster \ --node-type m5.2xlarge \ --nodes 3 \ --node-volume-size 500 \ --region us-east-1
このコマンドは約15分掛けてEKSクラスタをデプロイし、それをkubectlツールのデフォルトのフォルダに設定します。 デプロイを確認するには、次のコードを実行します。
kubectl get nodes NAME STATUS ROLES AGE VERSION ip-192-168-19-7.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c ip-192-168-37-96.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c ip-192-168-76-18.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c
次に、Longhorn分散ストレージエンジンをインストールします。
kubectl create namespace longhorn-system kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/v1.1.0/deploy/iscsi/longhorn-iscsi-installation.yaml --namespace longhorn-system kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml --namespace longhorn-system
そして最後に、IRIS自体をインストールします。
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
この時点で、Longhorn分散ストレージとIRISデプロイがインストールされたEKSクラスタが完全に機能できる状態になります。 前の記事に戻って、クラスタとIRISデプロイにあらゆるダメージを与えて、システムがどのように修復するのかを確認するとよいでしょう。 「障害をシミュレートする」セクションをご覧ください。
IRIS EKSとLonghornはARMアーキテクチャをサポートしているため、ARMアーキテクチャに基づき、AWS Gravition 2インスタンスを使用して同じ構成をデプロイできます。
EKSノードのインスタンスタイプを 'm6g' ファミリーに変更し、IRISイメージをARMベースに変更するだけです。
eksctl create cluster \
--name my-cluster-arm \
--node-type m6g.2xlarge \
--nodes 3 \
--node-volume-size 500 \
--region us-east-1
tldr.yaml
containers: #- image: store/intersystems/iris-community:2020.4.0.524.0 - image: store/intersystems/irishealth-community-arm64:2020.4.0.524.0 name: iris
または、単に以下を使用します。
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr-iris4h-arm.yaml
以上です! ARMプラットフォームで実行するIRIS Kubernetesクラスタが出来上がりました。
本番環境グレードのアーキテクチャでよく見過ごされがちな部分に、データベースのバックアップを作成して必要なときに素早く復元するか複製する機能があります。
Kubernetesでは、一般的にPersistent Volume Snapshots(永続ボリュームスナップショット)を使用してこれを行います。
まず、必要なすべてのk8sコンポーネントをインストールする必要があります。
#Install CSI Snapshotter and CRDs kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshotcontents.yaml kubectl apply -n kube-system -f https://github.com/kubernetes-csi/external-snapshotter/raw/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshotclasses.yaml kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshots.yaml kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/deploy/kubernetes/snapshot-controller/setup-snapshot-controller.yaml kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/deploy/kubernetes/snapshot-controller/rbac-snapshot-controller.yaml
次に、LonghornのS3バケット資格情報を構成します(詳細な手順を参照)。
#Longhorn backup target s3 bucket and credentials longhorn would use to access that bucket #See https://longhorn.io/docs/1.1.0/snapshots-and-backups/backup-and-restore/set-backup-target/ for manual setup instructions longhorn_s3_bucket=longhorn-backup-123xx #bucket name should be globally unique, unless you want to reuse existing backups and credentials longhorn_s3_region=us-east-1 longhorn_aws_key=AKIAVHCUNTEXAMPLE longhorn_aws_secret=g2q2+5DVXk5p3AHIB5m/Tk6U6dXrEXAMPLE
以下のコマンドは、前の手順から環境変数を拾い、それを使ってLonghorn Backupを構成します。
#configure Longhorn backup target and credentials cat <<EOF | kubectl apply -f - apiVersion: longhorn.io/v1beta1 kind: Setting metadata: name: backup-target namespace: longhorn-system value: "s3://$longhorn_s3_bucket@$longhorn_s3_region/" # backup target here --- apiVersion: v1 kind: Secret metadata: name: "aws-secret" namespace: "longhorn-system" labels: data: # echo -n '<secret>' | base64 AWS_ACCESS_KEY_ID: $(echo -n $longhorn_aws_key | base64) AWS_SECRET_ACCESS_KEY: $(echo -n $longhorn_aws_secret | base64) --- apiVersion: longhorn.io/v1beta1 kind: Setting metadata: name: backup-target-credential-secret namespace: longhorn-system value: "aws-secret" # backup secret name here EOF
たくさんの作業に見えるかもしれませんが、基本的にLonghornに対し、指定された資格情報で特定のS3バケットを使用し、バックアップのコンテンツを保存するように指示しています。
以上です! Longhorn UIに移動すると、バックアップを作成して復元などを行えるようになっています。

Longhorn UIに接続する方法を簡単におさらいしましょう。
kubectl get pods -n longhorn-system # note the full pod name for 'longhorn-ui-...' pod kubectl port-forward longhorn-ui-df95bdf85-469sz 9000:8000 -n longhorn-system
これによって、Longhorn UIへのトラフィックはhttp://localhost:9000に転送されるようになります。
Longhorn UIを介して行うバックアップと復元は、最初のステップとしては十分かもしれませんが、もう一歩先に進み、k8s Snapshot APIを使用して、プログラムでバックアップと復元を実行してみましょう。
まず、スナップショットそのものが必要です。 iris-volume-snapshot.yaml
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: iris-longhorn-snapshot
spec:
volumeSnapshotClassName: longhorn
source:
persistentVolumeClaimName: iris-pvcこのボリュームスナップショットは、IRISデプロイに使用するソースボリュームである 'iris-pvc' を参照しています。 そのため、これを適用するだけですぐにバックアッププロセスが開始します。
IRIS書き込みデーモンの凍結と解凍をスナップショットの前後に実行することをお勧めします。
#Freeze Write Daemon echo "Freezing IRIS Write Daemon" kubectl exec -it -n $namespace $pod_name -- iris session iris -U%SYS "##Class(Backup.General).ExternalFreeze()" status=$? if [[ $status -eq 5 ]]; then echo "IRIS WD IS FROZEN, Performing backup" kubectl apply -f backup/iris-volume-snapshot.yaml -n $namespace elif [[ $status -eq 3 ]]; then echo "IRIS WD FREEZE FAILED" fi #Thaw Write Daemon kubectl exec -it -n $namespace $pod_name -- iris session iris -U%SYS "##Class(Backup.General).ExternalThaw()"
復元プロセスは非常に簡単です。 基本的には、新しいPVCを作成して、スナップショットをソースとして指定しています。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc-restored
spec:
storageClassName: longhorn
dataSource:
name: iris-longhorn-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi次に、このPVCに基づいて新しいデプロイを作成するだけです。 これを順に行うこちらのGitHubリポジトリにあるテストスクリプトをご覧ください。
この時点で、同一のIRISデプロイが2つ存在することになります。1つはもう片方のデプロイのclone-via-backupです。
どうぞお楽しみください!
*この動画は、2021年2月に開催された「InterSystems Japan Virtual Summit 2021」のアーカイブです。
この動画では、クラウド環境下で利用可能な InterSystems 製品の様々なバックアップオプションと戦略、そしてサードパーティのバックアップ代替オプションについて紹介します。
今現在、クラウド環境をご利用でない方にも役立てて頂ける情報も紹介します。ぜひご覧ください。
関連動画として、こちらも公開しています。宜しければご覧下さい。
「クラウドストレージ戦略」(字幕付き動画)
この記事では、従来のIRISミラーリング構成の代わりに、Kubernetesの Deploymentと分散永続ストレージを使って高可用性IRIS構成を構築します。 このデプロイでは、ノード、ストレージ、アベイラビリティーゾーンといったインフラストラクチャ関連の障害に耐えることが可能です。 以下に説明する方法を使用することで、RTOがわずかに延長されますが、デプロイの複雑さが大幅に軽減されます。
3ノードクラスタを実行しており、Kubernetesにいくらか詳しい方は、このまま以下のコードを使用してください。
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml上記の2行の意味がよくわからない方、またはこれらを実行できるシステムがない場合は、「高可用性要件」のセクションにお進みください。 説明しながら進めていきます。
最初の行は、Longhornというオープンソースの分散Kubernetesストレージをインストールしています。 2行目は、DurableSYS用にLonghornベースのボリュームを使って、InterSystems IRISデプロイをインストールしています。
すべてのポッドが実行状態になるまで待ちます。 kubectl get pods -A
上記の手順を済ませると、http://<IRIS Service Public IP>:52773/csp/sys/%25CSP.Portal.Home.zenにあるIRIS管理ポータル(デフォルトのパスワードは「SYS」)にアクセスできるようになります。また、次のようにしてIRISコマンドラインも使用できるようになります。
kubectl exec -it iris-podName-xxxx -- iris session iris障害をシミュレートする
では、実際に操作してみましょう。 ただし、操作の前に、データベースにデータを追加して、IRISがオンラインになったときに存在することを確認してください。
kubectl exec -it iris-6d8896d584-8lzn5 -- iris session iris
USER>set ^k8stest($i(^k8stest))=$zdt($h)_" running on "_$system.INetInfo.LocalHostName()
USER>zw ^k8stest
^k8stest=1
^k8stest(1)="01/14/2021 14:13:19 running on iris-6d8896d584-8lzn5"ここからが「カオスエンジニアリング」の始まりです。
# IRISを停止 - コンテナは自動的に再開します
kubectl exec -it iris-6d8896d584-8lzn5 -- iris stop iris quietly
# ポッドを削除 - ポッドが再作成されます
kubectl delete pod iris-6d8896d584-8lzn5
# irisポッドの配信によりノードを「強制ドレイン」 - ポッドは別のノードで再作成されます
kubectl drain aks-agentpool-29845772-vmss000001 --delete-local-data --ignore-daemonsets --force
# ノードを削除 - ポッドは別のノードで再作成されます
# ただし、kubectlでは削除できないので、 そのインスタンスまたはVMを見つけて、強制終了します。
マシンにアクセスできる場合は、電源を切るかネットワークケーブルを外します。 冗談ではありません!
以下の障害に耐えられるシステムを構築しています。
基本的に、「障害をシミュレートする」セクションで試したシナリオです。
上記のいずれかの障害が発生すると、システムは人間が手をいれなくてもオンラインになり、データも失われません。 データの永続性が保証する範囲には一応制限がありますが、 ジャーナルサイクルとアプリケーション内のトランザクションの使用状況に応じて、IRISで実現されます(https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/Doc.View.cls?KEY=GCDI_journal#GCDI_journal_writecycle)。いずれにしても、RPO(目標復旧ポイント)は2秒未満です。
システムの他のコンポーネント(Kubernetes APIサービス、etcdデータベース、ロードバランサーサービス、DNSなど)はスコープ外であり、通常、Azure AKSやAWS EKSなどのマネージドKubernetesサービスで管理されます。
別の言い方をすれば、個別の計算コンポーネントやストレージコンポーネントの障害はユーザーが処理するものであり、その他のコンポーネントの障害はインフラストラクチャ/クラウドプロバイダーが対処するものと言えます。
InterSystems IRISの高可用性について言えば、これまでミラーリングの使用が勧められてきました。 ミラーリングでは、データは、常時オンライン状態にある2つのIRISインスタンスが同期的に複製されます。 各ノードにはデータベースの完全なコピーが維持され、プライマリノードがオフラインになると、ユーザーはバックアップノードに接続し直すことができます。 基本的に、ミラーリング手法では、計算とストレージの両方の冗長性は、IRISが管理するものです。
ミラーをさまざまなアベイラビリティーゾーンにデプロイしたミラーリングにより、計算処理とストレージの障害に備えた必要な冗長性を実現し、わずか数秒という優れたRTO(目標復旧時間または障害後にシステムがオンラインに復旧するまでにかかる時間)を達成することができます。 AWSクラウドでミラーリングされたIRISのデプロイテンプレートは、https://jp.community.intersystems.com/node/486206から入手できます。
一方で、ミラーリングには、設定やバックアップ/復旧手順が複雑で、セキュリティ設定とローカルのデータベース以外のファイルの複製機能が不足しているという欠点があります。
コンテナオーケストレータ―にはKubernetesなど(今や2021年。ほかにオーケストレーターってありますか?!)がありますが、これらは、障害時に、Deploymentオブジェクトが障害のあるIRISポッド/コンテナを自動的に再起動することで、計算冗長性を実現しています。 Kubernetesアーキテクチャ図に、実行中のIRISノードが1つしかないのはこのためです。 2つ目のIRISノードを常時実行し続ける代わりに、計算可用性をKubernetesにアウトソースしています。 Kubernetesは、元のIRISポッドが何らかの理由でエラーとなった場合に、IRISポッドの再作成を確保します。
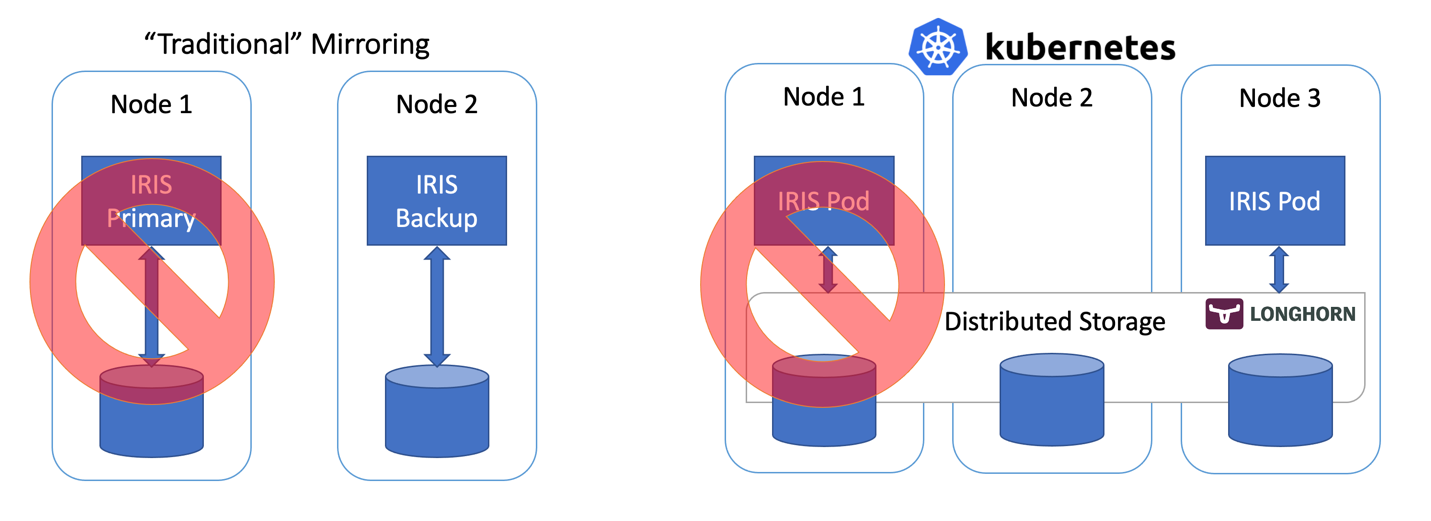
図2 フェイルオーバーのシナリオ
ここまでよろしいでしょうか。 IRISノードに障害が発生すると、Kubernetesは単に新しいノードを作成します。 クラスタによって異なりますが、計算障害が発生してからIRISがオンラインになるまでには、10~90秒かかります。 ミラーリングではわずか2秒で復旧されるわけですから、これはダウングレードとなりますが、万が一サービス停止となった場合に許容できる範囲であれば、複雑さが緩和されることは大きなメリットと言えます。 ミラーリングの構成は不要です。 セキュリティ設定やファイル複製を気にする必要もありません。
率直に言うと、KubernetesでIRISを実行し、コンテナにログインしても、高可用性環境で実行していることには気づくこともないでしょう。 単一インスタンスのIRISデプロイと全く同じように見え、何ら感触にも変化はありません。
では、ストレージはどうでしょうか。 データベースを扱っているわけですから気になります。 どのようなフェイルオーバーのシナリオであっても、システムはデータの永続性も処理する必要があります。 ミラーリングは、IRISノードのローカルである計算ノードに依存しているため、 ノードが停止するか、一時的に使用不可になってしまえば、そのノードのストレージも停止してしまいます。 ミラーリング構成では、IRISがIRISレベルでデータベースを複製するのはこれに対処するためです。
コンテナの再起動時に元の状態を維持したデータベースを使用できるだけでなく、ノードやネットワークのセグメント全体(アベイラビリティーゾーン)が停止するといったイベントに備えて、冗長性を提供できるストレージが必要です。 ほんの数年前、これを解決できる簡単な答えは存在しませんでした。 上の図から推測できるように、今ではその答えを得ています。 分散コンテナストレージです。
分散ストレージは、基盤のホストボリュームを抽象化し、k8sクラスタのすべてのノードが使用できる共同の1つのクラスターとして提示します。 この記事では、インストールが非常に簡単なLonghorn(https://longhorn.io)という無料のオープンソースのストレージを使用しますが、 OpenEBS、Porworx、StorageOSといったほかのストレージも利用できます。同じ機能が提供されています。 CNCF IncubatingプロジェクトであるRook Cephも検討する価値があるでしょう。 この種のハイエンドとしては、NetAppやPureStorageといったエンタープライズ級のストレージソリューションがあります。
「要約」セクションでは、1回にすべてをインストールしました。 インストールと検証の手順の説明は、付録Bをご覧ください。
まずは、コンテナとストレージ全般について、またIRISがどこに適合するのかについて説明しましょう。
デフォルトでは、コンテナ内のすべてのデータは揮発性であるため、 コンテナが停止すればデータは消失します。 Dockerでは、ボリュームの概念を使用することができるため、 基本的に、ホストOSのディレクトリをコンテナに公開することができます。
docker run --detach
--publish 52773:52773
--volume /data/dur:/dur
--env ISC_DATA_DIRECTORY=/dur/iconfig
--name iris21 --init intersystems/iris:2020.3.0.221.0上記の例では、IRISコンテナを起動し、host-localの「/data/dur」ディレクトリを、「/dur」マウントポイントのコンテナからアクセスできるようにしています。 つまり、コンテナがこのディレクトリに何かを格納している場合、それは保持され、コンテナの次回起動時に使用できるようになります。
IRIS側では、ISC_DATA_DIRECTORYを指定することで、IRISに、コンテナの再起動時に損失してはいけないすべてのデータを特定のディレクトリに格納するように指示することができます。 ドキュメントの「Durable SYS」というIRISの機能をご覧ください( https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_durable_running)。
Kubernetesでの構文は異なりますが、概念は同じです。
IRISの基本的なKubernetes Deploymentは以下のようになります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
上記のデプロイ仕様では、「volumes」の部分にストレージボリュームがリストされています。 このボリュームには、「iris-pvc」などのpersistentVolumeClaimを介して、コンテナの外部からアクセスできます。 volumeMountsは、このボリュームをコンテナ内に公開します。 「iris-external-sys」は、ボリュームマウントを特定のボリュームに関連付ける識別子です。 実際には複数のボリュームが存在する可能性があり、ほかのボリュームと区別するためにこの名前が使用されるわけですから、 「steve」と名付けることも可能です。
すでにお馴染みのISC_DATA_DIRECTORYは、IRISが特定のマウントポイントを使用して、コンテナの再起動後も存続する必要のあるすべてのデータを格納するように指示する環境変数です。
では、persistentVolumeClaimのiris-pvcを見てみましょう。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
かなりわかりやすいと思います。 「longhorn」ストレージクラスを使って、1つのノードでのみ読み取り/書き込みとしてマウント可能な、10ギガバイトを要求しています。
ここで重要なのは、storageClassName: longhornです。
AKSクラスタで利用できるストレージクラスを確認してみましょう。
kubectl get StorageClass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Delete Immediate true 10d
azurefile-premium kubernetes.io/azure-file Delete Immediate true 10d
default (default) kubernetes.io/azure-disk Delete Immediate true 10d
longhorn driver.longhorn.io Delete Immediate true 10d
managed-premium kubernetes.io/azure-disk Delete Immediate true 10dAzureのストレージクラスはほとんどありませんが、これらは、デフォルトでインストールされたクラスと、以下の一番最初のコマンドの一部でインストールしたLonghornのクラスです。
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml永続ボリュームクレームの定義に含まれる#storageClassName: longhornをコメントアウトすると、現在「default」としてマークされているストレージクラスが使用されます。これは、通常のAzureディスクです。
分散ストレージが必要な理由を説明するために、この記事の始めに説明した、longhornストレージを使用しない「カオスエンジニアリング」実験をもう一度行ってみましょう。 最初の2つのシナリオ(IRISの停止とポッドの削除)は正常に完了し、システムは稼働状態に回復します。 ノードをドレインまたは強制終了しようとすると、システムは障害状態になります。
#forcefully drain the node
kubectl drain aks-agentpool-71521505-vmss000001 --delete-local-data --ignore-daemonsets
kubectl describe pods
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 57s (x9 over 2m41s) default-scheduler 0/3 nodes are available: 1 node(s) were unschedulable, 2 node(s) had volume node affinity conflict.
基本的に、KubernetesはクラスタのIRISポッドを再起動しようとしますが、最初に起動されていたノードは利用できないため、ほかの2つのノードに「ボリュームノードアフィニティの競合」が発生しています。 このストレージタイプでは、基本的にボリュームはノードホストで使用可能なディスクに関連付けられているため、最初に作成されたノードでしか使用できないのです。
ストレージクラスにlonghornを使用すると、「強制ドレイン」と「ノードの強制終了」の2つの実験は正常に完了し、間もなくしてIRISポッドの動作が再開します。 これを実現するために、Longhornは3ノードクラスタをで使用可能なストレージを制御し、3つのすべてのノードにデータを複製しています。 ノードの1つが永久的に使用不可になると、Longhornは迅速にクラスタストレージを修復します。 「ノードの強制終了」シナリオでは、IRISポッドはほかの2つのボリュームレプリカを使ってすぐに別のノードで再起動されます。 するとAKSは失われたノードに置き換わる新しいノードをプロビジョニングし、準備ができたら、Longhorn がそのノードに必要なデータを再構築します。 すべては自動的に行われるため、ユーザーが手を入れる必要はありません。

図3 置換されたノードにボリュームレプリカを再構築するLonghorn
デプロイの他の側面をいくつか見てみましょう。
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
- name: ISC_CPF_MERGE_FILE
value: /external/merge/merge.cpf
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
- name: cpf-merge
mountPath: /external/merge
livenessProbe:
initialDelaySeconds: 25
periodSeconds: 10
exec:
command:
- /bin/sh
- -c
- "iris qlist iris | grep running"
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
- name: cpf-merge
configMap:
name: iris-cpf-merge
strategy: Recreateとreplicas: 1では、Kubernetesに、常にIRISポッドの1つのインスタンスのみを実行し続けることを指示しています。 これが「ポッドの削除」シナリオを処理する部分です。
livenessProbeのセクションでは、IRISが常時、コンテナ内で稼働し、「IRIS停止」シナリオを処理できるようにしています。 initialDelaySecondsは、IRISが起動するまでの猶予期間です。 IRISがデプロイを起動するのにかなりの時間が掛かっている場合は、これを増やすと良いでしょう。
IRISのCPF MERGE機能を使用すると、コンテナの起動時に、iris.cpf構成ファイルのコンテンツを変更することができます。 関連するドキュメントについては、 https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/DocBook.UI.Page.cls?KEY=RACS_cpf#RACS_cpf_edit_mergeをご覧ください。 この例では、Kubernetesの構成図を使って、マージファイルのコンテンツを管理しています( https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml)。ここでは、IRISインスタンスが使用するグローバルバッファとgmheapの値を調整していますが、iris.cpfファイルにあるものはすべて調整できます。 デフォルトのIRISパスワードでさえも、CPFマージファイルの「PasswordHash」フィールドで変更可能です。 詳細については、https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_images_password_authをご覧ください。
永続ボリュームクレーム(https://github.com/antonum/ha-iris-k8s/blob/main/iris-pvc.yaml)デプロイ(https://github.com/antonum/ha-iris-k8s/blob/main/iris-deployment.yaml)とCPFマージコンテンツを使った構成図(https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml)のほかに、デプロイには、IRISデプロイをパブリックインターネットに公開するサービスが必要です(https://github.com/antonum/ha-iris-k8s/blob/main/iris-svc.yaml)。
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.18.169 40.88.123.45 52773:31589/TCP 3d1h
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 10diris-svcの外部IPは、http://40.88.123.45:52773/csp/sys/%25CSP.Portal.Home.zenを介してIRIS管理ポータルにアクセスするために使用できます。 デフォルトのパスワードは「SYS」です。
Longhornには、ボリュームの構成と管理を行えるウェブベースのUIがあります。
kubectlを使用して、ポッドや実行中のlonghorn-uiコンポーネントを特定し、ポート転送を確立できます。
kubectl -n longhorn-system get pods
# longhorn-uiのポッドIDに注意してください。
kubectl port-forward longhorn-ui-df95bdf85-gpnjv 9000:8000 -n longhorn-system
Longhorn UIは、http://localhost:9000で利用できるようになります。

図4 LonghornのUI
Kubernetesコンテナストレージのほとんどのソリューションでは、高可用性のほか、バックアップ、スナップショット、および復元のための便利なオプションが用意されています。 詳細は実装によって異なりますが、一般的には、バックアップをVolumeSnapshotに関連付ける方法です。 この方法はLonghornでも利用できます。 使用しているKubernetesのバージョンとプロバイダーによっては、ボリュームスナップショット機能( https://github.com/kubernetes-csi/external-snapshotter)もインストールする必要があります。
そのようなボリュームショットの例には、「iris-volume-snapshot.yaml」が挙げられます。 使用する前に、バックアップを、LonghornのS3バケットまたはNFSボリュームに構成する必要があります。 https://longhorn.io/docs/1.0.1/snapshots-and-backups/backup-and-restore/set-backup-target/
# IRISボリュームのクラッシュコンシステントなバックアップを取得する
kubectl apply -f iris-volume-snapshot.yamlIRISでは、バックアップ/スナップショットを取得する前にExternal Freezeを実行し、後でThawを実行することをお勧めします。 詳細については、https://docs.intersystems.com/irisforhealthlatestj/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=Backup.General#ExternalFreezeをご覧ください。
IRISボリュームのサイズを増やすには、IRISが使用する、永続ボリュームクレーム(iris-pvc.yamlファイル)のストレージリクエストを調整します。
...
resources:
requests:
storage: 10Gi #change this value to requiredそして、pvcの仕様を再適用します。 Longhornは、実行中のポッドにボリュームが接続されている場合、この変更を実際に適用することはできません。 そのため、ボリュームサイズが増えるように、デプロイでレプリカ数を一時的にゼロに変更します。
この記事の冒頭で、高可用性の基準を設定しました。 このアーキテクチャでは、次のようにそれを実現します。
障害の領域 | 自動的に緩和処置を行う機能 |
コンテナ/VM内のIRISインスタンス。 IRIS - レベル障害 | IRISが機能停止となった場合、デプロイのLiveness Probeによってコンテナが再起動されます。 |
ポッド/コンテナの障害 | デプロイによってポッドが再作成されます。 |
個々のクラスタノードの一時的な使用不能。 アベイラビリティーゾーンがオフラインになる場合などが挙げられます。 | デプロイによって別のノードにポッドが再作成されます。 Longhornによって、別のノードでデータが使用できるようになります。 |
個々のクラスタノードまたはディスクの永久的障害。 | 上記と同様かつ、k8sクラスタオートスケーラーによって、破損したノードが新しいノードに置き換えられます。 Longhornによって、新しいノードにデータが再構築されます。 |
DockerコンテナでのIRISの実行を理解している方であれば、「--init」フラグを使用したことがあるでしょう。
docker run --rm -p 52773:52773 --init store/intersystems/iris-community:2020.4.0.524.0このフラグは、「ゾンビプロセス」の形成を防止することを目的としています。 Kubernetesでは、「shareProcessNamespace: true」を使用する(セキュリティの考慮事項が適用されます)か、コンテナで「tini」を使用することができます。 以下に、tiniを使用したDockerfileの例を示します。
FROM iris-community:2020.4.0.524.0
...
# Tiniを追加します
USER root
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
USER irisowner
ENTRYPOINT ["/tini", "--", "/iris-main"]2021年以降、すべてのInterSystemsが提供するコンテナイメージには、デフォルトでtiniが含まれています。
いくつかのパラメーターを調整することで、「ノードの強制ドレイン/ノードの強制終了」シナリオのフェイルオーバー時間をさらに短縮することができます。
Longhornのポッド削除ポリシー(https://longhorn.io/docs/1.1.0/references/settings/#pod-deletion-policy-when-node-is-down)およびkubernetes taintベースのエビクション機能(https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/#taint-based-evictions)をご覧ください。
InterSystemsに勤務する者として、この内容を記載しておく必要があります。この記事では、分散型Kubernetesブロックストレージの一例としてLonghornを使用しています。 InterSystemsは、個々のストレージソリューションや製品を検証ないしは公式なサポート声明を発行していません。 特定のストレージソリューションがニーズに適合しているかどうかは、ユーザー自身がテストして検証する必要があります。
分散ストレージには、ノードローカルストレージとは大きく異なるパフォーマンス特性も備わっています。 特に書き込み操作の場合、データが永続化された状態とみなされるには、データを複数の場所に書き込む必要があります。 必ずワークロードをテストし、CSIドライバが提供する特定の動作とオプションを理解するようにしてください。
InterSystemsでは基本的に、Longhornなどの特定のストレージjソリューションを検証あるいは承認していません。これは、個々のHDDブランドやサーバーハードウェアメーカーを検証しないのと同じです。 個人的には、Longhornは扱いやすいと感じています。プロジェクトのGitHubページ(https://github.com/longhorn/longhorn)では、その開発チームは積極的に応答し、よく助けていただいています。
Kubernetesエコシステムは、過去数年間で大きな進化を遂げました。今日では、分散ブロックストレージソリューションを使用することで、IRISインスタンスやクラスタノード、さらにはアベイラビリティーゾーンの障害を維持できる高可用性構成を構築できるようにもなっています。
計算とストレージの高可用性をKubernetesコンポーネントにアウトソースできるため、従来のIRISミラーリングに比べ、システムの構成と管理が大幅に単純化しています。 ただしこの構成では、ミラーリング構成ほどのRTOとストレージレベルのパフォーマンスは得られないことがあります。
この記事では、Azure AKSをマネージドKubernetesとLonghorn分散ストレージシステムとして使用し、可用性の高いIRIS構成を構築しました。 ほかにも、AWS EKS、マネージドK8s向けのGoogle Kubernetes Engine、StorageOS、Portworx、OpenEBSなどの様々な分散コンテナストレージを探ってみると良いでしょう。エンタープライズ級のストレージソリューションには、NetApp、PureStorage、Dell EMCなどもあります。
パブリッククラウドプロバイダーが提供するマネージドKubernetesサービスを使うと、このセットアップに必要なk8sクラスタを簡単に作成できます。 この記事で説明したデプロイには、AzureのAKSデフォルト構成をそのまますぐに使用することができます。
3ノードで新しいAKSクラスタを作成します。 それ以外はすべてデフォルトのままにします。

図5 AKSクラスタの作成
ローカルコンピュータにkubectlをインストールします。https://kubernetes.io/docs/tasks/tools/install-kubectl/
ローカルkubectlにASKクラスタを登録します。

図6 kubectlにAKSクラスタを登録
登録が済んだら、この記事の最初に戻って、longhornとIRISデプロイをインストールします。
AWS EKSでのインストールは、もう少し複雑です。 ノードグループのすべてのインスタンスにopen-iscsiがインストトールされていることを確認する必要があります。
sudo yum install iscsi-initiator-utils -yGKEでのLonghornのインストールには追加の手順があります。https://longhorn.io/docs/1.0.1/advanced-resources/os-distro-specific/csi-on-gke/をご覧ください。
付録B: インストール手順
手順1 - Kubernetesクラスタとkubectl
3ノードk8sクラスタが必要です。 Azureでのクラスタの構成方法は付録Aをご覧ください。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-29845772-vmss000000 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000001 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000002 Ready agent 10d v1.18.10手順2 - Longhornをインストールする
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml「longhorn-system」ネームスペースのすべてのポッドが実行状態であることを確認してください。 これには数分かかる場合があります。
$ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-74db7cf6d9-jgdxq 1/1 Running 0 10d
csi-attacher-74db7cf6d9-l99fs 1/1 Running 1 11d
...
longhorn-manager-flljf 1/1 Running 2 11d
longhorn-manager-x76n2 1/1 Running 1 11d
longhorn-ui-df95bdf85-gpnjv 1/1 Running 0 11d詳細とトラブルシューティングについては、Longhornインストールガイド(https://longhorn.io/docs/1.1.0/deploy/install/install-with-kubectl)をご覧ください。
手順3 - GitHubリポジトリのクローンを作成する
$ git clone https://github.com/antonum/ha-iris-k8s.git
$ cd ha-iris-k8s
$ ls
LICENSE iris-deployment.yaml iris-volume-snapshot.yaml
README.md iris-pvc.yaml longhorn-aws-secret.yaml
iris-cpf-merge.yaml iris-svc.yaml tldr.yaml手順4 - コンポーネントを1つずつデプロイして検証する
tldr.yamlファイルには、デプロイに必要なすべてのコンポーンネントが1つのバンドルとして含まれています。 ここでは、コンポーネントを1つずつインストールし、それぞれのセットアップを個別に検証します。
# 以前にtldr.yamlを適用したことがある場合は、削除します。
$ kubectl delete -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
永続ボリュームクレームを作成します
$ kubectl apply -f iris-pvc.yaml
persistentvolumeclaim/iris-pvc created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
iris-pvc Bound pvc-fbfaf5cf-7a75-4073-862e-09f8fd190e49 10Gi RWO longhorn 10s
構成図を作成します
$ kubectl apply -f iris-cpf-merge.yaml
$ kubectl describe cm iris-cpf-merge
Name: iris-cpf-merge
Namespace: default
Labels: <none>
Annotations: <none>
Data
merge.cpf:
[config]
globals=0,0,800,0,0,0
gmheap=256000
Events: <none>
irisデプロイを作成します
$ kubectl apply -f iris-deployment.yaml
deployment.apps/iris created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
iris-65dcfd9f97-v2rwn 0/1 ContainerCreating 0 11s
ポッド名を書き留めます。 この名前は、次のコマンドでポッドに接続する際に使用します。
$ kubectl exec -it iris-65dcfd9f97-v2rwn -- bash
irisowner@iris-65dcfd9f97-v2rwn:~$ iris session iris
Node: iris-65dcfd9f97-v2rwn, Instance: IRIS
USER>w $zv
IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2020.4 (Build 524U) Thu Oct 22 2020 13:04:25 EDT
h<enter>でIRISシェルを終了
exit<enter>でポッドを終了
IRISコンテナのログにアクセスします
$ kubectl logs iris-65dcfd9f97-v2rwn
...
[INFO] ...started InterSystems IRIS instance IRIS
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Private webserver started on 52773
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Processing Shadows section (this system as shadow)
01/18/21-23:09:11:321 (1173) 0 [Utility.Event] Processing Monitor section
01/18/21-23:09:11:381 (1323) 0 [Utility.Event] Starting TASKMGR
01/18/21-23:09:11:392 (1324) 0 [Utility.Event] [SYSTEM MONITOR] System Monitor started in %SYS
01/18/21-23:09:11:399 (1173) 0 [Utility.Event] Shard license: 0
01/18/21-23:09:11:778 (1162) 0 [Database.SparseDBExpansion] Expanding capacity of sparse database /external/iris/mgr/iristemp/ by 10 MB.
irisサービスを作成します
$ kubectl apply -f iris-svc.yaml
service/iris-svc created
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.214.236 20.62.241.89 52773:30128/TCP 15s
手順5 - 管理ポータルにアクセスする
最後に、サービスの外部IP(http://20.62.241.89:52773/csp/sys/%25CSP.Portal.Home.zen)を使って、IRISの管理ポータルに接続します。ユーザー名は「_SYSTEM」、パスワードは「SYS」です。 初回ログイン時にパスワードの変更が求められます。

これは InterSystems FAQ サイトの記事です。
※ ここで説明するバックアップ方法は、外部バックアップ(##class(Backup.General).ExternalFreeze()を使用する方法)ではご利用いただけません。
その1(差分)
毎週日曜日1時にフルバックアップ、月曜日~土曜日の1時に差分バックアップを取得しているとします。
差分バックアップは、前日の1時に取得したバックアップからの更新ブロックが含まれるバックアップです。
その2(累積)
毎週日曜日1時にフルバックアップ、月~火曜日の1時に差分バックアップ、水曜日1時に累積バックアップ、木~土曜日の1時に差分バックアップを取得するとします。
累積バックアップは、前回のフルバックアップからの更新ブロックが含まれるバックアップで、水曜日に累積バックアップを取得した場合、月曜日と火曜日の差分バックアップは水曜日に累積バックアップに含まれるため、累積バックアップ成功後、月曜日と火曜日に差分バックアップは破棄できます。
オンラインバックアップ詳細については「データベースのバックアップ方法について」や、下記ドキュメントをご参照ください。
これは、InterSystems FAQサイトの記事です。
以下に当てはまる場合、差分バックアップではなくフルバックアップが取られます。
・リストの中に1つでもフルバックアップを取っていないデータベース(DB)が含まれるとき
・リストの中に読み込み専用のDBが含まれるとき
→読込専用DBはバックアップが取れないため、対象リストのDBは毎回フルバックアップが取られます
ReadOnlyマウントしたDBをバックアップしようとすると、以下のようなログが出力されます。
WARNING - the following directories could not be backed up c:\intersystems\ensemble\mgr\xxx\ (Database is readonly)
読込専用DBはバックアップリストから除く必要があります。
もし、読込専用DBをバックアップする場合は、別途バックアップする必要があります。
これはInterSystems FAQ サイトの記事です。
バックアップには、以下4種類の方法があります。
詳細は、以下ドキュメントをご参照ください。
バックアップの方法について【IRIS】
バックアップの方法について
1、2、4は、インスタンスを停止せずにバックアップが行えます(末尾の関連情報もご参照ください)。3 は、インスタンスを停止した後でバックアップを行う方法です。
またシステム構成や障害バターンを基にバックアップを設計、計画する上での注意点、自動化のサンプルやバックアップを実施する上で役立つ各種関連技術についてはInterSystems Symposia 2014 発表資料 をご参照ください(※1)。
※1:InterSystems Symposia 2014でご紹介した内容で、Cachéと記載がありますがバックアップ方法についてはIRISも同様です。
【関連情報】(コミュニティ/FAQトピックをリンクしています)
これはInterSystems FAQ サイトの記事です。
システムルーチン ^DBSIZE を利用するとバックアップファイルサイズを見積もることができます(メモ1もご参照ください)。
^DBSIZE は、データベース・バックアップ・リストに選択されたデータベースを対象に、フルバックアップ/累積バックアップ/差分バックアップそれぞれのファイルサイズを見積もります。
なお、データベース・バックアップ・リストは、管理ポータルの [システム管理] > [構成] > [データベースバックアップ] > [データベース・バックアップ・リスト] から作成します。
詳細については、下記ドキュメントもご参照ください。
^DBSIZEによるバックアップ・サイズの見積もり【IRIS】
実行例は、以下の通りです。
データベースシステムには非常に特殊なバックアップ要件があり、企業のデプロイメントでは、事前の検討と計画が必要です。 データベースシステムの場合、バックアップソリューションの運用上の目標は、アプリケーションが正常にシャットダウンされた時と同じ状態で、データのコピーを作成することにあります。 アプリケーションの整合性バックアップはこれらの要件を満たし、Cachéは、このレベルのバックアップ整合性を達成するために、外部ソリューションとの統合を容易にする一連のAPIを提供しています。
これらのAPIは**ExternalFreezeとExternalThaw**です。 _ExternalFreeze_は一時的にディスクへの書き込みを停止し、この期間にCaché はメモリ内の変更をコミットします。 この期間にバックアップ操作を完了させ、_ExternalThaw_の呼び出しを行う必要があります。 この呼び出しによって、書き込みのデーモンがグローバルバッファプール(データべースキャッシュ)で更新されたキャッシュをディスクに書き込むと、通常のCachéデータベースの書き込みデーモン操作が再開します。 このプロセスはCachéのユーザープロセスに対して透過的に行われます。 具体的なAPIクラスメソッドは次のとおりです。
##Class(Backup.General).ExternalFreeze()
##Class(Backup.General).ExternalThaw()
これらのAPIは、スナップショット操作のプリスクリプトとポストスクリプトを実行するAzure Backupの新機能と合わせて、Azure上のCachéのデプロイメントに対する包括的なバックアップソリューションを提供しています。 Azure Backupのプリスクリプトとポストスクリプト機能は現在、Linux VMでのみ利用できます。
Azure Backupを使用してVMをバックアップする前に、おおまかに3つのステップを実行する必要があります。
Recovery Servicesコンテナーは、バックアップの目標、ポリシー、および保護する項目を管理します。 Recovery Servicesコンテナーの作成は、Azure PortalまたはPowerShellを使ったスクリプトによって行います。 Azure BackupにはVMで実行する拡張機能が必要であり、Linux VMエージェントによって管理されています。また、最新バージョンのエージェントも必要です。 拡張機能はAzure StorageとRecovery Servicesコンテナーの外向きのHTTPSエンドポイントと対話します。 VMからこれらのサービスへのセキュアアクセスは、Azure Network Security Groupのプロキシとネットワークルールを使用して構成できます。
上記のステップに関する詳細は、「Prepare your environment to back up Resource Manager-deployed virtual machines」を参照してください。
バックアップ操作の前と後にスクリプトを呼び出す機能は、Azure Backup Extension(Microsoft.Azure.RecoveryServices.VMSnapshotLinux)の最新バージョンに含まれています。 この拡張機能のインストール方法については、機能に関する詳細なドキュメントを確認してください。
デフォルトでは、拡張機能には、Linux VMの次の場所に、サンプルのプリスクリプトとポストスクリプトが含まれます。
/var/lib/waagent/Microsoft.Azure.RecoveryServices.VMSnapshotLinux-1.0.9110.0/main/tempPlugin
そして、スクリプトをそれぞれ次の場所にコピーする必要があります。
/etc/azure/prescript.sh /etc/azure/postScript.sh
スクリプトテンプレートは、GitHubからもダウンロード可能です。
Cachéでは、ExternalFreeze APIを呼び出すprescript.shスクリプトを実装でき、postScript.shにはExternalThawを実行するコードが含まれている必要があります。
以下は、Cachéのprescript.shの実装例です。
#!/bin/bash # variables used for returning the status of the script success=0 error=1 warning=2 status=$success log_path="/etc/preScript.log"#path of log file printf "Logs:\n" > $log_path# TODO: Replace <CACHE INSTANCE> with the name of the running instance csession <CACHE INSTANCE> -U%SYS "##Class(Backup.General).ExternalFreeze()" >> $log_path status=$?if [ $status -eq 5 ]; then echo "SYSTEM IS FROZEN" printf "SYSTEM IS FROZEN\n" >> $log_pathelif [ $status -eq 3 ]; then echo "SYSTEM FREEZE FAILED" printf "SYSTEM FREEZE FAILED\n" >> $log_path status=$error csession <CACHE INSTANCE> -U%SYS "##Class(Backup.General).ExternalThaw()" fi exit $status
以下は、CachéのpostScript.shの実装例です。
#!/bin/bash # variables used for returning the status of the script success=0 error=1 warning=2 status=$success log_path="/etc/postScript.log"#path of log file printf "Logs:\n" > $log_path# TODO: Replace <CACHE INSTANCE> with the name of the running instance csession <CACHE INSTANCE> -U%SYS "##class(Backup.General).ExternalThaw()" status=$? if [ $status req 5]; then echo "SYSTEM IS UNFROZEN" printf "SYSTEM IS UNFROZEN\n" >> $log_pathelif [ $status -eq 3 ]; then echo "SYSTEM UNFREEZE FAILED" printf "SYSTEM UNFREEZE FAILED\n" >> $log_path status=$error fi exit $status
Azureポータルで、Recoveryサービスに移動して、最初のバックアップをトリガできます。 初回バックアップまたは後続のバックアップに関係なく、VMスナップショットの時間は数秒であることに注意してください。 最初のバックアップのデータ転送には時間がかかりますが、データ転送は、データベースのフリーズを解除するポストスクリプトの実行後に開始されるため、プリスクリプトとポストスクリプト間の時間に影響を与えることはありません。
データ保護操作が有効であることを確認するには、定期的に非本番環境にバックアップを復元してデータベースの整合性チェックを実行することを強くお勧めします。
バックアップのトリガ方法、およびバックアップスケジュールなどの関連トピックについては、「Back up Azure virtual machines to a Recovery Services vault」を参照してください。
この記事では、スナップショットを使用したソリューションとの統合の例を使って、_外部バックアップ_による Caché のバックアップ方法を紹介します。 このところ私が目にするソリューションの大半は、Linux の VMware にデプロイされているため、この記事の大半では、例として、ソリューションが VMware スナップショットテクノロジーをどのように統合しているかを説明しています。
Caché をインストールすると、Caché データベースを中断せずにバックアップできる Caché オンラインバックアップが含まれています。 しかし、システムがスケールアップするにつれ、より効率的なバックアップソリューションを検討する必要があります。 Caché データベースを含み、システムをバックアップするには、スナップショットテクノロジーに統合された_外部バックアップ_をお勧めします。
詳しい内容は外部バックアップのオンラインドキュメンテーションに説明されていますが、 主な考慮事項は次のとおりです。
「スナップショットの整合性を確保するために、スナップショットが作成される間、Caché はデータベースへの書き込みをfreezeする方法を提供しています。 スナップショットの作成中は、データベースファイルへの物理的な書き込みのみがfreezeされるため、ユーザーは中断されることなくメモリ内で更新を実行し続けることができます。」
また、仮想化されたシステム上でのスナップショットプロセスの一部によって、バックアップされている VM にスタンタイムと呼ばれる短い無応答状態が発生することにも注意してください。 通常は 1 秒未満であるため、ユーザーが気付いたり、システムの動作に影響を与えたりすることはありませんが、状況によってはこの無応答状態が長引くことがあります。 無応答状態が Caché データベースミラーリングの QoS タイムアウトより長引く場合、バックアップノードはプライマリに障害が発生したとみなし、フェイルオーバーします。 この記事の後の方で、ミラーリング QoS タイムアウトを変更する必要がある場合に、スタンタイムをどのように確認できるかについて説明します。
この記事では、Caché オンラインドキュメンテーション『Backup and Restore Guide(バックアップと復元ガイド)』も確認する必要があります。
ほかのソリューションがない場合は、ダウンタイム無しでバックアップを行えるこのソリューションが InterSystems データプラットフォームに同梱されています。 _Caché オンラインバックアップ_は、Caché データベースファイルのみをバックアップするもので、データに割り当てられたデータベースのすべてのブロックをキャプチャし、出力をシーケンシャルファイルに書き込みます。 Caché Online Backup は累積バックアップと増分バックアップをサポートしています。
VMware の文脈では、Caché Online Backup はゲスト内で発生するバックアップソリューションです。 ほかのゲスト内ソリューションと同様に、Caché Online Backup の動作は、アプリケーションが仮想化されていようが、ホストで直接実行していようが、基本的に変わりません。 Caché Online Backup は、システムバックアップと連携しながら Caché のオンラインバックアップ出力ファイルを、アプリケーションが使用しているその他すべてのファイルシステムとともに、バックアップメディアにコピーします。 最小限のシステムバックアップには、インストールディレクトリ、ジャーナルおよび代替ジャーナルディレクトリ、アプリケーションファイル、およびアプリケーションが使用する外部ファイルを含むすべてのディレクトリを含める必要があります。
Caché Online Backup は、Caché データベースやアドホックバックアップのみをバックアップする低コストのソリューションを実装したいと考えている小規模サイト向けのエントリレベルのアプローチとして捉えてください。ミラーリングをセットアップする際のバックアップなどに役立てられます。 しかし、データベースのサイズが増加したり、Caché が顧客のデータランドスケープの一部でしかない場合は、_外部バックアップ_にスナップショットテクノロジーとサードパーティ製ユーティリティを合わせたソリューションがベストプラクティスとして推奨されます。非データベースファイルのバックアップ、より高速な復旧時間、エンタープライズ全体のデータビュー、より優れたカタログと管理用ツールなど、さまざまなメリットが得られます。
VMware を例として使用します。VMware で仮想化すると、VM 全体を保護するための追加機能と選択肢が追加されます。 ソリューションの仮想化が完了した時点で、オペレーティングシステム、アプリケーション、データを含むシステムを .vmdk(とその他の)ファイル内に効果的にカプセル化したことになります。 これらのファイルの管理は非常に簡単で、必要となった場合にはシステム全体の復旧に使用できるため、オペレーティングシステム、ドライバ、サードパーティ製アプリケーション、データベースとデータベースファイルなどのコンポーネントを個別に復旧して構成する必要のある物理システムで同じような状況が発生した場合とは大きく異なります。
VMware の vSphere Data Protection(VDP)や、Veeam や Commvault などのサードパーティ製バックアップソリューションでは、VMware 仮想マシンスナップショットを使用してバックアップを作成しています。 VMware スナップショットの概要を説明しますが、詳細については、VMware ドキュメンテーションを参照してください。
スナップショットは VM 全体に適用されるものであり、オペレーティングシステムとすべてのアプリケーションまたはデータベースエンジンはスナップショットが発生していることを認識しないということに注意してください。 また、次のことにも注意してください。
VMware スナップショット自体はバックアップではありません!
スナップショットは、バックアップソフトウェアによるバックアップの作成を_可能にします_が、スナップショット自体はバックアップではありません。
VDP とサードパーティ製バックアップソリューションは、バックアップアプリケーションとともに VMware スナップショットプロセスを使用して、スナップショットの作成と、非常に重要となるその削除を管理します。 おおまかに見ると、VMware スナップショットを使用した外部バックアップのイベントのプロセスと順序は次のとおりです。
バックアップソリューションは、変更ブロック追跡(CBT)などのほかの機能も使用し、増分または累積バックアップを可能にして速度と効率性(容量節約において特に重要)を実現します。また、一般的に、データの重複解除や圧縮、スケジューリング、整合性チェックなどで IP アドレスが更新された VM のマウント、VM とファイルレベルの完全復元、およびカタログ管理などの重要な機能性も追加します。
適切に管理されていない、または長期間実行されたままの VMware スナップショットは、ストレージを過剰に消費し(データの変更量が増えるにつれ、差分ファイルが増加し続けるため)、VM の速度を低下させてしまう可能性があります。
本番インスタンスで手動スナップショットを実行する前に、十分に検討する必要があります。 なぜ実行しようとしているのか、 スナップショットが作成された時間に戻すとどうなるか、 作成とロールバック間のすべてのアプリケーショントランザクションはどうなるか、といったことを検討してください。
バックアップソフトウェアがスナップショットを作成し、削除しても問題ありません。 スナップショットの存続期間は、短期間であるものなのです。 また、バックアップ戦略においては、ユーザーやパフォーマンスへの影響をさらに最小限に抑えられるように、システムの使用率が低い時間を選ぶことも重要です。
スナップショットを作成する前に、保留中のすべての書き込みがコミットされ、データベースが一貫した状態になるように データベースを静止させる必要があります。 Caché は、スナップショットが作成される間、データベースへの書き込みをコミットして短時間フリーズ(停止)するメソッドと API を提供しています。 こうすることで、スナップショットの作成中は、データベースファイルへの物理的な書き込みのみがフリーズされるため、ユーザーは中断されることなくメモリ内で更新を実行し続けることができます。 スナップショットがトリガーされると、データベースの書き込みが再開し、バックアップはバックアップメディアへのデータのコピーを続行します。 フリーズからの復旧は、非常に短時間(数秒)で発生します。
書き込みを一時停止するのに加え、Caché Freeze は、ジャーナルファイルの切り替えとジャーナルへのバックアップマーカーの書き込みも処理します。 ジャーナルファイルは、物理データベースの書き込みがフリーズしている間、通常通りに書き込みを続けます。 物理データベースの書き込みがフリーズしている間にシステムがクラッシュした場合、データは、起動時に、通常通りジャーナルから復元されます。
以下の図は、整合性のあるデータベースイメージを使用してバックアップを作成するための、VMware スナップショットを使用した Freeze と Thaw の手順を示しています。
Freeze から Thaw の時間が短いところに注目してください。読み取り専用の親をバックアップターゲットにコピーする時間でなく、スナップショットを作成する時間のみです。
vSphere では、スナップショット作成のいずれか側で自動的にスクリプトを呼び出すことができ、この時に、Caché Freeze と Thaw が呼び出されます。 注意: この機能が正しく機能するために、ESXi ホストは _VMware ツール_を介してゲストオペレーティングシステムにディスクを静止するように要求します。
VMware ツールは、ゲストオペレーティングシステムにインストールされている必要があります。
スクリプトは、厳密な命名規則と場所のルールに準じる必要があります。 ファイルの権限も設定されていなければなりません。 以下は、Linux の VMware の場合のスクリプト名です。
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-script
以下は、InterSystems のチームが内部テストラボインスタンスに対して、Veeam バックアップで使用する Freeze と Thaw のスクリプト例ですが、ほかのソリューションでも動作するはずです。 これらの例は、vSphere 6 と Red Hat 7 で検証され、使用されています。
これらのスクリプトは例として使用でき、方法を示すものではありますが、各自の環境で必ず検証してください!
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Only for running instances
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
csession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Only for running instances
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Thaw
csession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
csession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
スクリプトが正しく動作することをテストするには、VM でスナップショットを手動で実行し、スクリプトの出力を確認することができます。 以下のスクリーンショットは、[Take VM Snapshot(VM スナップショットの作成)]ダイアログとオプションを示します。

選択解除- [Snapshot the virtual machine's memory(仮想マシンのメモリをスナップショットする)]
選択 - [Quiesce guest file system (Needs VMware Tools installed)(ゲストファイルシステムを静止する: VMware ツールのインストールが必要)]チェックボックス。スナップショットを作成する際にゲストオペレーティングシステムで実行中のプロセスを一時停止し、ファイルシステムのコンテンツが既知の整合性のある状態を保つようにします。
重要! テストの後、スナップショットを必ず削除してください!!!!
スナップショットが作成される際に、静止フラグが真であり、仮想マシンがオンである場合、VMware ツールによって仮想マシンのファイルシステムが静止されます。 ファイルシステムの静止は、ディスク上のデータをバックアップに適した状態にするプロセスです。 このプロセスには、オペレーティングシステムのメモリ内キャッシュからディスクへのダーティバッファのフラッシュといった操作が含まれる場合があります。
以下の出力は、操作の一環としてスナップショットを含むバックアップを実行した後に、上記の Freeze/Thaw スクリプトの例で設定された $SNAPSHOT ログファイルのコンテンツを示しています。
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finished
この例では、Freeze から Thaw までに 6 秒経過していることがわかります(16:30:36~16:30:42)。 この間、ユーザー操作は中断されていません。 _独自のシステムからメトリックを収集する必要があります_が、背景としては、この例は、IO ボトルネックがなく、平均 200 万 Glorefs/秒、17 万 Gloupds/秒、および毎秒あたり平均 1,100 個の物理読み取りと書き込みデーモン 1 サイクル当たりの書き込み 3,000 個の BM でアプリケーションベンチマークを実行しているシステムから得たものです。
メモリはスナップショットの一部ではないため、再起動すると、VM は再起動して復元されることに注意してください。 データベースファイルは整合性のある状態です。 バックアップを「再開」するのではなく、ファイルを既知の時点の状態にする必要があります。 その後で、ファイルが復元されたら、ジャーナルと、アプリケーションとトランザクションの整合性に必要なその他の復元手順をロールフォワードできます。
その他のデータ保護を追加するには、ジャーナルの切り替えを単独で実行することもでき、ジャーナルは、たとえば 1 時間ごとに別の場所にバックアップまたは複製されます。
以下は、上記の Freeze と Thaw スクリプトの $LOGFILE の出力で、スナップショットのジャーナルの詳細を示しています。
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumed
VM スナップショットの作成時、バックアップが完了してスナップショットがコミットされた後、VM を短時間フリーズする必要があります。 この短時間のフリーズは、VM のスタンと呼ばれることがよくあります。 スタンタイムについてよく説明されたブログ記事は、こちらをご覧ください。 以下に要約した内容を示し、Caché データベースの考慮事項に照らして説明します。
スタンタイムに関する記事より: 「VM スナップショットを作成するには、(i)デバイスの状態をディスクにシリアル化し、(ii)現在実行中のディスクを閉じてスナップショットポイントを作成するために、VM は「スタン」されます(無応答状態になります)。… 統合時、VM は、ディスクを閉じて統合に最適な状態にするために、「スタン」されます。」
スタンタイムは、通常数百ミリ秒です。ただし、コミットフェーズ中にディスクの書き込みアクティビティが非常に高い場合には、スタンタイムが数秒に長引くことがあります。
VM が、Caché データベースミラーリングに参加するプライマリまたはバックアップメンバーであり、スタンタイムがミラーのサービス品質(QoS)タイムアウトより長引く場合、ミラーはプライマリ VM に失敗としてレポートし、ミラーのテイクオーバーを開始します。
2018 年 3 月更新: 同僚の Pter Greskoff から指摘されました。バックアップミラーメンバーは、VM スタン中またはプライマリミラーメンバーが利用不可である場合には、QoS タイムアウトの半分超という短時間でフェイルオーバーを開始することがあります。
QoS の考慮事項とフェイルオーバーのシナリオの詳細については、「Quality of Service Timeout Guide for Mirroring(ミラーリングのサービス品質タイムアウトに関するガイド)」という素晴らしい記事を参照できますが、以下に、VM スタンタイムと QoS に関する要約を示します。
バックアップミラーが、QoS タイムアウトの半分の時間内にプライマリミラーからメッセージを受信しない場合、ミラーはプライマリが動作しているかどうかを確認するメッセージを送信します。 それからバックアップはさらに QoS タイムアウトの半分の時間、プライマリマシンからの応答を待機します。 プライマリからの応答がない場合、プライマリは停止しているとみなされ、バックアップがテイクオーバーします。
ビジー状態のシステムでは、プライマリからバックアップミラーにジャーナルが継続的に送信されるため、バックアップはプライマリが動作しているかどうかを確認する必要はありません。 ただし、バックアップが発生している可能性が高い静止時間中、アプリケーションがアイドル状態である場合、QoS タイムアウトの半分以上の時間、プライマリとバックアップミラーの間でメッセージのやり取りがない可能性があります。
これは Peter が提示した例ですが、このタイムフレームを、QoS タイムアウトが :08 秒で VM スタンタイムが :07 秒のアイドル状態にあるシステムで考えてみましょう。
上記のリンク先の記事にある「Pitfalls and Concerns when Configuring your Quality of Service Timeout(サービス品質タイムアウトを構成する際の落とし穴と考慮事項)」のセクションもお読みください。QoS を必要な期間だけ確保する際のバランスが説明されています。 QoS が長すぎる場合、特に 30 秒を超える場合も問題を引き起こす可能性があります。
2018 年 3 月更新の終了:
ミラーリングの QoS の詳細については、ドキュメンテーションを参照してください。
スタンタイムを最小限に抑える戦略には、データベースアクティビティが低い場合にバックアップを実行することと、ストレージを十分にセットアップすることが挙げられます。
上記で述べたように、スナップショットの作成時に指定できるオプションがいくつかあります。その 1 つは、スナップショットにメモリ状態を含めることです。_Caché データベースのバックアップにはメモリ状態は不要である_ことに注意してください。 メモリフラグが設定されている場合、仮想マシンの内部状態のダンプがスナップショットに含められます。 メモリスナップショットの作成には、もっと長い時間がかかります。 メモリスナップショットは、実行中の仮想マシンの状態を、スナップショットが作成された時の状態に戻すために使用されます。 これは、データベースファイルのバックアップには必要ありません。
メモリスナップショットを作成する場合、仮想マシンの状態全体が停止しますが、スタンタイムはさまざまです。
前述のとおり、バックアップでは、整合性のある使用可能なバックアップを保証するために、手動スナップショットで、またはバックアップソフトウェアによって、静止フラグを true に設定する必要があります。
ESXi 5.0 より、スナップショットのスタンタイムは、以下のようなメッセージで仮想マシンのログファイル(vmware.log)に記録されます。
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
スタンタイムはミリ秒単位であるため、上記の例にある 38123 us は 38123/1,000,000 秒または 0.038 秒となります。
スタンタイムが許容範囲内であることを確認するため、またはスタンタイムが長引くせいで問題が発生していると思われる場合にトラブルシューティングを実施するため、関心のある VM のフォルダから vmware.log ファイルをダウンロードして確認することができます。 ダウンロードしたら、以下の Linux コマンドの例を使うなどして、ログを抽出しソートできます。
vSphere 管理コンソールまたは ESXi ホストコマンドラインから VMware サポートバンドルを作成するなど、サポートログのダウンロードにはいくつかの方法があります。 全詳細については VMware ドキュメンテーションを参照できますが、以下は、スタンタイムを確認できるように、vmware.log ファイルを含む非常に小さなサポートバンドルを作成して収集する簡単な方法です。
VM ファイルが配置されているディレクトリの正式な名称が必要となります。 ssh を使用してデータベース VM が実行している ESXi ホストにログオンし、コマンド vim-cmd vmsvc/getallvms を使用して vmx ファイルとそれに関連付けられた一意の正式名称を一覧表示します。
たとえば、この記事で使用されているデータベース VM の正式な名称は次のように出力されます。 26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11
次に、ログファイルのみを収集してバンドルするコマンドを実行します。vm-support -a VirtualMachines:logs
コマンドによって、以下の例のように、サポートバンドルの場所が表示されます。 To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'.
これで、sftp を使用してファイルをホストから転送し、さらに処理して確認できるようになりました。
この例では、サポートバンドルを解凍した後に、データベース VM の正式名称に対応するパスに移動します。 この場合は、 <bundle name>/vmfs/volumes/<host long name>/e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0 というパスになります。
そこで番号付きの複数のログファイルが表示されます。最新のログファイルには番号は付きません。つまり、vmware.log と示されます。 ログはわずか数百 KB ですが、たくさんの情報が記載されています。ただし、注目するのは stun/unstun の時間のみで、grep を使うと簡単に見つけ出すことができます。 次は、その記載例です。
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 us
この例では、2つのグループのスタンタイムを確認できます。1 つはスナップショップ作成時、そしてもう 1 つは、各ディスクのスナップショットが削除/統合された 45 分後(バックアップソフトウェアが読み取り専用 vmx ファイルのコピーを完了したとき)のものです。 上記の例では、最初のスタンタイムは 1 秒をわずかに上回っていますが、ほとんどのスタンタイムは 1 秒未満であることがわかります。
短時間のスタンタイムは、エンドユーザーが気付くものではありませんが、 Caché データベースミラーリングなどのシステムプロセスは、インスタンスが「アライブ」であるかどうかを継続的に監視しています。 スタンタイムがミラーリング QoS タイムアウトを超える場合、ノードは接続不可能であり「停止」状態とみなされ、フェイルオーバーがトリガーされます。
ヒント: すべてのログを確認するか、トラブルシューティングを実行する場合には、grep コマンドが役立ちます。すべての vmware*.log ファイルに対して grep を使用し、異常値、またはスタンタイムが QoS タイムアウトに達しているインスタンスを探してください。 以下のコマンドは、出力をパイプ処理し、awk で書式設定しています。
grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nr
通常稼働時に定期的にシステムを監視し、スタンタイムと、ミラーリングなどの HA 向けの QoS タイムアウトへの影響を理解しておく必要があります。 前述のとおり、スタンタイムまたはスタン解除タイムを最小限に抑える戦略には、データベースとストレージのアクティビティが低い場合にバックアップを実行することと、ストレージを十分にセットアップすることが挙げられます。 常時監視の場合、ログは、VMware ログのインサイトなどのツールを使用して処理できるかもしれません。
InterSystems データプラットフォームのバックアップと復元操作について、今後の記事で再度取り上げる予定です。 それまでは、システムのワークフローに基づいたコメントや提案がある場合は、以下のコメントセクションに投稿してください。