IRIS 2024.3 で発生する2つの製品障害が確認されました。お使いの環境が該当する場合は、それぞれの解決方法にしたがってご対応いただきますよう、よろしくお願いします。
InterSystemsCachГ©データベースは、すべてのデータ、アプリケーションスクリプトならびにユーザー、ロールおよびセキュリティ構成が保存されるファイルです。 通常、ファイルの名前は cache.dat です。 ドキュメント。
InterSystemsCachГ©データベースは、すべてのデータ、アプリケーションスクリプトならびにユーザー、ロールおよびセキュリティ構成が保存されるファイルです。 通常、ファイルの名前は cache.dat です。 ドキュメント。
IRIS 2024.3 で発生する2つの製品障害が確認されました。お使いの環境が該当する場合は、それぞれの解決方法にしたがってご対応いただきますよう、よろしくお願いします。
これは、InterSystems FAQサイトの記事です。
質問:
データ容量を見積もる計算式はありますか?
回答:
正確に見積もるための計算式は残念ながらありません。
InterSystems IRIS Data Platformの場合、データ部に関してはデータを全て可変長で格納しますので、各フィールドの平均がどのくらいであるかという目安の数字で平均レコード長を求め、キー部分も同様の計算を行い、必要な容量の推測値を求める必要があります。
インデックス部に関してはキー圧縮されますので、データと同じような上記の計算を行った推測値よりは少なくなることが期待できます。 ただしその圧縮率はデータの特性に大きく影響されますので、どの程度少なくなるかは一概には言えません。
実データのサンプル(例えば、1万件のデータ)をロードし、その時点でのサイズを確認して想定される件数分のデータ容量を推測するというのが現実的な方法となります。
これは InterSystems FAQ サイトの記事です。
永続クラス定義では、データを格納するグローバル変数名を初回クラスコンパイル時に決定しています。
グローバル変数名は、コンパイル後に表示されるストレージ定義(Storage)で確認できます。
例)
開発者の皆さん、こんにちは!
この記事は、2024年7月に開催された「InterSystems Pythonプログラミングコンテスト2024」でエキスパート投票、コミュニティ投票の両方で1位を獲得された @Henry Pereira Pereira さん @José Pereira さん @Henrique Dias Dias さんが開発された sqlzilla について、アプリを動かしてみた感想と、中の構造について @José Pereira さんが投稿された「Text to IRIS with LangChain」の翻訳をご紹介します。
第2回 InterSystems Japan 技術文書ライティングコンテスト 開催! では、生成AIに関連する記事を投稿いただくと、ボーナスポイントを4点獲得できます📢 @José Pereira さんの記事を💡ヒント💡に皆様の操作体験談、アイデアなどを共有いただければと思います。
開発されたアプリSQLzilla についての概要ですが、Open Exchange の sqlzilla のREADMEに以下のように紹介されています。
「SQLzilla は、Python と AI のパワーを活用して、自然言語の SQL クエリ生成を通じてデータ アクセスを簡素化し、複雑なデータ クエリとプログラミング経験の少ないユーザーとの間のギャップを埋めます。」
「SQLクエリ生成」とありますので、アプリには Aviationスキーマ以下3つのテーブルとサンプルデータが用意されています。
3つのテーブルには、米国国家運輸安全委員会に報告された航空事故の選択されたサブセットのデータが含まれています。
メモ: サンプルリポジトリ で提供されるデータセットは、http://www.ntsb.gov から入手できる完全な NTSB データセットの小さなサブセットであるためデモ目的のみで提供されており、正確であることを意図または保証するものではありません。(提供元:National Transportation Safety Board)
例えば、Aviation.Aircraftには、AircraftCategoryカラムがあり、航空機の種別が登録されています。
[SQL]IRISAPP>>SELECT AircraftCategory FROM Aviation.Aircraft GROUP BY AircraftCategory
1. SELECT AircraftCategory FROM Aviation.Aircraft GROUP BY AircraftCategory
| AircraftCategory |
| -- |
| AIRPLANE |
| HELICOPTER |
| GYROCRAFT |
| GLIDER |
| BALLOON |
| POWERED PARACHUTE |
| WEIGHT SHIFT |
また、DepartureCity には、出発都市名が登録されています。
SELECT top 10 DepartureCity FROM Aviation.Aircraft WHERE AircraftCategory='AIRPLANE' GROUP BY DepartureCity
| DepartureCity |
| -- |
| WILBUR |
| IRONWOOD |
| STANIEL CAY |
| OAK ISLAND |
| CLEVELAND |
| DECATUR |
| MARSHALLTOWN |
| MARANA |
| TONOPAH |
| MURRIETA/TEMECU |
また、Aviation.Eventテーブルには発生した事故の情報が含まれていて、InjuriesHighestには負傷者数の状況を文字で表現した情報が含まれています。
SELECT InjuriesHighest FROM Aviation.Event GROUP BY InjuriesHighest
| InjuriesHighest |
| -- |
| NONE |
| FATAL |
| SERIOUS |
| MINOR |
さて、これらのテーブルを使って具体的にどのようなことをしてくれるアプリなのか?ですが(説明文より以下抜粋)
「SQLzilla は、ユーザーがデータベースを操作する方法を変革する革新的なプロジェクトです。InterSystems IRIS と統合することで、SQL に詳しくないユーザーでもさまざまなテーブルからデータを簡単に抽出して分析できるツールを作成しました。」
つまり、
SQLに詳しくないユーザでも、自分の欲しい情報に対して質問するとSQLを組み立てて返してきてくれる便利アプリということになります。
以下、アプリケーションを動作させてみたときの図です。(日本語で質問してもしっかりSQLを組み立ててくれています!)

入力した質問によって生成されたSQLは以下の通りです。
SELECT COUNT(*) FROM Aviation.Aircraft WHERE AircraftCategory = 'Helicopter'
SELECT COUNT(*) FROM Aviation.Event WHERE YEAR(EventDate) = 2002 AND Type = 'Helicopter Accident'

SELECT YEAR(e.EventDate) AS IncidentYear, COUNT(*) AS FatalIncidentCount FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE a.AircraftCategory = 'Helicopter' AND e.InjuriesHighest = 'FATAL' GROUP BY YEAR(e.EventDate)
アプリ詳細は、ぜひ Open Exchange の sqlzilla をご参照ください。
素晴らしいです!!
※ このサンプルを動作させるためには、OpenAIのAPIキーが必要となりますので、お試しになる場合は事前にご準備ください。
Open Exchange の sqlzilla のREADMEにも記載がありますが、コンテナを使う場合は以下3コマンドでサンプルを動作させることができます。
まずはソースコードをclone して
git clone https://github.com/musketeers-br/sqlzilla.git
コンテナをビルドし
docker-compose build --no-cache --progress=plain
コンテナを開始するだけ
docker-compose up -d
後は、アプリ画面を起動するだけ!
コンテナ以外でも操作する方法が提供されています。詳しくは、 sqlzilla のREADMEご参照ください。(ぜひREADMEの一番下までご覧ください!)
アプリの中でどのようにSQLを生成させているか、については、 @José Pereira さんが投稿された「Text to IRIS with LangChain」の翻訳記事でご紹介します。
LangChainフレームワーク、IRIS Vector Search、LLMを使って、ユーザープロンプトからIRIS互換のSQLを生成する方法についての実験をご紹介します。
この記事は このノートブック を元にしています。 OpenExchange の このアプリケーション を使えば、すぐに使える環境で実行できます。
最初に必要なライブラリをインストールします。
!pip install --upgrade --quiet langchain langchain-openai langchain-iris pandas
次に、必要なモジュールをインポートし、環境をセットアップします。
import os
import datetime
import hashlib
from copy import deepcopy
from sqlalchemy import create_engine
import getpass
import pandas as pd
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.docstore.document import Document
from langchain_community.document_loaders import DataFrameLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain.globals import set_llm_cache
from langchain.cache import SQLiteCache
from langchain_iris import IRISVector
SQLiteCacheを使ってLLMコールをキャッシュします。
# Cache for LLM calls
set_llm_cache(SQLiteCache(database_path=".langchain.db"))
IRISデータベースへ接続するためのパラメータをセットします。
# IRIS database connection parameters
os.environ["ISC_LOCAL_SQL_HOSTNAME"] = "localhost"
os.environ["ISC_LOCAL_SQL_PORT"] = "1972"
os.environ["ISC_LOCAL_SQL_NAMESPACE"] = "IRISAPP"
os.environ["ISC_LOCAL_SQL_USER"] = "_system"
os.environ["ISC_LOCAL_SQL_PWD"] = "SYS"
OpenAI APIキーが環境変数に設定されていない場合は、ユーザ入力が求められます。
if not "OPENAI_API_KEY" in os.environ:
os.environ["OPENAI_API_KEY"] = getpass.getpass()
IRISデータベースの接続文字列を作成します。
# IRIS database connection string
args = {
'hostname': os.getenv("ISC_LOCAL_SQL_HOSTNAME"),
'port': os.getenv("ISC_LOCAL_SQL_PORT"),
'namespace': os.getenv("ISC_LOCAL_SQL_NAMESPACE"),
'username': os.getenv("ISC_LOCAL_SQL_USER"),
'password': os.getenv("ISC_LOCAL_SQL_PWD")
}
iris_conn_str = f"iris://{args['username']}:{args['password']}@{args['hostname']}:{args['port']}/{args['namespace']}"
IRISデータベースとの接続を確立します。
# Connection to IRIS database
engine = create_engine(iris_conn_str)
cnx = engine.connect().connection
システムプロンプトのコンテキスト情報を保持するdictionaryを用意します。
# Dict for context information for system prompt
context = {}
context["top_k"] = 3
ユーザー入力をIRISデータベースと互換性のあるSQLクエリに変換するために、言語モデル用の効果的なプロンプトを作成する必要があります。
SQLクエリを生成するための基本的な指示を提供する初期プロンプトから始めます。
このテンプレートはLangChain's default prompts for MSSQL から派生し、IRISデータベース用にカスタマイズされています。
# Basic prompt template with IRIS database SQL instructions
iris_sql_template = """
You are an InterSystems IRIS expert. Given an input question, first create a syntactically correct InterSystems IRIS query to run and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the TOP clause as per InterSystems IRIS. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in single quotes ('') to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CAST(CURRENT_DATE as date) function to get the current date, if the question involves "today".
Use double quotes to delimit columns identifiers.
Return just plain SQL; don't apply any kind of formatting.
"""
次のような文章をテンプレートに設定しています: あなたは InterSystems IRIS のエキスパートです。 入力された質問に対して、まず、構文的に正しい InterSystems IRIS クエリを作成し、そのクエリを実行し て、入力された質問に対する回答を返します。 ユーザが質問で特定の数の例を取得するように指定しない限り、InterSystems IRIS に従って、TOP 節を使用して最大 {top_k} の結果をクエリします。 テーブルのすべての列に対してクエリを実行してはなりません。 質問に答えるために必要なカラムのみを問い合わせなければなりません。 各カラム名をシングルクォート('')で囲み、区切り識別子にします。 以下の表で確認できるカラム名のみを使用するように注意してください。 存在しないカラムを問い合わせないように注意してください。 また、どのカラムがどのテーブルにあるかに注意すること。 質問内容が "今日 "を含む場合は、CAST(CURRENT_DATE as date)関数を使用して現在の日付を取得することに注意すること。 カラムの識別子を区切るには二重引用符を使用すること。 単なるSQLを返すこと。いかなるフォーマットも適用しないこと。
この基本プロンプトは、言語モデル(LLM)がIRISデータベースに対する特定のガイダンスを持つSQLエキスパートとして機能するように設定しています。
次に、ハルシネーション(幻覚)を避けるために、データベーススキーマに関する情報を補助プロンプトとして提供します。
# SQL template extension for including tables context information
tables_prompt_template = """
Only use the following tables:
{table_info}
"""
LLMの回答の精度を高めるために、私たちはfew-shot プロンプトと呼ばれるテクニックを使いました。 これはLLMにいくつかの例を提示するものです。
# SQL template extension for including few shots
prompt_sql_few_shots_template = """
Below are a number of examples of questions and their corresponding SQL queries.
{examples_value}
"""
私たちは few-shot の例のためにテンプレートを以下のように定義しています。
# Few shots prompt template
example_prompt_template = "User input: {input}\nSQL query: {query}"
example_prompt = PromptTemplate.from_template(example_prompt_template)
私たちは、 few-shot テンプレートを使ってユーザー・プロンプトを作っています。
# User prompt template
user_prompt = "\n" + example_prompt.invoke({"input": "{input}", "query": ""}).to_string()
最後に、すべてのプロンプトを組み合わせて最終的なプロンプトを作成します。
# Complete prompt template
prompt = (
ChatPromptTemplate.from_messages([("system", iris_sql_template)])
+ ChatPromptTemplate.from_messages([("system", tables_prompt_template)])
+ ChatPromptTemplate.from_messages([("system", prompt_sql_few_shots_template)])
+ ChatPromptTemplate.from_messages([("human", user_prompt)])
)
prompt
このプロンプトは、変数 examples_value, input, table_info, and top_k を想定しています。
プロンプトの構成は以下の通りです。
ChatPromptTemplate(
input_variables=['examples_value', 'input', 'table_info', 'top_k'],
messages=[
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['top_k'],
template=iris_sql_template
)
),
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['table_info'],
template=tables_prompt_template
)
),
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['examples_value'],
template=prompt_sql_few_shots_template
)
),
HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['input'],
template=user_prompt
)
)
]
)
プロンプトがどのようにLLMに送られるかを視覚化するために、必要な変数にプレースホルダーの値を使うことができます。
prompt_value = prompt.invoke({
"top_k": "<top_k>",
"table_info": "<table_info>",
"examples_value": "<examples_value>",
"input": "<input>"
})
print(prompt_value.to_string())
System:
You are an InterSystems IRIS expert. Given an input question, first create a syntactically correct InterSystems IRIS query to run and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most <top_k> results using the TOP clause as per InterSystems IRIS. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in single quotes ('') to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CAST(CURRENT_DATE as date) function to get the current date, if the question involves "today".
Use double quotes to delimit columns identifiers.
Return just plain SQL; don't apply any kind of formatting.
System:
Only use the following tables:
<table_info>
System:
Below are a number of examples of questions and their corresponding SQL queries.
<examples_value>
Human:
User input: <input>
SQL query:
これで、必要な変数を与えることで、このプロンプトをLLMに送る準備ができました。 準備ができたら次のステップに進みましょう。
正確なSQLクエリを作成するためには、言語モデル(LLM)にデータベース・テーブルに関する詳細な情報を提供する必要があります。
この情報がないと、LLMは一見もっともらしく見えますが、ハルシネーション(幻覚)により正しくないクエリを生成する可能性があります。 そこで、最初のステップとして、IRISデータベースからテーブル定義を取得する関数を作成します。
以下の関数はINFORMATION_SCHEMAに問い合わせ、指定されたスキーマのテーブル定義を取得します。
特定のテーブルが指定された場合は、そのテーブルの定義を取得します。そうでない場合は、スキーマ内の全てのテーブルの定義を取得します。
def get_table_definitions_array(cnx, schema, table=None):
cursor = cnx.cursor()
# Base query to get columns information
query = """
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT, PRIMARY_KEY, null EXTRA
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = %s
"""
# Parameters for the query
params = [schema]
# Adding optional filters
if table:
query += " AND TABLE_NAME = %s"
params.append(table)
# Execute the query
cursor.execute(query, params)
# Fetch the results
rows = cursor.fetchall()
# Process the results to generate the table definition(s)
table_definitions = {}
for row in rows:
table_schema, table_name, column_name, column_type, is_nullable, column_default, column_key, extra = row
if table_name not in table_definitions:
table_definitions[table_name] = []
table_definitions[table_name].append({
"column_name": column_name,
"column_type": column_type,
"is_nullable": is_nullable,
"column_default": column_default,
"column_key": column_key,
"extra": extra
})
primary_keys = {}
# Build the output string
result = []
for table_name, columns in table_definitions.items():
table_def = f"CREATE TABLE {schema}.{table_name} (\n"
column_definitions = []
for column in columns:
column_def = f" {column['column_name']} {column['column_type']}"
if column['is_nullable'] == "NO":
column_def += " NOT NULL"
if column['column_default'] is not None:
column_def += f" DEFAULT {column['column_default']}"
if column['extra']:
column_def += f" {column['extra']}"
column_definitions.append(column_def)
if table_name in primary_keys:
pk_def = f" PRIMARY KEY ({', '.join(primary_keys[table_name])})"
column_definitions.append(pk_def)
table_def += ",\n".join(column_definitions)
table_def += "\n);"
result.append(table_def)
return result
この例では、Aviationスキーマを使用しています。Aviationスキーマ情報一式については こちら から入手できます。
# Retrieve table definitions for the Aviation schema
tables = get_table_definitions_array(cnx, "Aviation")
print(tables)
この関数は、Aviation スキーマ内のすべてのテーブルの CREATE TABLE ステートメントを返します。
[
'CREATE TABLE Aviation.Aircraft (\n Event bigint NOT NULL,\n ID varchar NOT NULL,\n AccidentExplosion varchar,\n AccidentFire varchar,\n AirFrameHours varchar,\n AirFrameHoursSince varchar,\n AirFrameHoursSinceLastInspection varchar,\n AircraftCategory varchar,\n AircraftCertMaxGrossWeight integer,\n AircraftHomeBuilt varchar,\n AircraftKey integer NOT NULL,\n AircraftManufacturer varchar,\n AircraftModel varchar,\n AircraftRegistrationClass varchar,\n AircraftSerialNo varchar,\n AircraftSeries varchar,\n Damage varchar,\n DepartureAirportId varchar,\n DepartureCity varchar,\n DepartureCountry varchar,\n DepartureSameAsEvent varchar,\n DepartureState varchar,\n DepartureTime integer,\n DepartureTimeZone varchar,\n DestinationAirportId varchar,\n DestinationCity varchar,\n DestinationCountry varchar,\n DestinationSameAsLocal varchar,\n DestinationState varchar,\n EngineCount integer,\n EvacuationOccurred varchar,\n EventId varchar NOT NULL,\n FlightMedical varchar,\n FlightMedicalType varchar,\n FlightPhase integer,\n FlightPlan varchar,\n FlightPlanActivated varchar,\n FlightSiteSeeing varchar,\n FlightType varchar,\n GearType varchar,\n LastInspectionDate timestamp,\n LastInspectionType varchar,\n Missing varchar,\n OperationDomestic varchar,\n OperationScheduled varchar,\n OperationType varchar,\n OperatorCertificate varchar,\n OperatorCertificateNum varchar,\n OperatorCode varchar,\n OperatorCountry varchar,\n OperatorIndividual varchar,\n OperatorName varchar,\n OperatorState varchar,\n Owner varchar,\n OwnerCertified varchar,\n OwnerCountry varchar,\n OwnerState varchar,\n RegistrationNumber varchar,\n ReportedToICAO varchar,\n SeatsCabinCrew integer,\n SeatsFlightCrew integer,\n SeatsPassengers integer,\n SeatsTotal integer,\n SecondPilot varchar,\n childsub bigint NOT NULL DEFAULT $i(^Aviation.EventC("Aircraft"))\n);',
'CREATE TABLE Aviation.Crew (\n Aircraft varchar NOT NULL,\n ID varchar NOT NULL,\n Age integer,\n AircraftKey integer NOT NULL,\n Category varchar,\n CrewNumber integer NOT NULL,\n EventId varchar NOT NULL,\n Injury varchar,\n MedicalCertification varchar,\n MedicalCertificationDate timestamp,\n MedicalCertificationValid varchar,\n Seat varchar,\n SeatbeltUsed varchar,\n Sex varchar,\n ShoulderHarnessUsed varchar,\n ToxicologyTestPerformed varchar,\n childsub bigint NOT NULL DEFAULT $i(^Aviation.AircraftC("Crew"))\n);',
'CREATE TABLE Aviation.Event (\n ID bigint NOT NULL DEFAULT $i(^Aviation.EventD),\n AirportDirection integer,\n AirportDistance varchar,\n AirportElevation integer,\n AirportLocation varchar,\n AirportName varchar,\n Altimeter varchar,\n EventDate timestamp,\n EventId varchar NOT NULL,\n EventTime integer,\n FAADistrictOffice varchar,\n InjuriesGroundFatal integer,\n InjuriesGroundMinor integer,\n InjuriesGroundSerious integer,\n InjuriesHighest varchar,\n InjuriesTotal integer,\n InjuriesTotalFatal integer,\n InjuriesTotalMinor integer,\n InjuriesTotalNone integer,\n InjuriesTotalSerious integer,\n InvestigatingAgency varchar,\n LightConditions varchar,\n LocationCity varchar,\n LocationCoordsLatitude double,\n LocationCoordsLongitude double,\n LocationCountry varchar,\n LocationSiteZipCode varchar,\n LocationState varchar,\n MidAir varchar,\n NTSBId varchar,\n NarrativeCause varchar,\n NarrativeFull varchar,\n NarrativeSummary varchar,\n OnGroundCollision varchar,\n SkyConditionCeiling varchar,\n SkyConditionCeilingHeight integer,\n SkyConditionNonCeiling varchar,\n SkyConditionNonCeilingHeight integer,\n TimeZone varchar,\n Type varchar,\n Visibility varchar,\n WeatherAirTemperature integer,\n WeatherPrecipitation varchar,\n WindDirection integer,\n WindDirectionIndicator varchar,\n WindGust integer,\n WindGustIndicator varchar,\n WindVelocity integer,\n WindVelocityIndicator varchar\n);'
]
これらのテーブル定義ができたので、次のステップに進むことができます。
これにより、LLMがSQLクエリを生成する際に、データベース・スキーマに関する正確で包括的な情報が得られるようになります。
データベース、特に大規模なデータベースを扱う場合、プロンプト内のすべてのテーブルのデータ定義言語(DDL)を送信することは非現実的です。
このアプローチは小規模なデータベースでは有効かもしれませんが、現実のデータベースには数百から数千のテーブルが含まれていることが多く、すべてのテーブルを処理するのは非効率的です。
さらに、SQLクエリを効率的に生成するために、言語モデルがデータベース内のすべてのテーブルを認識する必要があるとは考えにくいです。 この課題に対処するため、セマンティック検索機能を活用し、ユーザーのクエリに基づいて最も関連性の高いテーブルのみを選択することができます。
IRIS Vector Searchでセマンティック検索を使用することでこれを実現します。
この方法は、SQL要素の識別子(テーブル、フィールド、キーなど)に意味のある名前がある場合に最も効果的です。識別子が任意のコードである場合は、代わりにデータ dictionaryの使用を検討してください。
まず、テーブル定義をpandas DataFrameに取り出します。
# Retrieve table definitions into a pandas DataFrame
table_def = get_table_definitions_array(cnx=cnx, schema='Aviation')
table_df = pd.DataFrame(data=table_def, columns=["col_def"])
table_df["id"] = table_df.index + 1
table_df
DataFrame(table_df)は以下のようになります。
| col_def | id | |
|---|---|---|
| 0 | CREATE TABLE Aviation.Aircraft (\n Event bigi... | 1 |
| 1 | CREATE TABLE Aviation.Crew (\n Aircraft varch... | 2 |
| 2 | CREATE TABLE Aviation.Event (\n ID bigint NOT... | 3 |
次に、テーブル定義をLangchain Documentsに分割します。 このステップは、大きなテキストの塊を扱い、テキスト埋め込みを抽出するために非常に重要です。
loader = DataFrameLoader(table_df, page_content_column="col_def")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=400, chunk_overlap=20, separator="\n")
tables_docs = text_splitter.split_documents(documents)
tables_docs
その結果、tables_docsリストには、次のようにメタデータ付きの分割ドキュメントが含まれます。
[Document(metadata={'id': 1}, page_content='CREATE TABLE Aviation.Aircraft (\n Event bigint NOT NULL,\n ID varchar NOT NULL,\n ...'),
Document(metadata={'id': 2}, page_content='CREATE TABLE Aviation.Crew (\n Aircraft varchar NOT NULL,\n ID varchar NOT NULL,\n ...'),
Document(metadata={'id': 3}, page_content='CREATE TABLE Aviation.Event (\n ID bigint NOT NULL DEFAULT $i(^Aviation.EventD),\n ...')]
次に,langchain-irisのIRISVectorクラスを使って埋め込みベクトルを抽出し、それをIRISに格納します。
tables_vector_store = IRISVector.from_documents(
embedding=OpenAIEmbeddings(),
documents=tables_docs,
connection_string=iris_conn_str,
collection_name="sql_tables",
pre_delete_collection=True
)
注意: pre_delete_collection フラグは、各テスト実行で新鮮なコレクションを確保するために、デモ用に True に設定されています。 本番環境では、このフラグは通常 False に設定します。
テーブルに埋め込み(Embedding)が保存されたことで、ユーザー入力に基づいて関連するテーブルを検索できるようになりました。
input_query = "List the first 2 manufacturers"
relevant_tables_docs = tables_vector_store.similarity_search(input_query, k=3)
relevant_tables_docs
例えば、manufacturers を検索すると、次のような結果が返ってきます。
[Document(metadata={'id': 1}, page_content='GearType varchar,\n LastInspectionDate timestamp,\n ...'),
Document(metadata={'id': 1}, page_content='AircraftModel varchar,\n AircraftRegistrationClass varchar,\n ...'),
Document(metadata={'id': 3}, page_content='LocationSiteZipCode varchar,\n LocationState varchar,\n ...')]
メタデータから、テーブルID 1 (Aviation.Aircraft)だけが関連性があり、クエリと一致していることがわかります。
このアプローチは一般的に効果的ではありますが、常に完璧とは限りません。 たとえば、事故現場のクエリを実行すると、関連性の低いテーブルが返されることもあります。
input_query = "List the top 10 most crash sites"
relevant_tables_docs = tables_vector_store.similarity_search(input_query, k=3)
relevant_tables_docs
結果は以下の通りです。
[Document(metadata={'id': 3}, page_content='LocationSiteZipCode varchar,\n LocationState varchar,\n ...'),
Document(metadata={'id': 3}, page_content='InjuriesGroundSerious integer,\n InjuriesHighest varchar,\n ...'),
Document(metadata={'id': 1}, page_content='CREATE TABLE Aviation.Aircraft (\n Event bigint NOT NULL,\n ID varchar NOT NULL,\n ...')]
正しいAviation.Eventテーブルを2回取得したにもかかわらず、Aviation.Aircraftテーブルも表示されることがあります。これは、この例の範囲を超えているため、将来の実装に委ねられます。
このプロセスを自動化するため、ユーザー入力に基づいて関連するテーブルをフィルタリングして返す関数を定義します。
def get_relevant_tables(user_input, tables_vector_store, table_df):
relevant_tables_docs = tables_vector_store.similarity_search(user_input)
relevant_tables_docs_indices = [x.metadata["id"] for x in relevant_tables_docs]
indices = table_df["id"].isin(relevant_tables_docs_indices)
relevant_tables_array = [x for x in table_df[indices]["col_def"]]
return relevant_tables_array
この機能は、LLMに送信する関連テーブルのみを効率的に検索し、プロンプトの長さを短縮し、クエリ全体のパフォーマンスを向上させるのに役立ちます。
言語モデル(LLM)を扱うとき、適切な例を提供することは、正確で文脈的に適切な応答を保証するのに役立ちます。
これらの例は "Few-Shot" 例と呼ばれ、LLMが処理すべきクエリの構造とコンテキストを理解するためのガイドとなります。今回のケースでは、IRISのSQL構文とデータベースで使用可能なテーブルを幅広くカバーする多様なSQLクエリを examples_value 変数に入力する必要があります。これは、LLMが正しくないクエリーや無関係なクエリーを生成するのを防ぐのに役立ちます。
以下は、様々なSQL操作を説明するために作られたクエリ例のリストです。
examples = [
{"input": "List all aircrafts.", "query": "SELECT * FROM Aviation.Aircraft"},
{"input": "Find all incidents for the aircraft with ID 'N12345'.", "query": "SELECT * FROM Aviation.Event WHERE EventId IN (SELECT EventId FROM Aviation.Aircraft WHERE ID = 'N12345')"},
{"input": "List all incidents in the 'Commercial' operation type.", "query": "SELECT * FROM Aviation.Event WHERE EventId IN (SELECT EventId FROM Aviation.Aircraft WHERE OperationType = 'Commercial')"},
{"input": "Find the total number of incidents.", "query": "SELECT COUNT(*) FROM Aviation.Event"},
{"input": "List all incidents that occurred in 'Canada'.", "query": "SELECT * FROM Aviation.Event WHERE LocationCountry = 'Canada'"},
{"input": "How many incidents are associated with the aircraft with AircraftKey 5?", "query": "SELECT COUNT(*) FROM Aviation.Aircraft WHERE AircraftKey = 5"},
{"input": "Find the total number of distinct aircrafts involved in incidents.", "query": "SELECT COUNT(DISTINCT AircraftKey) FROM Aviation.Aircraft"},
{"input": "List all incidents that occurred after 5 PM.", "query": "SELECT * FROM Aviation.Event WHERE EventTime > 1700"},
{"input": "Who are the top 5 operators by the number of incidents?", "query": "SELECT TOP 5 OperatorName, COUNT(*) AS IncidentCount FROM Aviation.Aircraft GROUP BY OperatorName ORDER BY IncidentCount DESC"},
{"input": "Which incidents occurred in the year 2020?", "query": "SELECT * FROM Aviation.Event WHERE YEAR(EventDate) = '2020'"},
{"input": "What was the month with most events in the year 2020?", "query": "SELECT TOP 1 MONTH(EventDate) EventMonth, COUNT(*) EventCount FROM Aviation.Event WHERE YEAR(EventDate) = '2020' GROUP BY MONTH(EventDate) ORDER BY EventCount DESC"},
{"input": "How many crew members were involved in incidents?", "query": "SELECT COUNT(*) FROM Aviation.Crew"},
{"input": "List all incidents with detailed aircraft information for incidents that occurred in the year 2012.", "query": "SELECT e.EventId, e.EventDate, a.AircraftManufacturer, a.AircraftModel, a.AircraftCategory FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE Year(e.EventDate) = 2012"},
{"input": "Find all incidents where there were more than 5 injuries and include the aircraft manufacturer and model.", "query": "SELECT e.EventId, e.InjuriesTotal, a.AircraftManufacturer, a.AircraftModel FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE e.InjuriesTotal > 5"},
{"input": "List all crew members involved in incidents with serious injuries, along with the incident date and location.", "query": "SELECT c.CrewNumber AS 'Crew Number', c.Age, c.Sex AS Gender, e.EventDate AS 'Event Date', e.LocationCity AS 'Location City', e.LocationState AS 'Location State' FROM Aviation.Crew c JOIN Aviation.Event e ON c.EventId = e.EventId WHERE c.Injury = 'Serious'"}
]
例のリストが増え続けることを考えると、LLMにすべての例を提供することは現実的ではありません。代わりに、IRIS Vector SearchとSemanticSimilarityExampleSelectorクラスを使用して、ユーザーのプロンプトに基づいて最も関連性の高い例を特定します。
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
IRISVector,
k=5,
input_keys=["input"],
connection_string=iris_conn_str,
collection_name="sql_samples",
pre_delete_collection=True
)
注意: pre_delete_collection フラグは、各テスト実行で新鮮なコレクションを確保するためのデモンストレーション目的で使用されています。本番環境では、不要な削除を避けるためにこのフラグを False に設定する必要があります。
与えられた入力に最も関連する例を見つけるには、次のようにSelector を使用します。
input_query = "Find all events in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model."
relevant_examples = example_selector.select_examples({"input": input_query})
結果は以下のようになります。
[{'input': 'List all incidents with detailed aircraft information for incidents that occurred in the year 2012.', 'query': 'SELECT e.EventId, e.EventDate, a.AircraftManufacturer, a.AircraftModel, a.AircraftCategory FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE Year(e.EventDate) = 2012'},
{'input': "Find all incidents for the aircraft with ID 'N12345'.", 'query': "SELECT * FROM Aviation.Event WHERE EventId IN (SELECT EventId FROM Aviation.Aircraft WHERE ID = 'N12345')"},
{'input': 'Find all incidents where there were more than 5 injuries and include the aircraft manufacturer and model.', 'query': 'SELECT e.EventId, e.InjuriesTotal, a.AircraftManufacturer, a.AircraftModel FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE e.InjuriesTotal > 5'},
{'input': 'List all aircrafts.', 'query': 'SELECT * FROM Aviation.Aircraft'},
{'input': 'Find the total number of distinct aircrafts involved in incidents.', 'query': 'SELECT COUNT(DISTINCT AircraftKey) FROM Aviation.Aircraft'}]
数量に関連した例が特に必要な場合は、それに応じてSelectorに問い合わせることができます。
input_query = "What is the number of incidents involving Boeing aircraft."
quantity_examples = example_selector.select_examples({"input": input_query})
出力は以下の通りです。
[{'input': 'How many incidents are associated with the aircraft with AircraftKey 5?', 'query': 'SELECT COUNT(*) FROM Aviation.Aircraft WHERE AircraftKey = 5'},
{'input': 'Find the total number of distinct aircrafts involved in incidents.', 'query': 'SELECT COUNT(DISTINCT AircraftKey) FROM Aviation.Aircraft'},
{'input': 'How many crew members were involved in incidents?', 'query': 'SELECT COUNT(*) FROM Aviation.Crew'},
{'input': 'Find all incidents where there were more than 5 injuries and include the aircraft manufacturer and model.', 'query': 'SELECT e.EventId, e.InjuriesTotal, a.AircraftManufacturer, a.AircraftModel FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE e.InjuriesTotal > 5'},
{'input': 'List all incidents with detailed aircraft information for incidents that occurred in the year 2012.', 'query': 'SELECT e.EventId, e.EventDate, a.AircraftManufacturer, a.AircraftModel, a.AircraftCategory FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE Year(e.EventDate) = 2012'}]
この出力には、特にカウントと量を扱った例が含まれています。
SemanticSimilarityExampleSelectorは強力ですが、選択された例がすべて完璧であるとは限らないことに注意することが重要です。
将来的な改良には、フィルターやしきい値を追加して関連性の低い結果を除外し、最も適切な例だけがLLMに提供されるようにすることが含まれるかもしれません。
プロンプトとSQLクエリ生成のパフォーマンスを評価するために、一連のテストを設定し実行する必要があります。その目的は、LLMがユーザーの入力に基づいてSQLクエリを生成する際に、例題に基づいたfew shotを使用する場合と使用しない場合の、その精度を評価することである。
まず、LLMを使って、提供されたコンテキスト、プロンプト、ユーザー入力、その他のパラメーターに基づいてSQLクエリーを生成する関数を定義します。
def get_sql_from_text(context, prompt, user_input, use_few_shots, tables_vector_store, table_df, example_selector=None, example_prompt=None):
relevant_tables = get_relevant_tables(user_input, tables_vector_store, table_df)
context["table_info"] = "\n\n".join(relevant_tables)
examples = example_selector.select_examples({"input": user_input}) if example_selector else []
context["examples_value"] = "\n\n".join([
example_prompt.invoke(x).to_string() for x in examples
])
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
output_parser = StrOutputParser()
chain_model = prompt | model | output_parser
response = chain_model.invoke({
"top_k": context["top_k"],
"table_info": context["table_info"],
"examples_value": context["examples_value"],
"input": user_input
})
return response
例文がある場合とない場合のプロンプトをテストします。
# Prompt execution **with** few shots
input = "Find all events in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model."
response_with_few_shots = get_sql_from_text(
context,
prompt,
user_input=input,
use_few_shots=True,
tables_vector_store=tables_vector_store,
table_df=table_df,
example_selector=example_selector,
example_prompt=example_prompt,
)
print(response_with_few_shots)
SELECT e.EventId, e.EventDate, e.LocationCity, e.LocationState, a.AircraftManufacturer, a.AircraftModel
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.EventId = a.EventId
WHERE Year(e.EventDate) = 2010
# Prompt execution **without** few shots
input = "Find all events in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model."
response_with_no_few_shots = get_sql_from_text(
context,
prompt,
user_input=input,
use_few_shots=False,
tables_vector_store=tables_vector_store,
table_df=table_df,
)
print(response_with_no_few_shots)
SELECT TOP 3 "EventId", "EventDate", "LocationCity", "LocationState", "AircraftManufacturer", "AircraftModel"
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.ID = a.Event
WHERE e.EventDate >= '2010-01-01' AND e.EventDate < '2011-01-01'
Utility Functions for Testing
生成されたSQLクエリをテストするために、いくつかのユーティリティ関数を定義します。
def execute_sql_query(cnx, query):
try:
cursor = cnx.cursor()
cursor.execute(query)
rows = cursor.fetchall()
return rows
except:
print('Error running query:')
print(query)
print('-'*80)
return None
def sql_result_equals(cnx, query, expected):
rows = execute_sql_query(cnx, query)
result = [set(row._asdict().values()) for row in rows or []]
if result != expected and rows is not None:
print('Result not as expected for query:')
print(query)
print('-'*80)
return result == expected
# SQL test for prompt **with** few shots
print("SQL is OK" if not execute_sql_query(cnx, response_with_few_shots) is None else "SQL is not OK")
SQL is OK
# SQL test for prompt **without** few shots
print("SQL is OK" if not execute_sql_query(cnx, response_with_no_few_shots) is None else "SQL is not OK")
error on running query:
SELECT TOP 3 "EventId", "EventDate", "LocationCity", "LocationState", "AircraftManufacturer", "AircraftModel"
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.ID = a.Event
WHERE e.EventDate >= '2010-01-01' AND e.EventDate < '2011-01-01'
--------------------------------------------------------------------------------
SQL is not OK
一連のテストケースを定義し、実行します。
tests = [{
"input": "What were the top 3 years with the most recorded events?",
"expected": [{128, 2003}, {122, 2007}, {117, 2005}]
},{
"input": "How many incidents involving Boeing aircraft.",
"expected": [{5}]
},{
"input": "How many incidents that resulted in fatalities.",
"expected": [{237}]
},{
"input": "List event Id and date and, crew number, age and gender for incidents that occurred in 2013.",
"expected": [{1, datetime.datetime(2013, 3, 4, 11, 6), '20130305X71252', 59, 'M'},
{1, datetime.datetime(2013, 1, 1, 15, 0), '20130101X94035', 32, 'M'},
{2, datetime.datetime(2013, 1, 1, 15, 0), '20130101X94035', 35, 'M'},
{1, datetime.datetime(2013, 1, 12, 15, 0), '20130113X42535', 25, 'M'},
{2, datetime.datetime(2013, 1, 12, 15, 0), '20130113X42535', 34, 'M'},
{1, datetime.datetime(2013, 2, 1, 15, 0), '20130203X53401', 29, 'M'},
{1, datetime.datetime(2013, 2, 15, 15, 0), '20130218X70747', 27, 'M'},
{1, datetime.datetime(2013, 3, 2, 15, 0), '20130303X21011', 49, 'M'},
{1, datetime.datetime(2013, 3, 23, 13, 52), '20130326X85150', 'M', None}]
},{
"input": "Find the total number of incidents that occurred in the United States.",
"expected": [{1178}]
},{
"input": "List all incidents latitude and longitude coordinates with more than 5 injuries that occurred in 2010.",
"expected": [{-78.76833333333333, 43.25277777777778}]
},{
"input": "Find all incidents in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model.",
"expected": [
{datetime.datetime(2010, 5, 20, 13, 43), '20100520X60222', 'CIRRUS DESIGN CORP', 'Farmingdale', 'New York', 'SR22'},
{datetime.datetime(2010, 4, 11, 15, 0), '20100411X73253', 'CZECH AIRCRAFT WORKS SPOL SRO', 'Millbrook', 'New York', 'SPORTCRUISER'},
{'108', datetime.datetime(2010, 1, 9, 12, 55), '20100111X41106', 'Bayport', 'New York', 'STINSON'},
{datetime.datetime(2010, 8, 1, 14, 20), '20100801X85218', 'A185F', 'CESSNA', 'New York', 'Newfane'}
]
}]
テストを実施し、精度を計算します。
def execute_tests(cnx, context, prompt, use_few_shots, tables_vector_store, table_df, example_selector, example_prompt):
tests_generated_sql = [(x, get_sql_from_text(
context,
prompt,
user_input=x['input'],
use_few_shots=use_few_shots,
tables_vector_store=tables_vector_store,
table_df=table_df,
example_selector=example_selector if use_few_shots else None,
example_prompt=example_prompt if use_few_shots else None,
)) for x in deepcopy(tests)]
tests_sql_executions = [(x[0], sql_result_equals(cnx, x[1], x[0]['expected']))
for x in tests_generated_sql]
accuracy = sum(1 for i in tests_sql_executions if i[1] == True) / len(tests_sql_executions)
print(f'Accuracy: {accuracy}')
print('-'*80)
# Accuracy tests for prompts executed **without** few shots
use_few_shots = False
execute_tests(
cnx,
context,
prompt,
use_few_shots,
tables_vector_store,
table_df,
example_selector,
example_prompt
)
error on running query:
SELECT "EventDate", COUNT("EventId") as "TotalEvents"
FROM Aviation.Event
GROUP BY "EventDate"
ORDER BY "TotalEvents" DESC
TOP 3;
--------------------------------------------------------------------------------
error on running query:
SELECT "EventId", "EventDate", "C"."CrewNumber", "C"."Age", "C"."Sex"
FROM "Aviation.Event" AS "E"
JOIN "Aviation.Crew" AS "C" ON "E"."ID" = "C"."EventId"
WHERE "E"."EventDate" >= '2013-01-01' AND "E"."EventDate" < '2014-01-01'
--------------------------------------------------------------------------------
result not expected for query:
SELECT TOP 3 "e"."EventId", "e"."EventDate", "e"."LocationCity", "e"."LocationState", "a"."AircraftManufacturer", "a"."AircraftModel"
FROM "Aviation"."Event" AS "e"
JOIN "Aviation"."Aircraft" AS "a" ON "e"."ID" = "a"."Event"
WHERE "e"."EventDate" >= '2010-01-01' AND "e"."EventDate" < '2011-01-01'
--------------------------------------------------------------------------------
accuracy: 0.5714285714285714
--------------------------------------------------------------------------------
# Accuracy tests for prompts executed **with** few shots
use_few_shots = True
execute_tests(
cnx,
context,
prompt,
use_few_shots,
tables_vector_store,
table_df,
example_selector,
example_prompt
)
error on running query:
SELECT e.EventId, e.EventDate, e.LocationCity, e.LocationState, a.AircraftManufacturer, a.AircraftModel
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.EventId = a.EventId
WHERE Year(e.EventDate) = 2010 TOP 3
--------------------------------------------------------------------------------
accuracy: 0.8571428571428571
--------------------------------------------------------------------------------
例(few shots)を使って生成されたSQLクエリの精度は、例なしで生成されたもの(85%対57%)に比べて約49%高くなりました。
Debeziumをご存じでしょうか?
グローバルサミット2023にて、Debeziumを題材としたセッション「Near Real Time Analytics with InterSystems IRIS & Debezium Change Data Capture」がありましたので、ご覧になられた方もおられるかと思います。
ご興味がありましたら、グローバルサミット2023の録画アーカイブをご覧ください。
FAQによると、"dee-BEE-zee-uhm"(ディビジウム..ですかね)と読むそうです。元素周期表のように複数のDB(s)を束ねる、というニュアンスみたいです。
CDC(Change data capture)という分野のソフトウェアです。
外部データベースでの変更を追跡して、IRISに反映したいという要望は、インターオペラビリティ機能導入の動機のひとつになっています。一般的には、定期的にSELECT文のポーリングをおこなって、変更対象となるレコード群(差分。対象が少なければ全件)を外部システムから取得する方法が、お手軽で汎用性も高いですが、タイムスタンプや更新の都度に増加するようなバージョンフィールドが元テーブルに存在しない場合、どうしても、各ポーリング間で重複や見落としがでないように、受信側で工夫する必要があります。また、この方法ではデータの削除を反映することはできませんので、代替案として削除フラグを採用するといったアプリケーションでの対応が必要になります。
CDCは、DBMSのトランザクションログをキャプチャすることで、この課題への解決策を提供しています。DebeziumはRedHatが中心となっているCDCのオープンソースプロジェクトです。
CDCにはいくつかの利点があります。
ポーリングではないので、更新が瞬時に伝わる
DELETEも反映できる
SourceになるDBMSに対して非侵襲的
テーブル定義を変更したり専用のテーブルを作成しなくて済む。パフォーマンスへの影響が軽微。
先進医療っぽい表現ですね。対象に与える影響が軽微というニュアンスだと思います。
受信側(アプリケーション側)の設計が楽
下記は受信側の仕組みに依存する話ですが、例えばIRISのRESTサービスで受信する場合
ひとつのハンドラ(Restのディスパッチクラス)で、複数のテーブルを処理できる
このことはSQLインバウンドサービスがテーブル単位であることと対照的です。
一方、トランザクションログのメカニズムは各DBMS固有なので、DBMSやそのバージョン毎にセットアップ手順、振る舞い、特性が異なる可能性があるというマイナス面があります。
セットアップ作業は、SQLインバウンドアダプタほど簡単ではありません。
DebeziumはKafkaのSourceコネクタとして使用する用法が一般的です。
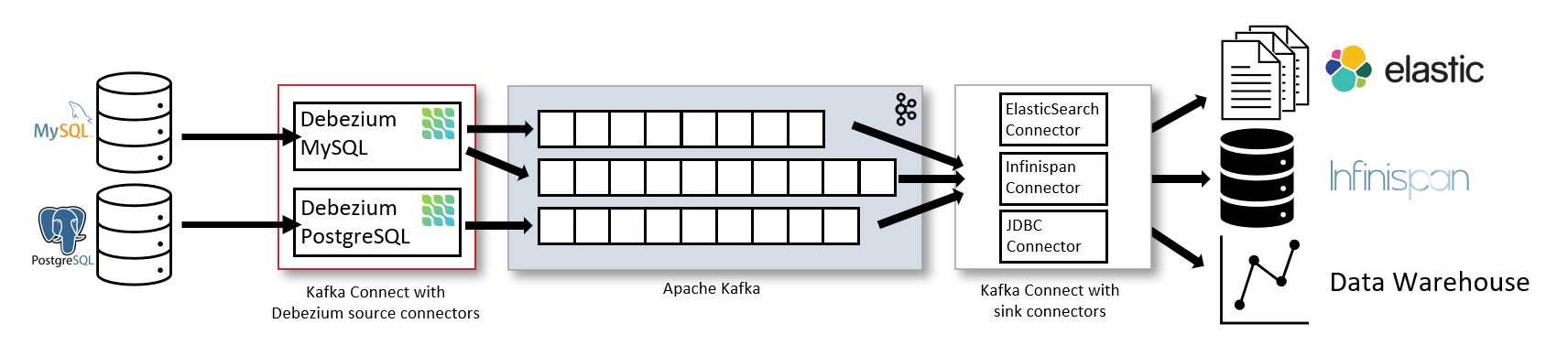
引用元: https://debezium.io/documentation/reference/stable/architecture.html
Kafkaのコネクタとしての用法は本稿では扱いません。
今回のメインテーマはKafkaではありませんが、関連するいくつかのKafka用語を確認をしておきたいと思います。
Kakfaにメッセージを送信するデータの発生元のことをProducer、メッセージを消費する送信先のことをConsumerと呼びます。

外部システムとの連携用のフレームワークをKafkaコネクトと呼びます。Kafkaコネクトにおいて、外部システムと接続する部分をコネクタと呼び、Producer 側の コネクタ は Sourceコネクタ、Consumer 側の コネクタ は Sinkコネクタと、それぞれ呼びます。

DebeziumはKafkaのSourceコネクタです。
Kafkaが提供するエンタープライズ級の機能を使いたければ、Kafkaの構成・運用を含めて検討する価値があります。一方、そうでない場合、Debeziumを単体のサーバで動作させることが出来ます。
Debezium Serverと言います。その他の選択肢として、自作のJavaアプリケーションに組み込む方法もあります。

随分とシンプルな構成になります。
KafkaのSinkコネクタを経由しなくても、Debezium自身が様々な送信先に対応しています。Debeziumから見ると、Kafkaは送信先のひとつという位置づけです。
例えば、「POSTGRES上でのデータ更新をCDCして、その内容をhttp serverに送信」したい場合、 POSTGRES用のSourceコネクタと、http Clientを使うことになります。
Debeziumは、SourceとしてこれらのDBMSに対応しています。
残念ながらIRISはSourceになれません。IRISからIRISへのデータの同期であれば非同期ミラリングがお勧めです。
今回使用するソースコード一式はこちらにあります。 IRIS環境はコミュニティエディションにネームスペースMYAPPの作成と、3個の空のテーブル作成(01_createtable.sqlを使用)を行ったものになります。
$ git clone https://github.com/IRISMeister/DebeziumServer-IRIS
$ cd DebeziumServer-IRIS
$ cd postgres (POSTGRESを試す場合。以降POSTGRESを使用します)
あるいは
$ cd mysql (MYSQLを試す場合)
$ ./up.sh
正常に起動した場合、3個のサービスが稼働中になります。
$ docker composeps ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
iris postgres-iris "/tini -- /iris-main --ISCAgent false --monitorCPF false" iris 12 minutes ago Up 12 minutes (healthy) 2188/tcp, 53773/tcp, 0.0.0.0:1972->1972/tcp, :::1972->1972/tcp, 54773/tcp, 0.0.0.0:52873->52773/tcp, :::52873->52773/tcp
postgres-debezium-server-1 debezium/server:2.4 "/debezium/run.sh" debezium-server 12 minutes ago Up 12 minutes 8080/tcp, 8443/tcp, 8778/tcp
postgres-postgres-1 debezium/example-postgres "docker-entrypoint.sh postgres" postgres 12 minutes ago Up 12 minutes 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp
初期状態を確認します。起動直後に、POSTGRES上の既存のレコード群がIRISに送信されますのでそれを確認します。端末を2個ひらいておくと便利です。以下(端末1)をPOSTGRESの, (端末2)をIRISのSQL実行に使用します。
(端末1 PG)
$ docker compose exec -u postgres postgres psql
psql (15.2 (Debian 15.2-1.pgdg110+1))
Type "help" for help.
postgres=# select * from inventory.orders;
id | order_date | purchaser | quantity | product_id
-------+------------+-----------+----------+------------
10001 | 2016-01-16 | 1001 | 1 | 102
10002 | 2016-01-17 | 1002 | 2 | 105
10003 | 2016-02-19 | 1002 | 2 | 106
10004 | 2016-02-21 | 1003 | 1 | 107
(4 rows)
postgres=# select * from inventory.products;
id | name | description | weight
-----+--------------------+---------------------------------------------------------+--------
101 | scooter | Small 2-wheel scooter | 3.14
102 | car battery | 12V car battery | 8.1
103 | 12-pack drill bits | 12-pack of drill bits with sizes ranging from #40 to #3 | 0.8
104 | hammer | 12oz carpenter's hammer | 0.75
105 | hammer | 14oz carpenter's hammer | 0.875
106 | hammer | 16oz carpenter's hammer | 1
107 | rocks | box of assorted rocks | 5.3
108 | jacket | water resistent black wind breaker | 0.1
109 | spare tire | 24 inch spare tire | 22.2
(9 rows)
postgres=# select * from inventory.customers;
id | first_name | last_name | email
------+------------+-----------+-----------------------
1001 | Sally | Thomas | sally.thomas@acme.com
1002 | George | Bailey | gbailey@foobar.com
1003 | Edward | Walker | ed@walker.com
1004 | Anne | Kretchmar | annek@noanswer.org
(4 rows)
postgres=# \q
$
IRIS上のレコードは下記のコマンドで確認できます。POSTGRES上のレコードと同じになっているはずです。
(端末2 IRIS)
$ docker compose exec iris iris sql iris -Umyapp
[SQL]MYAPP>>set selectmode=odbc
[SQL]MYAPP>>select * from inventory.orders
出力は省略
[SQL]MYAPP>>select * from inventory.products
[SQL]MYAPP>>select * from inventory.customers
次に、POSTGRESで各種DMLを実行します。
(端末1 PG)
update inventory.orders set quantity=200 where id=10001;
UPDATE 1
postgres=# delete from inventory.orders where id=10002;
DELETE 1
insert into inventory.orders (order_date,purchaser,quantity,product_id) values ('2023-01-01',1003,10,105);
INSERT 0 1
update inventory.products set description='商品説明' where id=101;
UPDATE 1
その結果がIRISに伝わり反映されます。
(端末2 IRIS)
[SQL]MYAPP>>select * from inventory.orders
3. select * from inventory.orders
id order_date purchaser quantity product_id
10001 2016-01-16 1001 300 102
10003 2016-02-19 1002 2 106
10004 2016-02-21 1003 1 107
10005 2023-01-01 1003 10 105
4 Rows(s) Affected
[SQL]MYAPP>>select * from inventory.products where id=101
4. select * from inventory.products where id=101
id name description weight
101 scooter 商品説明 3.14
1 Rows(s) Affected
Debezium Serverのhttp clientは、指定したエンドポイントにREST+JSON形式で内容を送信してくれます。エンドポイントにIRISのRESTサービスを指定することで、IRISでその内容をパースし、必要な処理を実行(今回は単純にSQLの実行)しています。
INSERT時には、こちら、UPDATE時には、こちらのようなJSONがPOSTされます。
payload.opにPOSTGRESへの操作の値であるc:Create, u:Update, d:Delete, r:Readが伝わりますので、その内容に基づいて、IRISのRESTディスパッチャークラス(Dispatcher.cls)にて、SQL文を組み立てて実行しています。
r:Readは、初回接続時に実行されるスナップショット取得作業の際に既存のレコード群を読み込み(READ)、それらが送信される場合に使用されます。詳細はこちらをご覧ください。
Debezium Serverの詳細は公式ドキュメントをご覧ください。
ドキュメントを見ると大量のコーディング例(Java)と構成例が載っており、これ全部理解してプログラムを書かないと使えないのかと思ってしまいますが、幸いコンテナイメージとして公開されていますので、今回はそれを利用しています。ソースコードも公開されています。
明言はされていませんでしたが、グローバルサミット2023のデモは、JavaベースのカスタムアプリケーションサーバからJava APIを使用してDebeziumの機能を使用するスタイルかもしれません
Debezium Serverの欠点といいますか特徴として、接続先が未達になると直ぐ落ちるというのがあります。例えばIRISが停止すると、Debezium Serverが停止(今回の構成では、コンテナが停止)してしまいます。ただ、どこまで処理したかをO/Sファイル(本例ではdata/offsets.dat)に保存していますので、IRIS起動後に、Debezium Serverのコンテナを再開すれば、停止中に発生した更新をキャプチャしてくれます。
停止したコンテナの再開は下記コマンドで行います。
docker compose start debezium-server
「あれ、落ちるんだ」と思いましたが、フェールセーフ思想なのだと思います。 対障害性はKafka Connectに管理してもらう前提になっているためだと思います。
MYSQLもほぼ同じ操作で動作確認が出来ます。./mysqlに必要なファイルがあります。mysql.txtを参照ください。
また、今回は、レコードを同期しているだけですが、GS2023のように組み込みBIのキューブを作成して分析用途にしたり、何某かのビジネスロジックを実行したり、インターオペラビリティ機能に連動させたりといった応用が考えられます。
これは InterSystems FAQ サイトの記事です。
以下の状態の時、ReadOnlyでマウントされます。
これは InterSystems FAQ サイトの記事です。
バージョン2017.2以降から、CREATE TABLE文で作成したテーブル定義のデータを格納するグローバル変数の命名ルールが変わり ^EPgS.D8T6.1 のようなハッシュ化したグローバル変数名が設定されます。(この変更はパフォーマンス向上のために追加されました。)
※ バージョン2017.1以前については、永続クラス定義のルールと同一です。詳細は関連記事「永続クラス定義のデータが格納されるグローバル変数名について」をご参照ください。
以下のテーブル定義を作成すると、同名の永続クラス定義が作成されます。
CREATETABLE Test.Product(
ProductID VARCHAR(10) PRIMARY KEY,
ProductName VARCHAR(50),
Price INTEGER
)永続クラス:Test.Productの定義は以下の通りです。(パラメータ:USEEXTENTSETに1が設定されます)

このフォーメーションは私の GitHub にあり、30 分で csv ファイルと txt ファイルの読み取りと書き込み方法、Postgres を使ったIRIS データベースとリモートデータベースの挿入とアクセス方法、FLASK API の使用方法について説明します。これらすべてに、PEP8 命名規則に従った、Python のみのインターオペラビリティフレームワークを使用します。
このフォーメーションは、ほとんどをコピー&ペースト操作で実行でき、グローバル演習を行う前に、ステップごとの操作が説明されています。
記事のコメント欄、Teams、またはメール(lucas.enard@intersystems.com)でご質問にお答えします。
このフォーメーションに関するあらゆる点において、ご意見やご感想をお送りいただけると幸いです。
このフォーメーションでは、Python および特に以下を使用した InterSystems のインターオペラビリティフレームワークを学習することを目標としています。
目次:
以下は、IRIS フレームワークです。
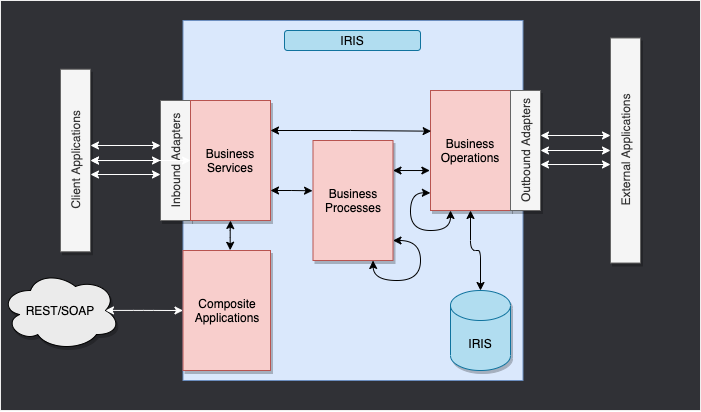
IRIS 内部のコンポーネントは、本番環境を表します。 インバウンドアダプターとアウトバウンドアダプターは、様々な種類のフォーマットをデータベースの入力と出力として使用できるようにします。
複合アプリケーションにより、REST サービスなどの外部アプリケーションを通じて本番環境にアクセスできます。
これらのコンポーネントを繋ぐ矢印はメッセージで、 リクエストかレスポンスを表します。
ここでは、CSV ファイルから行を読み取り、IRIS データベースに .txt ファイルで保存します。
次に、外部データベースにオブジェクトを保存できるようにするオペレーションを db-api を使って追加します。 このデータベースは Docker コンテナに配置されており、Postgres を使用します。
最後に、複合アプリケーションを使用して、新しいオブジェクトをデータベースに挿入する方法またはこのデータベースを照会する方法を確認します(ここでは、REST サービスを使用します)。
この目的に合わせて構成されたフレームワークは、以下のようになります。
WIP 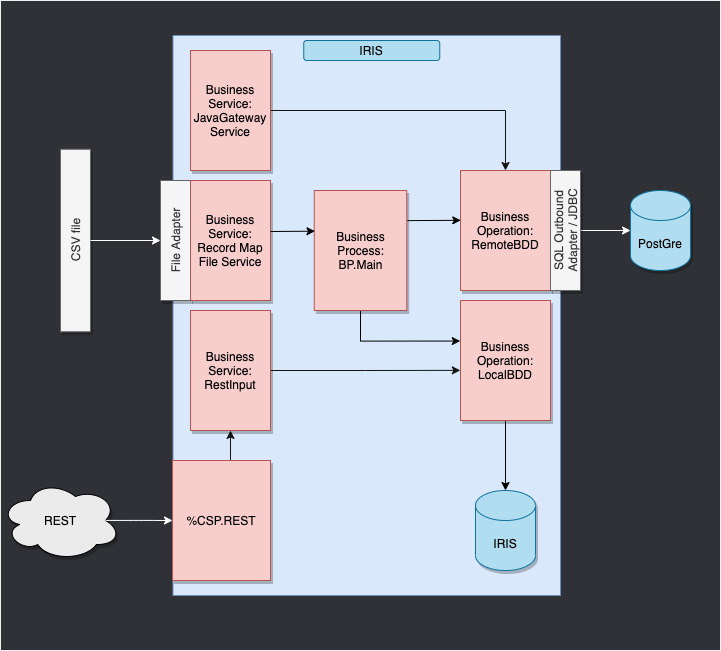
このフォーメーションでは、以下の項目が必要です。
InterSystems イメージにアクセスするために、次の URL に移動してください: http://container.intersystems.com。 InterSystems の資格情報にリンクすると、レジストリに接続するためのパスワードを取得できます。 Docker の VSCode アドオンのイメージタブで、[レジストリを接続]を押し、汎用レジストリとして上記の URL(http://container.intersystems.com)を入力すると、資格情報の入力を求められます。 このログインは通常のログインですが、パスワードはウェブサイトから取得したものを使用します。
これが済むと、コンテナを構築・作成(指定された docker-compose.yml と Dockerfile を使用)できるようになります。
このリポジトリは、VS Code 対応です。
ローカルにクローンした formation-template-python を VS Code で開きます。
指示されたら(右下に表示)、推奨される拡張機能をインストールしてください。
コーディングする前に、コンテナ内部にアクセスしていることが非常に重要です。
これには、docker が VSCode を開く前に有効である必要があります。
次に VSCode 内で指示されたら(右下に表示)、コンテナ内のフォルダを開き直すと、その中にある Python コンポーネントを使用できるようになります。
これを初めて行う場合、コンテナの準備が整うまで数分かかる場合があります。

リモートのフォルダを開くと、その中で開く VS Code とターミナルで、コンテナ内の Python コンポーネントを使用できます。 /usr/irissys/bin/irispython を使用するように構成してください。

本番環境に対して Python で作成しているコンポーネントを登録するには、grongier.pex._utils モジュールから register_component 関数を使用する必要があります。
重要: コンポーネントはすでに登録済みです(グローバル演習を除く)。
情報までに、またグローバル演習で使用できるように、以下の手順でコンポーネントを登録します。
これには、プロジェクトで作業している際に、最初に組み込み Python コンソールを使用して手動でコンポーネントを追加することをお勧めします。
これらのコマンドは、misc/register.py ファイルにあります。
このコマンドを使用するには、まずコンポーネントを作成してから、VSCode でターミナルを起動する必要があります(5.2 と 5.3 の手順を実行している場合は、自動的にコンテナ内に移動しています)。
IrisPython コンソールを起動するには、以下のように入力します。
/usr/irissys/bin/irispython
次に、以下を入力します。
from grongier.pex._utils import register_component
そして、以下のようにして、コンポーネントを登録できます。
register_component("bo","FileOperation","/irisdev/app/src/python/",1,"Python.FileOperation")
この行は、bo モジュール内にコーディングされている FileOperation クラスを登録します。このファイルは /irisdev/app/src/python/(このコースに従って作業している場合のパス)にあり、管理ポータルでは Python.FileOperation という名前を使用しています。
コンポーネントが登録済みである際にこのファイルの名前、クラスまたはパスを変更しない場合、VSCode でそれらを変更することが可能です。登録し直す必要はありません。 管理ポータルでの再起動は、必ず行ってください。
フォーメーションのある時点でやり方がわからなくなったり、さらに説明が必要となった場合は、GitHub の solution ブランチにすべての正しい内容と動作する本番環境をご覧いただけます。
本番環境は、Iris 上のすべての作業の土台であり、サービス、プロセス、およびオペレーションをまとめるフレームワークの外殻として考える必要があります。
本番環境内のすべては関数を継承します。この関数は、このクラスのインスタンスの作成時に解決する on_init 関数と、インスタンスがキルされたときに解決する on_tear_down 関数です。 これは、書き込みを行うときに変数を設定する際、または使用された開いているファイルをクローンする際に役立ちます。
ほぼすべてのサービス、プロセス、およびオペレーションを持つ本番環境は、すでに作成済みであることに注意してください。
指示されたら、ユーザー名の SuperUser とパスワードの SYS を使用して接続してください。
本番環境が開いていない場合は、[Interoperability] > [Configure] メニューに移動して、[Production] をクリックし、 次に [Open] をクリックして iris / Production を選択します。
これを行ったら、ビジネスオペレーションに直接進むことができます。
ただし、本番環境の作成方法に興味がある場合は、以下のようにして作成することができます。
管理ポータルに移動し、ユーザー名: SuperUser、パスワード: SYS を使用して接続します。
次に、[Interoperability] と [Configure] メニューに進みます。

次に、[New] を押して [Formation] パッケージを選択し、本番環境の名前を設定します。
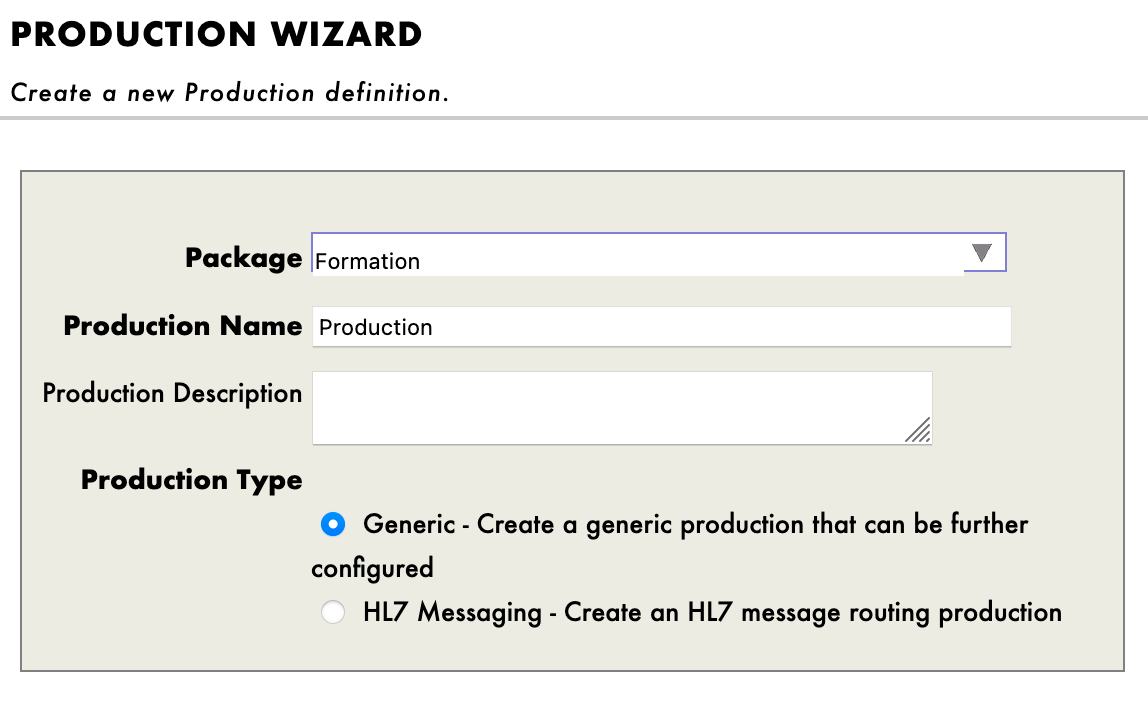
本番環境を作成した直後、[Operations] セクションの真上にある [Production Settings(本番環境の設定)] をクリックする必要があります。 右のサイドバーメニューで、[Settings] タブの [Development and Debugging(開発とデバッグ)] で [Testing Enabled(テストを有効)] をアクティブにします(忘れずに [Apply] を押してください)。
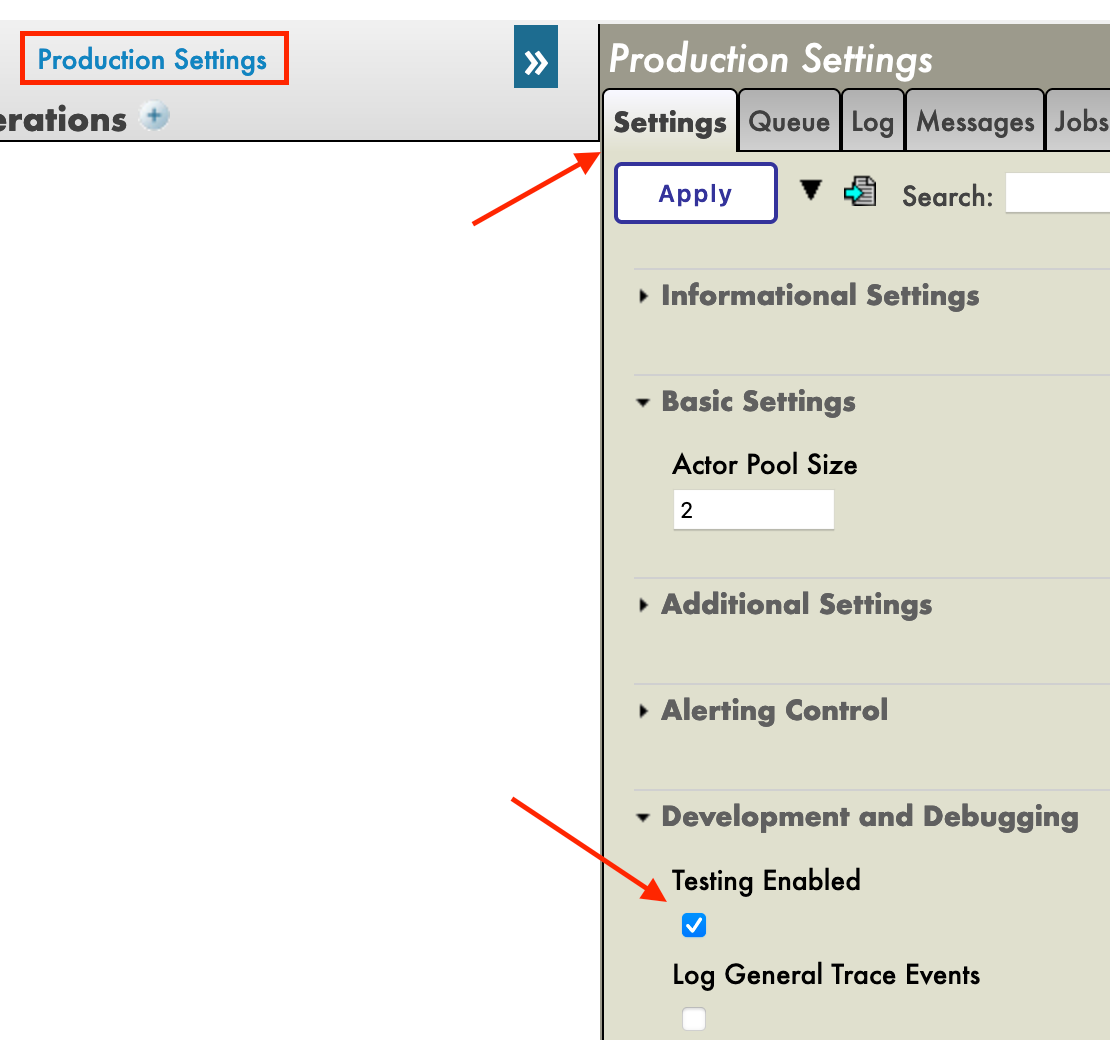
この最初の本番環境で、ビジネスオペレーションを追加していきます。
ビジネスオペレーション(BO)は、IRIS から外部アプリケーション/システムにリクエストを送信できるようにする特定のオペレーションです。 必要なものを IRIS に直接保存するためにも使用できます。
BO には、このインスタンスがソースからメッセージを受信するたびに呼び出される on_message 関数もあるため、フレームワークで確認できるように、情報を外部クライアントと送受信することが可能です。
これらのオペレーションは、VSCode でローカルに作成します。つまり、src/python/bo.py ファイルです。
このファイルを保存すると、IRIS でコンパイルされます。
ここでの最初のオペレーションでは、メッセージのコンテンツをローカルデータベースに保存し、同じ情報をローカルの .txt ファイルに書き込みます。
まずは、このメッセージを保存する方法を作成する必要があります。
dataclass を使用して、メッセージの情報を格納することにします。
すでに存在する src/python/obj.py ファイルを以下のようにします。
インポート:
from dataclasses import dataclass
コード:
@dataclass
class Formation:
id_formation:int = None
nom:str = None
salle:str = None
@dataclass
class Training:
name:str = None
room:str = None
Formation クラスは、csv の情報を格納して「8. ビジネスプロセス」に送信する Python オブジェクトとして使用し、Training クラスは、「8. ビジネスプロセス」から複数のオペレーションに情報を送信し、Iris データベースに保存するか .txt ファイルに書き込むために使用されます。
これらのメッセージには、7.1 で作成された obj.py ファイルにある Formation オブジェクトまたは Training オブジェクトが含まれます。
メッセージ、リクエスト、およびレスポンスはすべて grongier.pex.Message クラスの継承であることに注意してください。
すでに存在する src/python/msg.py ファイルを以下のようにします。
インポート:
from dataclasses import dataclass
from grongier.pex import Message
from obj import Formation,Training
コード:
@dataclass
class FormationRequest(Message):
formation:Formation = None
@dataclass
class TrainingRequest(Message):
training:Training = None
繰り返しますが、FormationRequest クラスは、csv の情報を格納して「8. ビジネスプロセス」に送信するメッセージとして使用し、TrainingRequest クラスは、「8. ビジネスプロセス」から複数のオペレーションに情報を送信し、Iris データベースに保存するか .txt ファイルに書き込むために使用されます。
必要な要素がすべて揃ったので、オペレーションを作成できるようになりました。
すべてのビジネスオペレーションは、grongier.pex.BusinessOperation クラスを継承していることに注意してください。
すべてのオペレーションは、src/python/bo.py に保存されます。これらを区別できるよう、ファイルに現時点で確認できるように複数のクラスを作成する必要があります。オペレーションのすべてのクラスはすでに存在していますが、現時点ではほぼ空の状態です。
オペレーションがメッセージ/リクエストを受信すると、各関数のシグネチャに指定されたメッセージ/リクエストの種類に応じて自動的に正しい関数にメッセージ/リクエストを送信します。 メッセージ/リクエストの種類が処理されない場合は、on_message 関数に転送されます。
すでに存在する src/python/bo.py ファイルを以下のようにします。
インポート:
from grongier.pex import BusinessOperation
import os
import iris
from msg import TrainingRequest,FormationRequest
FileOperation クラスのコード:
class FileOperation(BusinessOperation):
"""
トレーニングまたは患者をファイルに書き込むオペレーションです。
"""
def on_init(self):
"""
現在の作業ディレクトリを、オブジェクトの path 属性に指定されたディレクトリか、path 属性が指定されていない場合は /tmp ディレクトリに変更します。
また、filename 属性が設定されていない場合は、toto
.csv に設定します。
:return: None
"""
if hasattr(self,'path'):
os.chdir(self.path)
else:
os.chdir("/tmp")
return None
def write_training(self, request:TrainingRequest):
"""
ファイルにトレーニングを書き込みます。
:param request: The request message
:type request: TrainingRequest
:return: None
"""
romm = name = ""
if request.training is not None:
room = request.training.room
name = request.training.name
line = room+" : "+name+"\n"
filename = 'toto.csv'
self.put_line(filename, line)
return None
def on_message(self, request):
return None
def put_line(self,filename,string):
"""
ファイルを開き、文字列を追加し、ファイルを閉じます。
:param filename: The name of the file to write to
:param string: The string to be written to the file
"""
try:
with open(filename, "a",encoding="utf-8",newline="") as outfile:
outfile.write(string)
except Exception as error:
raise error
ご覧のとおり、FileOperation が msg.TrainingRequest タイプのメッセージを受信すると、request のシグネチャが TrainingRequest であるため、write_training 関数に送信されます。
この関数では、メッセージが格納する情報が toto.csv ファイルに書き込まれます。
path はオペレーションのパラメーターであるため、filename を管理ポータルで直接変更できる変数にし、基本値を toto.csv とすることができます。
このようにするには、on_init 関数を以下のように編集する必要があります。
def on_init(self):
if hasattr(self,'path'):
os.chdir(self.path)
else:
os.chdir("/tmp")
if not hasattr(self,'filename'):
self.filename = 'toto.csv'
return None
次に、オペレーションに直接コーディングして filename = 'toto.csv' を使用する代わりに、self.filename を呼び出します。
すると、write_training 関数は、以下のようになります。
def write_training(self, request:TrainingRequest):
romm = name = ""
if request.training is not None:
room = request.training.room
name = request.training.name
line = room+" : "+name+"\n"
self.put_line(self.filename, line)
return None
独自の filename の選択方法にいては、「7.5 テスト」をご覧ください。
情報を .txt ファイルに書き込めるようになりましたが、iris データベースはどうなっているでしょうか?src/python/bo.py ファイルでは、IrisOperation クラスのコードは以下のようになっています。
class IrisOperation(BusinessOperation):
"""
iris データベースにトレーニングを書き込むオペレーション
"""
def insert_training(self, request:TrainingRequest):
"""
`TrainingRequest` オブジェクトを取り、新しい行を `iris.training` テーブルに挿入し、
`TrainingResponse` オブジェクトを返します
:param request: 関数に渡されるリクエストオブジェクト
:type request: TrainingRequest
:return: TrainingResponse メッセージ
"""
sql = """
INSERT INTO iris.training
( name, room )
VALUES( ?, ? )
"""
iris.sql.exec(sql,request.training.name,request.training.room)
return None
def on_message(self, request):
return None
ご覧のとおり、IrisOperation が msg.TrainingRequest タイプのメッセージを受信すると、このメッセージが保有する情報は、iris.sql.exec IrisPython 関数によって SQL クエリに変換されて実行されます。 このメソッドによって、メッセージは IRIS ローカルデータベースに保存されます。
これらのコンポーネントは、事前に本番環境に登録済みです。
情報までに、コンポーネントを登録する手順は、5.4. に従い、以下を使用します。
register_component("bo","FileOperation","/irisdev/app/src/python/",1,"Python.FileOperation")
および、以下を使用します。
register_component("bo","IrisOperation","/irisdev/app/src/python/",1,"Python.IrisOperation")
オペレーションは、こちらで事前に登録済みです。
ただし、オペレーションを新規作成する場合は、手動で追加する必要があります。
今後の参考までに、オペレーションの登録手順を説明します。
登録には、管理ポータルを使用します。 [Operations] の横にある [+] 記号を押すと、[Business Operation Wizard(ビジネスオペレーションウィザード)] が開きます。
そのウィザードで、スクロールメニューから作成したばかりのオペレーションクラスを選択します。
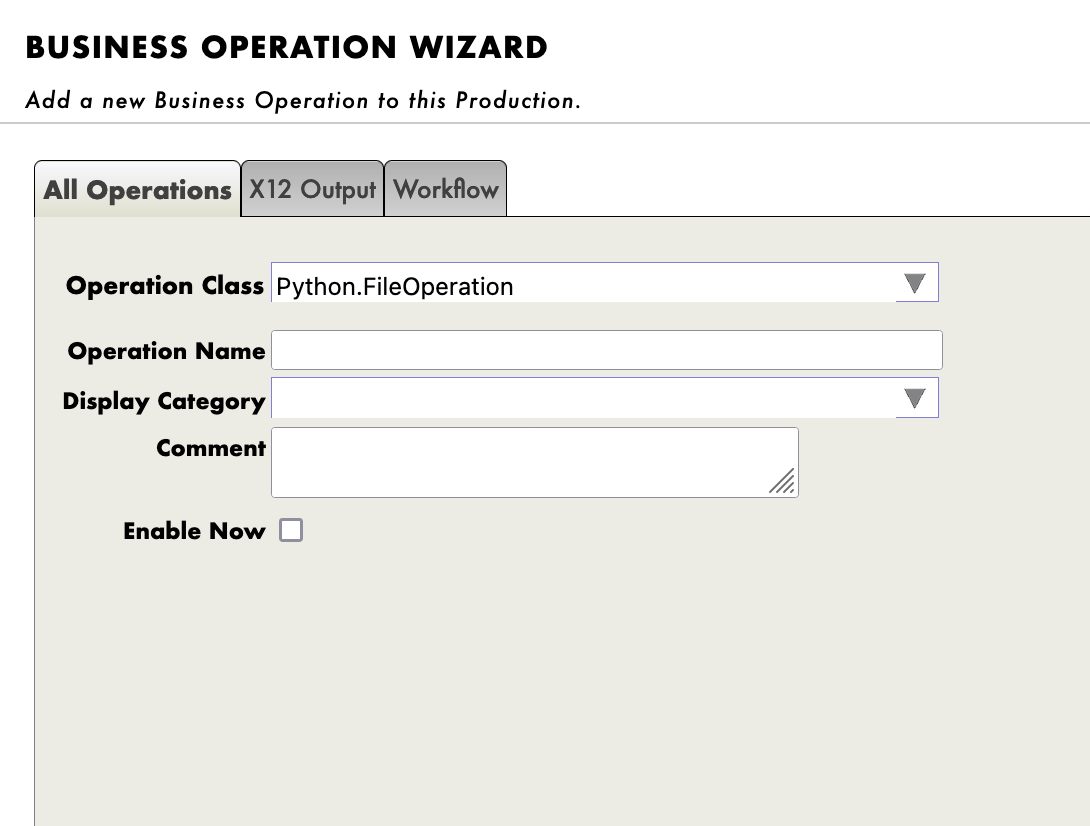
新しく作成したすべてのオペレーションに対して必ず実行してください!
オペレーションをダブルクリックすると、オペレーションが有効化されるか、再起動して変更内容が保存されます。
重要: この無効化して有効化し直す手順は、変更内容を保存する上で非常に重要な手順です。
重要: その後で、Python.IrisOperationオペレーションを選択し、右のサイドバーメニューの [Actions] タブに移動すると、オペレーションをテストすることができます。
(うまくいかない場合は、テストを有効化し、本番環境が開始していることを確認してから、本番環境をダブルクリックして再起動をクリックし、オペレーションをリロードしてください)。
IrisOperation については、テーブルは自動的に作成済みです。 情報までに、これを作成するには、管理ポータルを使用します。[System Explorer(システムエクスプローラー)] > [SQL] > [Go] に移動して、Iris データベースにアクセスします。 次に、[Execute Query(クエリを実行)] を開始します。
CREATE TABLE iris.training (
name varchar(50) NULL,
room varchar(50) NULL
)
管理ポータルのテスト機能を使用して、前に宣言したタイプのメッセージをオペレーションに送信します。 すべてがうまくいけば、仮想トレースを表示すると、プロセスとサービスとオペレーション間で何が起きたかを確認できるようになります。Request Type として使用した場合:
Grongier.PEX.Message
%classname として使用した場合:
msg.TrainingRequest
%json として使用した場合:
{
"training":{
"name": "name1",
"room": "room1"
}
}
ここでは、メッセージがプロセスによってオペレーションに送信され、オペレーションがレスポンス(空の文字列)を送り返すのを確認できます。
以下のような結果が得られます。 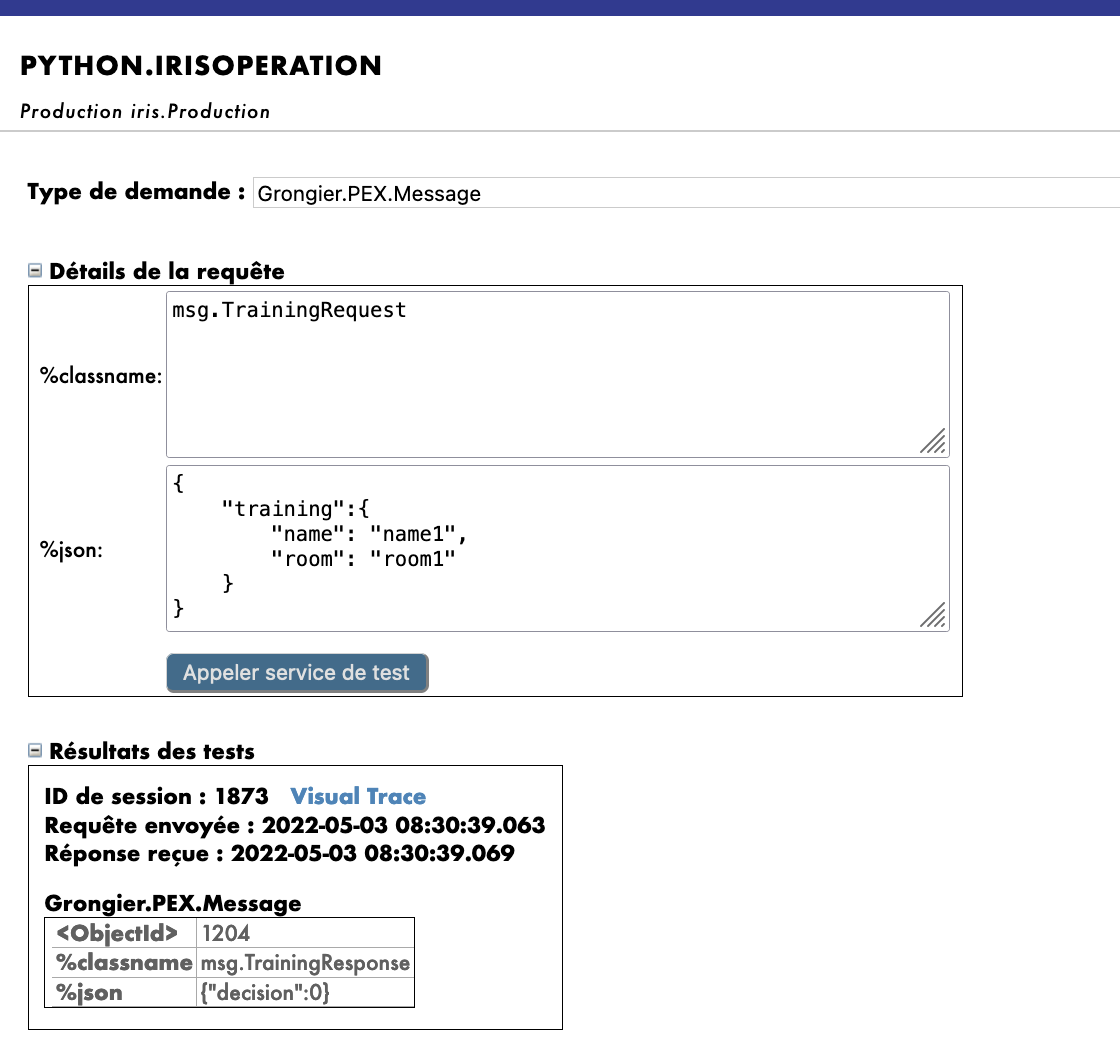
FileOperation については、以下のように管理ポータルの %settings に path を入力できます(7.3. の filename に関するメモに従った場合は、設定に filename を追加できます)。
path=/tmp/
filename=tata.csv
結果は以下のようになります。 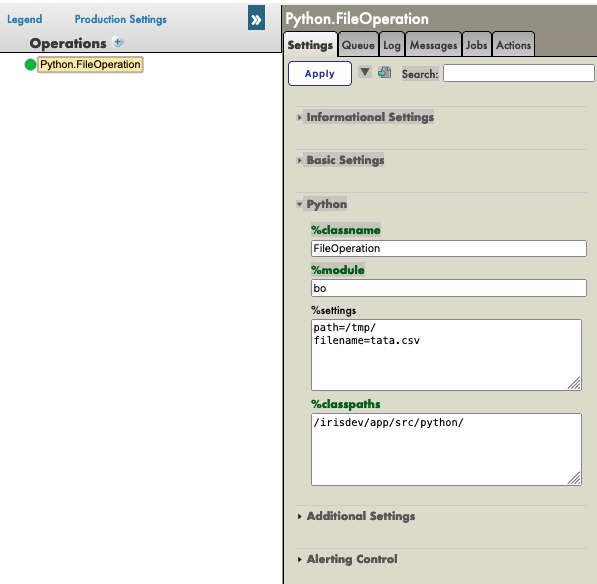
繰り返しますが、Python.FileOperationオペレーションを選択して、右サイドバーメニューの [Actions] タブに移動すると、オペレーションをテストできます。
(うまくいかない場合は、テストを有効化し、本番環境が起動していることを確認してください)。Request Type として使用した場合:
Grongier.PEX.Message
%classname として使用した場合:
msg.TrainingRequest
%json として使用した場合:
{
"training":{
"name": "name1",
"room": "room1"
}
}
結果は以下のようになります。 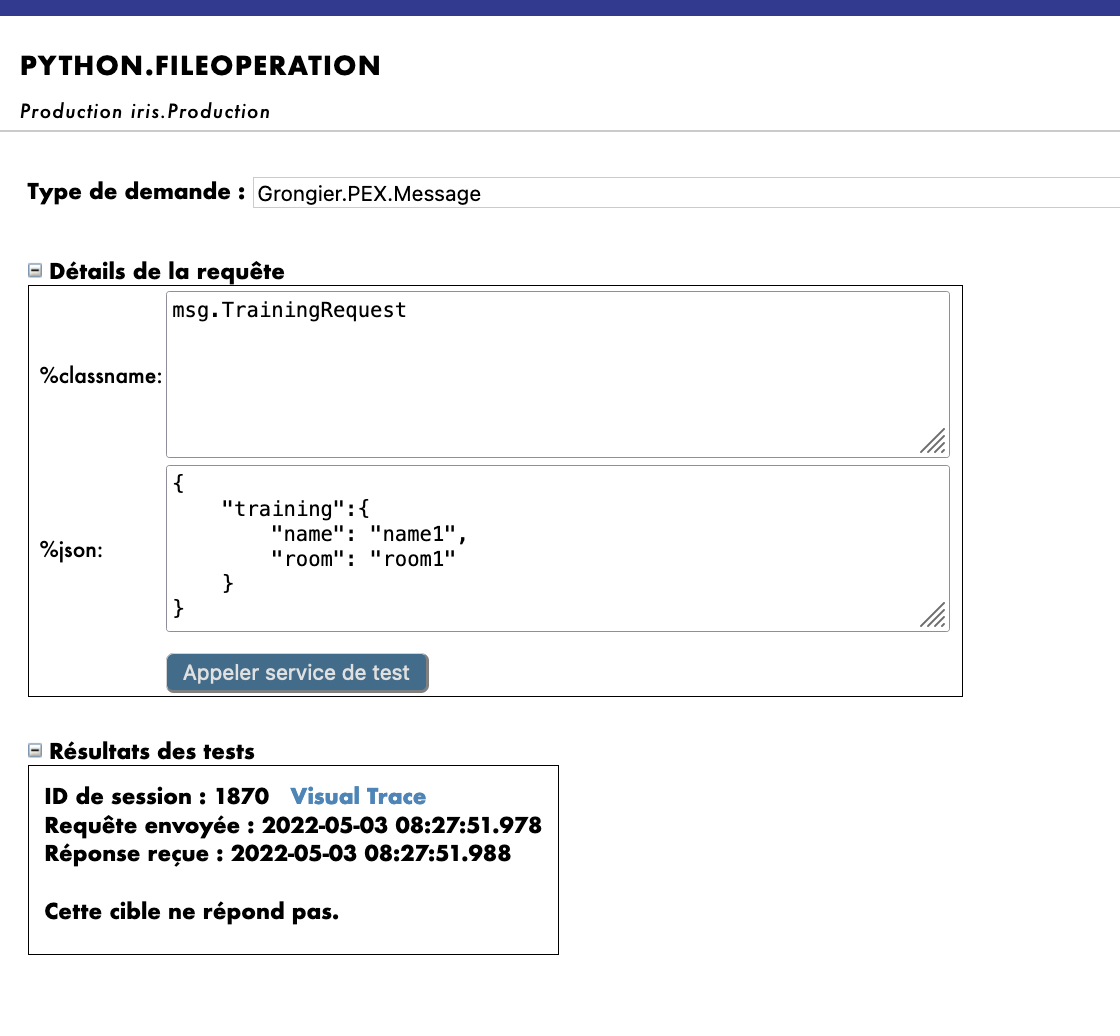
オペレーションが動作したかどうかを確認するには、toto.csv(7.3. の filename に関するメモに従った場合は tata.csv)ファイルと Iris データベースにアクセスして変更内容を確認する必要があります。
次の手順を実行するには、コンテナの中に移動する必要がありますが、5.2. と 5.3 を実行した場合には、省略できます。
toto.csv にアクセスするには、ターミナルを開いて、以下を入力する必要があります。
bash
cd /tmp
cat toto.csv
または、必要であれば "cat tata.csv" を使用してください。
重要: ファイルが存在しない場合、管理ポータルでオペレーションを再起動していない可能性があります。
再起動するには、オペレーションをクリックして再起動を選択してください(または、無効化してからもう一度ダブルクリックして有効化してください)。
もう一度テストする必要があります。
Iris データベースにアクセスするには、管理ポータルにアクセスし、[System Explorer(システムエクスプローラー)] > [SQL] > [Go] を選択する必要があります。 次に、[Execute Query(クエリを実行)] を開始します。
SELECT * FROM iris.training
ビジネスプロセス(BP)は、本番環境のビジネスロジックです。 リクエストをプロセスしたり、本番環境の他のコンポーネントにそのリクエストをリレーしたリするために使用されます。
BP には、インスタンスがソースからリクエストを受信するたびに呼び出される on_request 関数もあるため、情報を受信して処理し、正しい BO に送信することができます。
これらのプロセスは、VSCode でローカルに作成します。つまり、src/python/bp.py ファイルです。
このファイルを保存すると、IRIS でコンパイルされます。
サービスから受信する情報を処理し、適切に配信するビジネスプロセスを作成しましょう。 オペレーションを呼び出す単純な BP を作成することにします。
この BP は情報をリダイレクトするだけであるため、これを Router と呼び、src/python/bp.py に作成します。
インポート:
from grongier.pex import BusinessProcess
from msg import FormationRequest, TrainingRequest
from obj import Training
コード:
class Router(BusinessProcess):
def on_request(self, request):
"""
リクエストを受信し、フォーメーションリクエストであるかを確認し、そうである場合は
TrainingRequest リクエストを FileOperation と IrisOperation に送信します。IrisOperation が 1 を返すと、PostgresOperation に送信します。
:param request: 受信したリクエストオブジェクト
:return: None
"""
if isinstance(request,FormationRequest):
msg = TrainingRequest()
msg.training = Training()
msg.training.name = request.formation.nom
msg.training.room = request.formation.salle
self.send_request_sync('Python.FileOperation',msg)
self.send_request_sync('Python.IrisOperation',msg)
return None
Router は FormationRequest タイプのリクエストを受信し、TrainingRequest タイプのメッセージを作成して IrisOperation と FileOperation オペレーションに送信します。 メッセージ/リクエストが求めているタイプのインスタンスでない場合、何も行わず、配信しません。
これらのコンポーネントは、事前に本番環境に登録済みです。
情報までに、コンポーネントを登録する手順は、5.4. に従い、以下を使用します。
register_component("bp","Router","/irisdev/app/src/python/",1,"Python.Router")
プロセスは、こちらで事前に登録済みです。
ただし、プロセスを新規作成する場合は、手動で追加する必要があります。
今後の参考までに、プロセスの登録手順を説明します。
登録には、管理ポータルを使用します。 [Process] の横にある [+] 記号を押すと、[Business Process Wizard(ビジネスプロセスウィザード)] が開きます。
そのウィザードで、スクロールメニューから作成したばかりのプロセスクラスを選択します。
プロセスをダブルクリックすると、プロセスが有効化されるか、再起動して変更内容が保存されます。
重要: この無効化して有効化し直す手順は、変更内容を保存する上で非常に重要な手順です。
重要: その後で、プロセスを選択し、右のサイドバーメニューの [Actions] タブに移動すると、プロセスをテストすることができます。
(うまくいかない場合は、テストを有効化し、本番環境が開始していることを確認してから、本番環境をダブルクリックして再起動をクリックし、プロセスをリロードしてください)。
こうすることで、プロセスに msg.FormationRequest タイプのメッセージを送信します。 Request Type として使用した場合:
Grongier.PEX.Message
%classname として使用した場合:
msg.FormationRequest
%json として使用した場合:
{
"formation":{
"id_formation": 1,
"nom": "nom1",
"salle": "salle1"
}
}
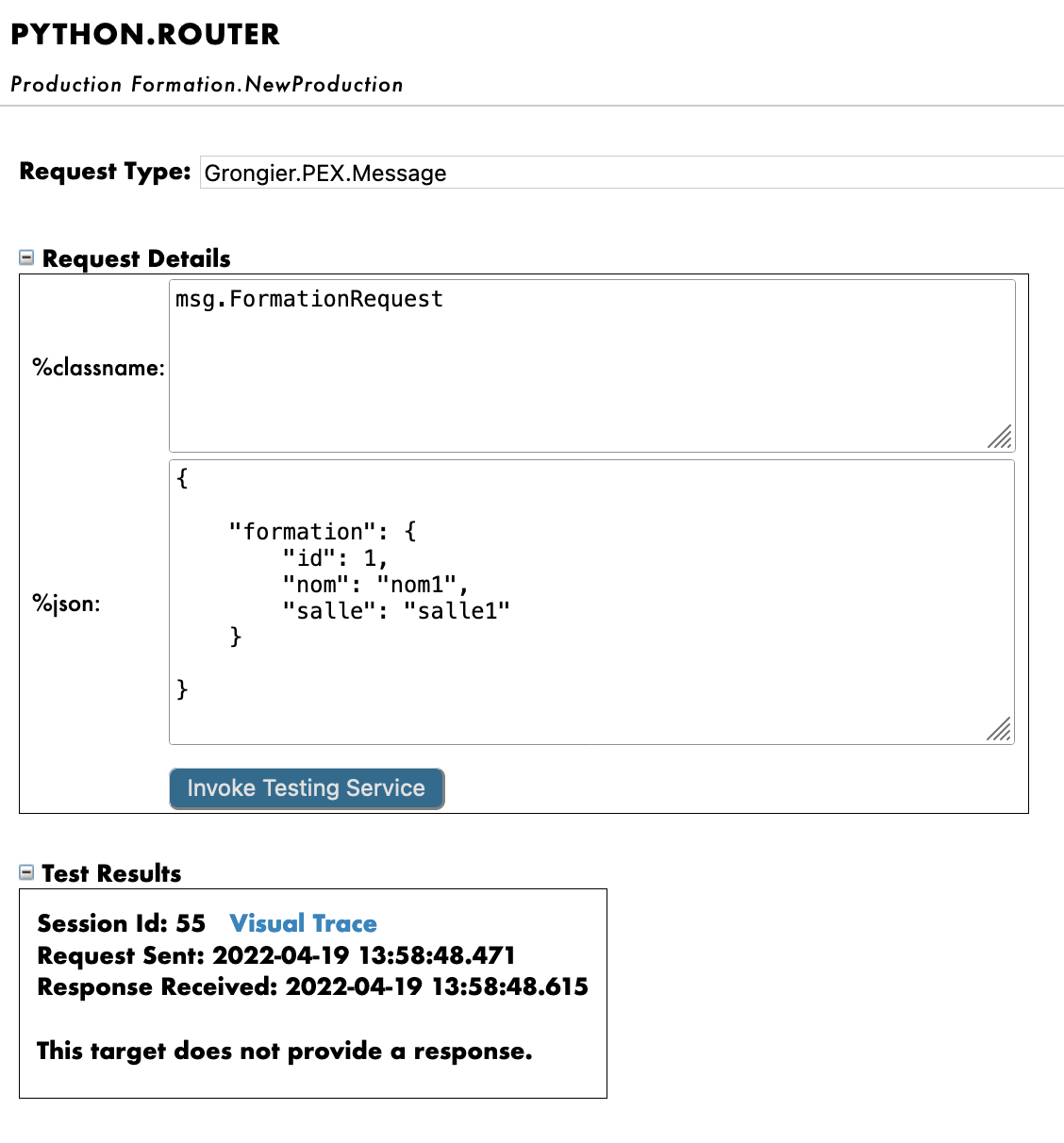
すべてがうまくいけば、仮想トレースを表示すると、プロセスとサービスとプロセス間で何が起きたかを確認できるようになります。
ここでは、メッセージがプロセスによってオペレーションに送信され、オペレーションがレスポンスを送り返すのを確認できます。 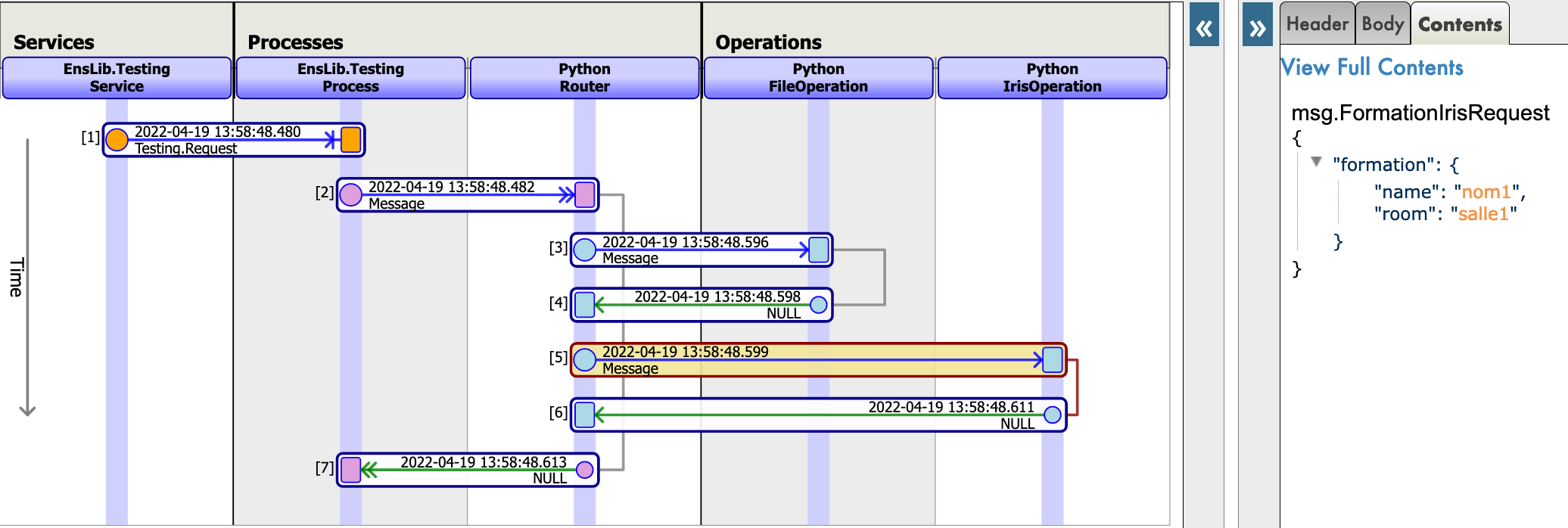
ビジネスサービス(BS)は、本番環境の中核です。 情報を収集し、ルーターに送信するために使用されます。 BS には、フレームワークの情報を頻繁に収集する on_process_input 関数もあるため、REST API やその他のサービス、またはサービス自体などの複数の方法で呼び出してサービスのコードをもう一度実行することが可能です。 BS には、クラスにアダプターを割り当てられる get_adapter_type 関数もあります。たとえば、Ens.InboundAdapter は、サービスがその on_process_input を 5 秒おきに呼び出すようにすることができます。
これらのサービスは、VSCode でローカルに作成します。つまり、python/bs.py ファイルです。
このファイルを保存すると、IRIS でコンパイルされます。
CSV を読み取って、msg.FormationRequest として各行をルーターに送信するビジネスサービスを作成しましょう。
この BS は csv を読み取るため、これを ServiceCSV と呼び、src/python/bs.py に作成します。
インポート:
from grongier.pex import BusinessService
from dataclass_csv import DataclassReader
from obj import Formation
from msg import FormationRequest
コード:
class ServiceCSV(BusinessService):
"""
csv ファイルを 5 秒おきに読み取り、メッセージとして各行を Python Router プロセスに送信します。
"""
def get_adapter_type():
"""
登録済みのアダプタ名
"""
return "Ens.InboundAdapter"
def on_init(self):
"""
現在のファイルパスをオブジェクトの path 属性に指定されたパスに変更します。
path 属性が指定されていない場合は '/irisdev/app/misc/' に変更します。
:return: None
"""
if not hasattr(self,'path'):
self.path = '/irisdev/app/misc/'
return None
def on_process_input(self,request):
"""
formation.csv ファイルを読み取り、各行のFormationRequest メッセージを作成し、
Python.Router プロセスに送信します。
:param request: リクエストオブジェクト
:return: None
"""
filename='formation.csv'
with open(self.path+filename,encoding="utf-8") as formation_csv:
reader = DataclassReader(formation_csv, Formation,delimiter=";")
for row in reader:
msg = FormationRequest()
msg.formation = row
self.send_request_sync('Python.Router',msg)
return None
FlaskService はそのままにし、ServiceCSV のみを入力することをお勧めします。
ご覧のとおり、ServiceCSV は、独立して機能し、5 秒おき(管理ポータルのサービスの設定にある基本設定で変更できるパラメーター)に on_process_input を呼び出せるようにする InboundAdapter を取得します。
サービスは、5 秒おきに formation.csv を開き、各行を読み取って、Python.Router に送信される msg.FormationRequest を作成します。
これらのコンポーネントは、事前に本番環境に登録済みです。
情報までに、コンポーネントを登録する手順は、5.4. に従い、以下を使用します。
register_component("bs","ServiceCSV","/irisdev/app/src/python/",1,"Python.ServiceCSV")
サービスは、こちらで事前に登録済みです。
ただし、サービスを新規作成する場合は、手動で追加する必要があります。
今後の参考までに、サービスの登録手順を説明します。
登録には、管理ポータルを使用します。 [service] の横にある [+] 記号を押すと、[Business Service Wizard(ビジネスサービスウィザード)] が開きます。
そのウィザードで、スクロールメニューから作成したばかりのサービスクラスを選択します。
サービスをダブルクリックすると、サービスが有効化されるか、再起動して変更内容が保存されます。
重要: この無効化して有効化し直す手順は、変更内容を保存する上で非常に重要な手順です。
前に説明したように、サービスは 5 秒おきに自動的に開始するため、ここでは他に行うことはありません。
すべてがうまくいけば、視覚的トレースを表示すると、プロセスとサービスとプロセス間で何が起きたかを確認することができます。
ここでは、メッセージがサービスによってプロセスに送信され、プロセスによってオペレーションに送信され、オペレーションがレスポンスを送り返すのを確認できます。 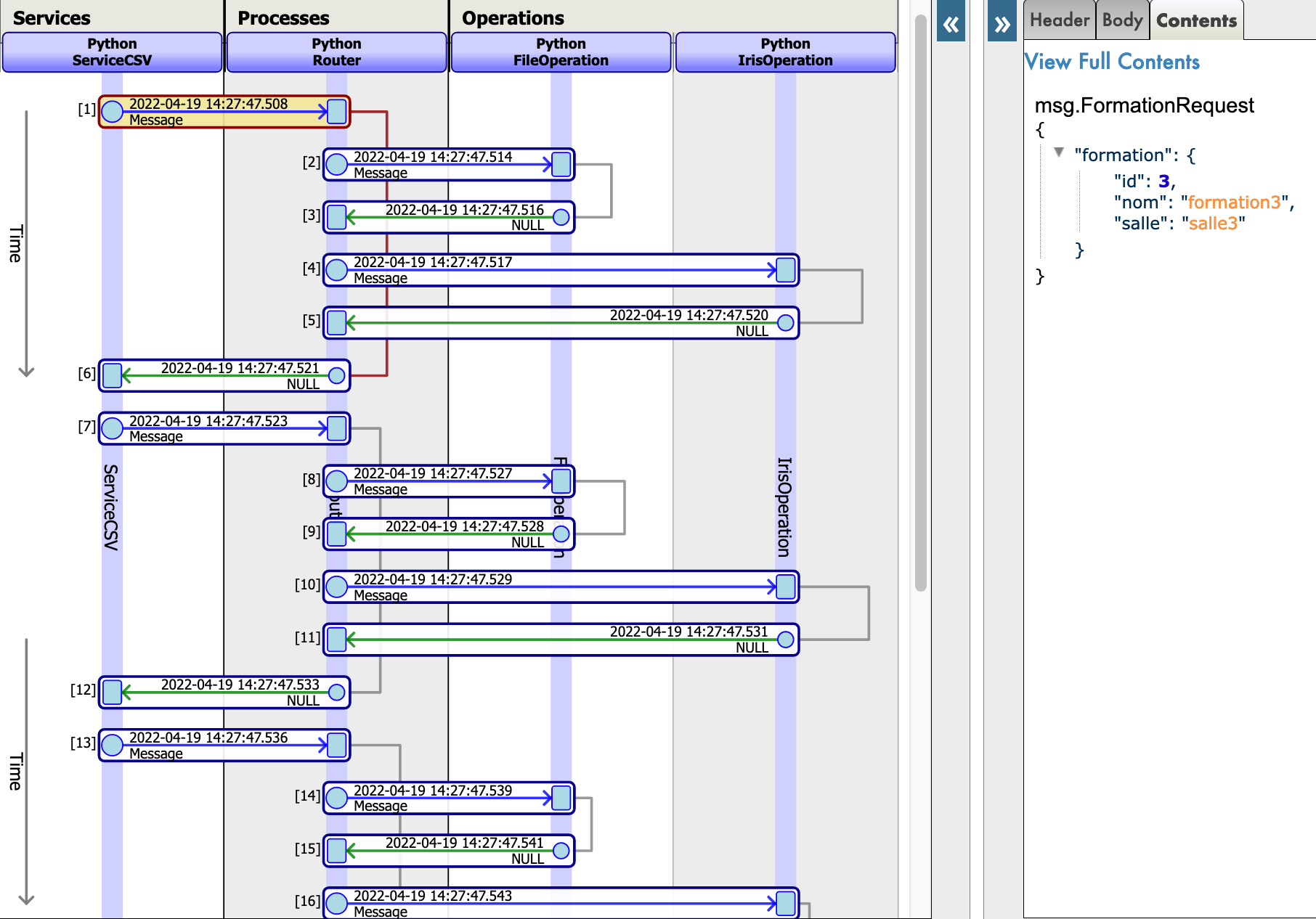
このセクションでは、外部データベースにオブジェクトを保存するオペレーションを作成します。 db-api を使用し、その他の Docker コンテナをセットアップして Postgres を設定します。
Postgres を使用するには psycopg2 が必要です。これは、単純なコマンドで Postgres データベースに接続できるようにする Python モジュールです。
これは自動的に完了済みですが、情報までに説明すると、Docker コンテナにアクセスし、pip3 を使って psycopg2 をインストールします。
ターミナルを開始したら、以下を入力します。
pip3 install psycopg2-binary
または、requirements.txt にモジュールを追加して、コンテナを再構築できます。
新しいオペレーションは、src/python/bo.py ファイルの他の 2 つのオペレーションの後に追加してください。 以下は、新しいオペレーションとインポートです。
インポート:
import psycopg2
コード:
class PostgresOperation(BusinessOperation):
"""
トレーニングを Postgres データベースに書き込むオペレーションです。
"""
def on_init(self):
"""
Postgres データベースに接続して接続オブジェクトを初期化する関数です。
:return: None
"""
self.conn = psycopg2.connect(
host="db",
database="DemoData",
user="DemoData",
password="DemoData",
port="5432")
self.conn.autocommit = True
return None
def on_tear_down(self):
"""
データベースへの接続を閉じます。
:return: None
"""
self.conn.close()
return None
def insert_training(self,request:TrainingRequest):
"""
トレーニングを Postgre データベースに挿入します。
:param request: 関数に渡されるリクエストオブジェクト
:type request: TrainingRequest
:return: None
"""
cursor = self.conn.cursor()
sql = "INSERT INTO public.formation ( name,room ) VALUES ( %s , %s )"
cursor.execute(sql,(request.training.name,request.training.room))
return None
def on_message(self,request):
return None
このオペレーションは、最初に作成したオペレーションに似ています。 msg.TrainingRequest タイプのメッセージを受信すると、psycopg モジュールを使用して、SQL リクエストを実行します。 これらのリクエストは、Postgres データベースに送信されます。
ご覧のとおり、接続はコードに直接書き込まれています。コードを改善するために、他のオペレーションで前に行ったようにし、host、database、およびその他の接続情報を変数にすることができます。基本値を db や DemoData にし、管理ポータルで直接変更できるようにします。
これを行うには、以下のようにして on_init を変更します。
def on_init(self):
if not hasattr(self,'host'):
self.host = 'db'
if not hasattr(self,'database'):
self.database = 'DemoData'
if not hasattr(self,'user'):
self.user = 'DemoData'
if not hasattr(self,'password'):
self.password = 'DemoData'
if not hasattr(self,'port'):
self.port = '5432'
self.conn = psycopg2.connect(
host=self.host,
database=self.database,
user=self.user,
password=self.password,
port=self.port)
self.conn.autocommit = True
return None
これらのコンポーネントは、事前に本番環境に登録済みです。
情報までに、コンポーネントを登録する手順は、5.4. に従い、以下を使用します。
register_component("bo","PostgresOperation","/irisdev/app/src/python/",1,"Python.PostgresOperation")
オペレーションは、こちらで事前に登録済みです。
ただし、オペレーションを新規作成する場合は、手動で追加する必要があります。
今後の参考までに、オペレーションの登録手順を説明します。
登録には、管理ポータルを使用します。 [Operations] の横にある [+] 記号を押すと、[Business Operation Wizard(ビジネスオペレーションウィザード)] が開きます。
そのウィザードで、スクロールメニューから作成したばかりのオペレーションクラスを選択します。
その後、接続を変更する場合は、オペレーションの [parameter] ウィンドウで、[Python] の %settings に変更するパラメーターを追加すれば完了です。 詳細については、「7.5 テスト」の 2 つ目の画像をご覧ください。
オペレーションをダブルクリックすると、オペレーションが有効化されるか、再起動して変更内容が保存されます。
重要: この無効化して有効化し直す手順は、変更内容を保存する上で非常に重要な手順です。
重要: その後で、オペレーションを選択し、右のサイドバーメニューの [Actions] タブに移動すると、オペレーションをテストすることができます。
(うまくいかない場合は、テストを有効化し、本番環境が開始していることを確認してから、本番環境をダブルクリックして再起動をクリックし、オペレーションをリロードしてください)。
PostGresOperation については、テーブルは自動的に作成済みです。
こうすることで、オペレーションに msg.TrainingRequest タイプのメッセージを送信します。 Request Type として使用した場合:
Grongier.PEX.Message
%classname として使用した場合:
msg.TrainingRequest
%json として使用した場合:
{
"training":{
"name": "nom1",
"room": "salle1"
}
}
以下のとおりです。 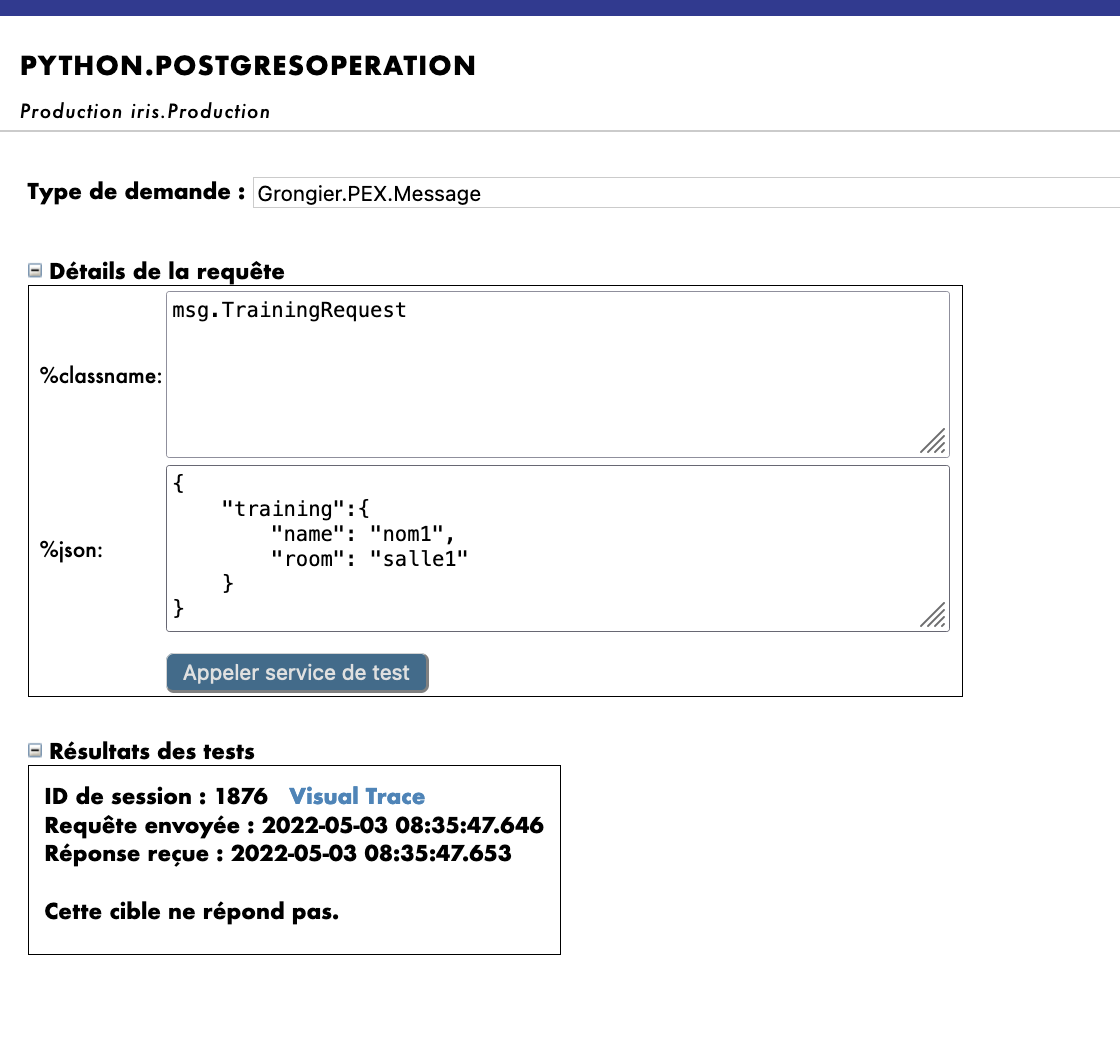
仮想トレースをテストすると、成功が表示されます。
これで、外部データベースに接続することができました。
ここまで、ここに記載の情報に従ってきた場合、プロセスやサービスは新しい PostgresOperation を呼び出さない、つまり、管理ポータルのテスト機能を使用しなければ呼び出されないことを理解していることでしょう。
演習として、bo.IrisOperation がブール値を返すように変更し、そのブール値に応じて bp.Router に bo.PostgresOperation を呼び出すようにしてみましょう。
そうすることで、ここで新しく作成したオペレーションが呼び出されるようになります。
ヒント: これは、bo.IrisOperation レスポンスの戻り値のタイプを変更し、新しいメッセージ/レスポンスタイプに新しいブール値プロパティを追加して、bp.Router に if 操作を使用すると実現できます。
まず、bo.IrisOperation からのレスポンスが必要です。 src/python/msg.py の他の 2 つのメッセージの後に、以下のようにして新しいメッセージを作成します。
コード:
@dataclass
class TrainingResponse(Message):
decision:int = None
次に、そのレスポンスによって、bo.IrisOperation のレスポンスを変更し、decision の値を 1 または 0 にランダムに設定します。src/python/bo.py で 2 つのインポートを追加し、IrisOperation クラスを変更する必要があります。
インポート:
import random
from msg import TrainingResponse
コード:
class IrisOperation(BusinessOperation):
"""
トレーニングを iris データベースに書き込むオペレーションです。
"""
def insert_training(self, request:TrainingRequest):
"""
`TrainingRequest` オブジェクトを取り、新しい行を`iris.training` テーブルに挿入し、
`TrainingResponse` オブジェクトを返します。
:param request: 関数に渡されるリクエストオブジェクト
:type request: TrainingRequest
:return: A TrainingResponse message
"""
resp = TrainingResponse()
resp.decision = round(random.random())
sql = """
INSERT INTO iris.training
( name, room )
VALUES( ?, ? )
"""
iris.sql.exec(sql,request.training.name,request.training.room)
return resp
def on_message(self, request):
return None
class Router(BusinessProcess):
def on_request(self, request):
"""
リクエストを受け取り、フォーメーションリクエストであるかどうかをチェックします。
その場合は、TrainingRequest リクエストを FileOperation と IrisOperation に送信し、IrisOperation が 1 を返すと PostgresOperation に送信します。
:param request: 受信したリクエストオブジェクト
:return: None
"""
if isinstance(request,FormationRequest):
msg = TrainingRequest()
msg.training = Training()
msg.training.name = request.formation.nom
msg.training.room = request.formation.salle
self.send_request_sync('Python.FileOperation',msg)
form_iris_resp = self.send_request_sync('Python.IrisOperation',msg)
if form_iris_resp.decision == 1:
self.send_request_sync('Python.PostgresOperation',msg)
return None
非常に重要: オペレーションの呼び出しには、send_request_async ではなく、必ず send_request_sync を使用する必要があります。そうでない場合、この操作はブール値のレスポンスを受け取る前に実行されます。
テストする前に、必ず変更したすべてのサービス、プロセス、およびオペレーションをダブルクリックして再起動してください。これを行わない場合、変更内容は適用されません。
テスト後、視覚的トレースで、csv で読み取られたおよそ半数のオブジェクトがリモートデータベースにも保存されていることがわかります。bs.ServiceCSV を開始するだけでテストできることに注意してください。リクエストは自動的にルーターに送信され、適切に配信されます。
また、サービス、オペレーション、またはプロセスをダブルクリックしてリロードを押すか、VSCode で保存した変更を適用するには再起動を押す必要があることにも注意してください。
ここでは、REST サービスを作成して使用します。
Flask を使用するには、flask のインストールが必要です。これは、REST サービスを簡単に作成できるようにする Python モジュールです。 これは、自動的に実行済みですが、今後の情報までに説明すると、Docker コンテナ内にアクセスして iris python に flask をインストールします。 ターミナルを開始したら、以下を入力します。
pip3 install flask
または、requirements.txt にモジュールを追加して、コンテナを再構築できます。
REST サービスを作成するには、API を本番環境にリンクするサービスが必要です。このために、src/python/bs.py の ServiceCSV クラスの直後に新しい単純なサービスを作成します。
class FlaskService(BusinessService):
def on_init(self):
"""
API の現在のターゲットをオブジェクトの target 属性に指定されたターゲットに変更します。
または、target 属性が指定されていない場合は 'Python.Router' に変更します。
:return: None
"""
if not hasattr(self,'target'):
self.target = "Python.Router"
return None
def on_process_input(self,request):
"""
API から直接 Python.Router プロセスに情報を送信するために呼び出されます。
:return: None
"""
return self.send_request_sync(self.target,request)
このサービスに on_process_input を行うと、リクエストが Router に転送されます。
これらのコンポーネントは、事前に本番環境に登録済みです。
情報までに、コンポーネントを登録する手順は、5.4. に従い、以下を使用します。
register_component("bs","FlaskService","/irisdev/app/src/python/",1,"Python.FlaskService")
REST サービスを作成するには、Flask を使って get と post 関数を管理する API を作成する必要があります。 新しいファイルを python/app.py として作成してください。
from flask import Flask, jsonify, request, make_response
from grongier.pex import Director
import iris
from obj import Formation
from msg import FormationRequest
app = Flask(__name__)
# GET Infos
@app.route("/", methods=["GET"])
def get_info():
info = {'version':'1.0.6'}
return jsonify(info)
# GET all the formations
@app.route("/training/", methods=["GET"])
def get_all_training():
payload = {}
return jsonify(payload)
# POST a formation
@app.route("/training/", methods=["POST"])
def post_formation():
payload = {}
formation = Formation()
formation.nom = request.get_json()['nom']
formation.salle = request.get_json()['salle']
msg = FormationRequest(formation=formation)
service = Director.CreateBusinessService("Python.FlaskService")
response = service.dispatchProcessInput(msg)
return jsonify(payload)
# GET formation with id
@app.route("/training/<int:id>", methods=["GET"])
def get_formation(id):
payload = {}
return jsonify(payload)
# PUT to update formation with id
@app.route("/training/<int:id>", methods=["PUT"])
def update_person(id):
payload = {}
return jsonify(payload)
# DELETE formation with id
@app.route("/training/<int:id>", methods=["DELETE"])
def delete_person(id):
payload = {}
return jsonify(payload)
if __name__ == '__main__':
app.run('0.0.0.0', port = "8081")
Flask API は Director を使用して、前述のものから FlaskService のインスタンスを作成してから適切なリクエストを送信することに注意してください。
上記の子k-度では、POST フォーメンション関数を作成しました。希望するなら、これまでに学習したものすべてを使用して、適切な情報を get/post するように、他の関数を作成することが可能です。ただし、これに関するソリューションは提供されていません。
Python Flask を使用して flask アプリを開始しましょう。
最後に、Router サービスをリロードしてから、任意の REST クライアントを使用してサービスをテストできます。
(Mozilla の RESTer として)REST サービスを使用するには、以下のようにヘッダーを入力する必要があります。
Content-Type : application/json
ボディは以下のようになります。
{
"nom":"testN",
"salle":"testS"
}
認証は以下のとおりです。
ユーザー名:
SuperUser
パスワード:
SYS
最後に、結果は以下のようになります。 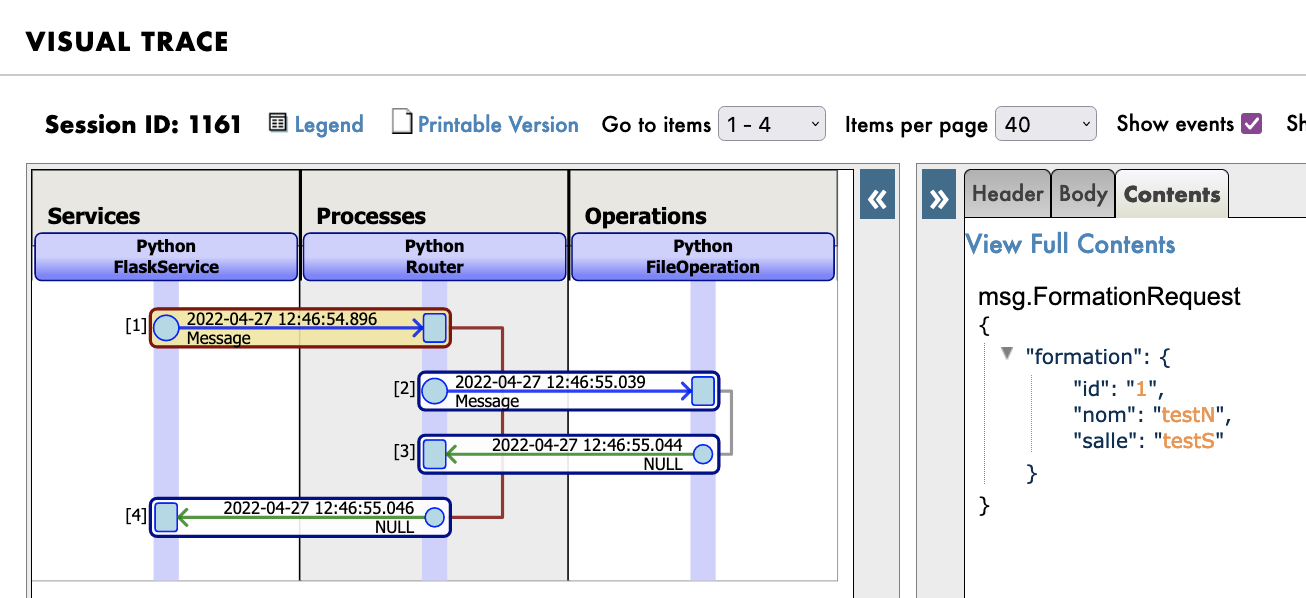
Iris DataPlatform とそのフレームワークのすべての重要な概念について学習したので、グローバル演習で腕試しをしましょう。この演習では、新しい BS と BP を作成し、BO を大きく変更して、新しい概念を Python で探ります。
こちらのエンドポイントhttps://lucasenard.github.io/Data/patients.json を使用して、患者と歩数に関する情報を自動的に取得するようにします。 次に、ローカルの csv ファイルに書き込む前に、各患者の平均歩数を計算します。
必要であれば、フォーメーション全体または必要な箇所を読むか、以下のヒントを使って、ガイダンスを得ることをお勧めします。
管理ポータルでコンポーネントにアクセスできるように、コンポーネントの登録を忘れずに行いましょう。
すべてを完了し、テストしたら、または演習を完了するのに十分なヒントを得られなかった場合は、全過程をステップごとに説明したソリューションをご覧ください。
ここでは、演習を行うためのヒントを紹介します。
読んだ分だけヒントが得られてしまうため、必要な箇所のみを読み、毎回すべてを読まないようにすることをお勧めします。
たとえば、bs の「情報の取得」と「リクエストによる情報の取得」のみを読み、他は読まないようにしましょう。
エンドポイントから情報を取得するには、Python の requests モジュールを検索し、json と json.dumps を使用して文字列に変換してから bp に送信します。
オンライン Python Web サイトまたはローカルの Python ファイルを使用してリクエストを使用し、取得した内容をさらに深く理解するために、出力とそのタイプを出力します。
新しいメッセージタイプと情報を保持するオブジェクトタイプを作成し、プロセスに送信して平均を計算します。
リクエストを使用してデータを取得する方法と、この場合に部分的に、それをどう処理するかに関するソリューションです。
r = requests.get(https://lucasenard.github.io/Data/patients.json)
data = r.json()
for key,val in data.items():
...
繰り返しますが、オンライン Python Web サイトまたはローカルの Python ファイルでは、key、val、およびタイプを出力し、それらを使用して何をできるかを理解することが可能です。json.dumps(val) を使用して val を格納してから、SendRequest の後にプロセスにいるときに、json.loads(request.patient.infos) を使用してその val を取得します(val の情報を patient.infos に格納した場合)。
statistics は、算術演算を行うために使用できるネイティブライブラリです。
Python のネイティブ map 関数では、たとえばリスト内または辞書内の情報を分離することができます。
list ネイティブ関数を使用して、map の結果をリストに変換し直すことを忘れないようにしましょう。
オンライン Python Web サイトまたはローカルの Python ファイルを使用して、以下のように、リストのリストまたは辞書のリストの平均を計算することができます。
l1 = [[0,5],[8,9],[5,10],[3,25]]
l2 = [["info",12],["bidule",9],[3,3],["patient1",90]]
l3 = [{"info1":"7","info2":0},{"info1":"15","info2":0},{"info1":"27","info2":0},{"info1":"7","info2":0}]
#最初のリストの最初の列の平均(0/8/5/3)
avg_l1_0 = statistics.mean(list(map(lambda x: x[0]),l1))
#最初のリストの 2 つ目列の平均(5/9/10/25)
avg_l1_1 = statistics.mean(list(map(lambda x: x[1]),l1))
#12/9/3/90 の平均
avg_l2_1 = statistics.mean(list(map(lambda x: x[1]),l2))
#7/15/27/7 の平均
avg_l3_info1 = statistics.mean(list(map(lambda x: int(x["info1"])),l3))
print(avg_l1_0)
print(avg_l1_1)
print(avg_l2_1)
print(avg_l3_info1)
リクエストに、日付と歩数の dict の json.dumps である infos 属性を持つ患者が保持されている場合、以下のようにして平均歩数を計算できます。
statistics.mean(list(map(lambda x: int(x['steps']),json.loads(request.patient.infos))))
bo.FileOperation.WriteFormation に非常に似たものを使用できます。
bo.FileOperation.WritePatient のようなものです。
obj.py に以下を追加できます。
@dataclass
class Patient:
name:str = None
avg:int = None
infos:str = None
msg.py に以下を追加できます。
インポート:
from obj import Formation,Training,Patient
コード:
@dataclass
class PatientRequest(Message):
patient:Patient = None
この情報を単一の obj に保持し、get リクエストから得る dict の str を直接 infos 属性に入れます。 平均は、プロセスで計算されます。
bs.py に以下を追加できます。 インポート:
import requests
コード:
class PatientService(BusinessService):
def get_adapter_type():
"""
登録されたアダプタの名前
"""
return "Ens.InboundAdapter"
def on_init(self):
"""
API の現在のターゲットをオブジェクトの target 属性に指定されたターゲットに変更します。
target 属性が指定されていない場合は、'Python.PatientProcess' に変更します。
API の現在の api_url をオブジェクトの taget 属性に指定された api_url に変更します。
api_url 属性が指定されていない場合は、'https://lucasenard.github.io/Data/patients.json' に変更します。
:return: None
"""
if not hasattr(self,'target'):
self.target = 'Python.PatientProcess'
if not hasattr(self,'api_url'):
self.api_url = "https://lucasenard.github.io/Data/patients.json"
return None
def on_process_input(self,request):
"""
API にリクエストを行い、検出される患者ごとに Patient オブジェクトを作成し、
ターゲットに送信します。
:param request: サービスに送信されたリクエスト
:return: None
"""
req = requests.get(self.api_url)
if req.status_code == 200:
dat = req.json()
for key,val in dat.items():
patient = Patient()
patient.name = key
patient.infos = json.dumps(val)
msg = PatientRequest()
msg.patient = patient
self.send_request_sync(self.target,msg)
return None
ターゲットと api url 変数を作成します(on_init を参照)。requests.get が req 変数に情報を入れた後、json で情報を抽出する必要があります。これにより dat が dict になります。
dat.items を使用して、患者とその情報を直接イテレートできます。
次に、patient オブジェクトを作成し、json データを文字列に変換する json.dumps を使用して val を文字列に変換し、patient.infos 変数に入れます。
次に、プロセスを呼び出す msg.PatientRequest の msg リクエストを作成します。
コンポーネントの登録を忘れずに行いましょう。 5.4. に従い、以下を使用します。
register_component("bs","PatientService","/irisdev/app/src/python/",1,"Python.PatientService")
bp.py に以下を追加できます。 インポート:
import statistic
コード:
class PatientProcess(BusinessProcess):
def on_request(self, request):
"""
リクエストを取り、PatientRequest であるかをチェックします。その場合は、患者の平均歩数を計算し、
リクエストを Python.FileOperation サービスに送信します。
:param request: サービスに送信されたリクエストオブジェクト
:return: None
"""
if isinstance(request,PatientRequest):
request.patient.avg = statistics.mean(list(map(lambda x: int(x['steps']),json.loads(request.patient.infos))))
self.send_request_sync('Python.FileOperation',request)
return None
取得したばかりのリクエストを取り、PatientRequest である場合は、歩数の平均を計算して、FileOperation に送信します。 これは患者の avg 変数に正しい情報を挿入します(詳細は、bp のヒントを参照してください)。
コンポーネントの登録を忘れずに行いましょう。 5.4. に従い、以下を使用します。
register_component("bp","PatientProcess","/irisdev/app/src/python/",1,"Python.PatientProcess")
bo.py に以下を追加できます。FileOperation クラス内:
def write_patient(self, request:PatientRequest):
"""
患者の名前と平均歩数をファイルに書き込みます。
:param request: リクエストメッセージ
:type request: PatientRequest
:return: None
"""
name = ""
avg = 0
if request.patient is not None:
name = request.patient.name
avg = request.patient.avg
line = name + " avg nb steps : " + str(avg) +"\n"
filename = 'Patients.csv'
self.put_line(filename, line)
return None
前に説明したとおり、FileOperation は以前に登録済みであるため、もう一度登録する必要はありません。
7.4. を参照して、オペレーションを追加しましょう。
9.2. を参照して、サービスを追加しましょう。
次に、管理ポータルに移動し、前と同じように行います。 新しいサービスは、InboundAdapter を追加したため、自動的に実行されます。
toto.csv と同様にして、Patients.csv を確認してください。
この演習を通じて、メッセージ、サービス、プロセス、およびオペレーションの作成を学習し、理解することができました。
Python で情報をフェッチする方法とデータに対して単純なタスクを実行する方法を発見しました。
すべての完成ファイルは、GitHub の solution ブランチにあります。
このフォーメーションを通じ、csv ファイルから行を読み取り、読み取ったデータを db-api を使ってローカル txt、IRIS データベース、および外部データベースに保存できる IrisPython のみを使用して、フル機能の本番環境を作成しました。
また、POST 動詞を使用して新しいオブジェクトを保存する REST サービスも追加しました。
InterSystems のインターオペラビリティフレームワークの主要要素を発見しました。
これには、Docker、VSCode、および InterSystems の IRIS 管理ポータルを使用して実行しました。
これは InterSystems FAQ サイトの記事です。
メモ:xxx にはネームスペース名が入ります。
xxxENSTEMPは、プロダクション実行中に作成される一時データが保存されるデータベースです。
^IRIS.Temp.Ens* のグローバルがこのデータベースにマッピングされています。なお、xxxENSTEMPはジャーナルにかかれない設定のデータベースです。
xxxSECONDARYは、プロダクションで使用される資格情報を保存するデータベースです。
^Ens.SecondaryData* のグローバルがこのデータベースにマッピングされています。
注意:InterSystems IRIS for Health、HealthShare ではこれらデータベースは作成されません
詳細は以下ドキュメントをご覧下さい。
InterSystems IRIS の一時プロダクション・データの格納場所
InterSystems IRIS のパスワード資格情報の格納場所
関連する記事もご参照ください。
これは、InterSystems FAQ サイト の記事です。
1つのインスタンスで作成可能なネームスペース数の上限は、2048個になります。
ただし多数のネームスペースを使用するには、それに合わせてメモリの設定が必要になります。使用するメモリの設定については下記の関連トピックご参照ください。
管理ポータルのメモリ関連設定項目について
また1つのインスタンスに作成可能なデータベース数(リモートデータベースを含む)の上限は、15998個になります。
なおライセンスの種類によっては、作成可能な数に制限が設けられています。
詳細については、以下ドキュメントをご参照ください。
ドキュメント:ネームスペースの構成
ドキュメント:ローカル・データベースの構成
開発者のみなさん、こんにちは!
2022年3月9日開催「InterSystems Japan Virtual Summit 2022」のセッション「ストレージの節約手法について」のアーカイブを YouTube に公開いたしました。
(プレイリストはこちら)
データベースの構成要素であるデーターベースファイル、ジャーナルファイルに関するストレージ容量の増大を招く要因とその解決策、そしてこれら要素に関わる新機能についてもご説明します。
ストレージのコスト管理が重要なクラウド環境で特に有用な情報です。
ぜひ動画をご参照ください。
【目次】
00:58 ストレージコスト削減に成功されたお客様事例のご紹介
02:24 ディスクの使用状況を詳しく見る
04:57 ストレージコストの節約(=ストレージの節約)のための方法
15:44 ジャーナルのコスト削減(=ストレージの削減)
23:24 今後リリース予定の新機能について
これは、InterSystems FAQサイトの記事です。
システムユーティリティクラス:SYS.Database のクエリ:FreeSpace を利用してディスクの空き容量を任意のタイミングで確認することができます。
IRIS ターミナルで試す方法は以下の通りです(%SYSネームスペースに移動してから実行します)。
zn "%SYS"
set stmt=##class(%SQL.Statement).%New()
set st=stmt.%PrepareClassQuery("SYS.Database","FreeSpace")
set rset=stmt.%Execute()
//全件一括表示
do rset.%Display()出力結果例は以下の通りです。
※コマンド実行例では、全データベースが同じディスクに置かれているので、ディスクの空き容量(DiskFreeSpace)はすべて同じ値が返っています。
これは、InterSystems FAQサイトの記事です。
データベースの空き容量は、システムモニタを使用して監視することができます。
システムモニタは、システム開始時に自動開始され、予め設定された閾値に対してアラートが通知されます。
システムの閾値については以下ドキュメントをご参照ください。
システム・モニタのステータスおよびリソース・メトリック【IRIS】
システム・モニタのステータスおよびリソース・メトリック
データベースの空き容量については、システムデフォルトでは 50 MBを下回る場合にアラートが通知され、メッセージログ(コンソールログ)にアラート(深刻度 2)として記録され、alerts.log ファイルにも出力されます。
データベースの空き容量を任意サイズで監視したい場合、システムモニタに含まれる「アプリケーションモニタ」を利用して設定します。
注意:アプリケーションモニタでは、アラート対象となる情報があってもメッセージログ(コンソールログ)に出力しないため、メール通知/メソッド実行 を使用して通知するように設定します。
例えば、空き容量が 100MB を下回った時にアラートを通知したい場合は、アプリケーションモニタが提供する %Monitor.System.Sample.Freespace(空き容量メトリック)を利用します。
開発者の皆さん、こんにちは!
InterSystems データセットコンテスト の投票結果が発表されました!この記事ではコンテスト受賞者を発表します!

受賞された開発者の皆さん、👏おめでとうございます!🎊
開発者の皆さん、こんにちは!
今週から データセットコンテスト の投票が始まります!
InterSystems IRIS を使い開発されたベストソリューションにぜひ、投票をお願いします!
🔥 投票はこちらから! 🔥

投票方法については、以下ご参照ください。
開発者の皆さん、こんにちは!
InterSystems IRIS 2021.2 Preview 版 がリリースされました。新しい機能として LOAD DATA があります。
ということで、今回のコンテストでは、この新しい「LOAD DATA」をテストするコンテストにしてみたいと思います!
🏆 InterSystems Datasets Contest 🏆
応募期間: 2021年12月27日~2022年1月9日
💰 賞金総額: $9,450 💰

これは、InterSystems FAQサイトの記事です。
グローバル単位でジャーナルのON/OFF設定を行いたい場合は、グローバルマッピング設定で、
・ジャーナルしたいグローバル ⇒ ジャーナルON(「はい」)のデータベースにマッピング
・ジャーナルしたくないグローバル ⇒ ジャーナルOFF(「いいえ」)のデータベースにマッピング
と、分けることで可能です。 但し、通常のデータベースは、ジャーナルOFF設定であっても、トランザクション中の更新についてはジャーナルファイルに記録されます。
一時グローバルを保存するIRISTEMP/CACHETEMPデータベースは、トランザクション中でもジャーナルファイルに記録されませんので、トランザクションデータもジャーナル記録したくない場合にはこれをマッピング先にすることも可能です。
但し、IRISTEMP/CACHETEMPデータベースは一時データベースであるため、インスタンス再起動でグローバルデータは失われますので注意が必要です。
一時グローバルと IRISTEMP データベース
これは、InterSystems FAQサイトの記事です。
InterSystems製品のデータ(テーブルの行データ、オブジェクトのインスタンスデータ)は、グローバル変数に格納されています。
各グローバルのデータサイズは、管理ポータル>システム>構成>ローカルデータベース>グローバルのページから参照したいグローバルのプロパティをクリックし、表示されるグローバル属性ページ上のサイズ計算ボタンをクリックすることで個別のグローバルのサイズを取得することができます。
ネームスペース上のグローバルのデータサイズをまとめて表示するには、ターミナル上で^%GSIZEユーティリティを起動することで取得することができます。
実行方法は以下の通りです。
Cachéでのデータ同期については、オブジェクトとテーブルを同期させるさまざまな方法があります。
データベースレベルでは、シャドーイングまたはミラーリングを使用できます。
これは非常によく機能し、データの一部分だけを同期する必要がある場合には、
グローバルマッピングを使用してより小さなピースにデータを分割することができます。
または、クラス/テーブルレベルで双方向の同期が必要な場合には、オブジェクト同期機能を使用することができます。
これらすべての優れた機能には次のような制限があります。
Caché/IRISからCaché/IRISにしか機能しません。
このソリューションは、かなり以前からCaché/IRISに提供されており、非常に良く機能します。
^OBJ.DSTIMEで解決です。
これは、Deep Seeとのデータ同期を可能にするために構築されました。
Modified,New,Deleted
をシグナルすることで、オブジェクト/テーブルの変更に関する非常に単純なジャーナルを維持します。 これはDeep Seeだけでなく、あらゆる種類のデータ同期でも有用です。
グローバル ^OBJ.DSTIMEにはこのほかに2つの機能があります。
純粋なSQLで同期を行う場合、SQLを理解するあらゆるデータベースをターゲットとすることができます。
クラス %SYSTEM.DSTIME を拡張して、こちらに例を置きました。SAMPLESで試すことができます。
これはCaché 2018.1.3とIRIS 2020.2で機能するコーディングの例です。 新しいバージョンと同期されません。 また、InterSystemsのサポートによるサービスはありません!
この連載の第1回では、リレーショナルデータベースにおけるEAV(Entity-Attribute-Value)モデルを取り上げ、テーブルにエンティティ、属性、および値を保存することのメリットとデメリットについて確認しました。 このアプローチには柔軟性という点でメリットがあるにもかかわらず、特にデータの論理構造と物理ストレージの基本的な不一致などによりさまざまな問題が引き起こされるという深刻なデメリットがあります。
こういった問題を解決するために、階層情報の保存向けに最適化されたグローバル変数を、EAVアプローチが通常処理するタスクに使用できるかどうかを確認することにしました。
パート1では、オンラインストア向けのカタログをテーブルを使って作成し、その後で1つのグローバル変数のみで作成しました。 それでは、複数のグローバル変数で同じ構造を実装してみることにしましょう。
最初のグローバル変数^catalogには、ディレクトリ構造を保存します。 2つ目のグローバル変数^goodには、店の商品を保存します。 ^indexグローバルには、店のインデックスを保存します。 プロパティは階層的なカタログに関連付けられているため、プロパティ用の個別のグローバル変数は作成しません。
このアプローチでは、エンティティごとに(プロパティを除く)、個別のグローバル変数を使用しているため、論理の観点では優れています。 グローバルカタログ構造は次のようになります。
.png)
Set ^сatalog(root_id, "Properties", "capacity", "name") = "Capacity, GB"
Set ^сatalog(root_id, "Properties", "capacity", "sort") = 1
Set ^сatalog(root_id, sub1_id, "Properties", "endurance", "name") = "Endurance, TBW"
Set ^сatalog(root_id, sub1_id, "Properties", "endurance", "sort") = 2
Set ^сatalog(root_id, sub1_id, "goods", id_good1) = 1
Set ^сatalog(root_id, sub1_id, "goods", id_good2) = 1
Set ^сatalog(root_id, sub2_id, "Properties", "avg_seek_time", "name") = "Rotate speed, ms"
Set ^сatalog(root_id, sub2_id, "Properties", "avg_seek_time", "sort") = 3
Set ^сatalog(root_id, sub2_id, "goods", id_good3) = 1
Set ^сatalog(root_id, sub2_id, "goods", id_good4) = 1
商品のグローバル変数は、次のようになります。

Set ^good(id_good, property1) = value1
Set ^good(id_good, property2) = value2
Set ^good(id_good, property3) = value3
Set ^good(id_good, "catalog") = catalog_id
もちろん、商品のあるすべてのカタログセクションで、必要なプロパティで並べ替えを行えるようにインデックスが必要となります。 インデックスグローバルは、次のような構造になります。

Set ^index(id_catalog, property1, id_good) = 1
; To quickly get the full path to concrete sub-catalog
Set ^index("path", id_catalog) = "^catalog(root_id, sub1_id)"
したがって、カタログのすべてのセクションで、リストを並べ替えることができます。 インデックスグローバルはオプションです。 カタログのこのセクションの商品数が多い場合にのみ役立ちます。
では、データを操作するために、ObjectScriptを使用しましょう。 まず、特定の商品のプロパティを取得することから始めます。 特定の商品のIDがあり、そのプロパティを並べ替えの値で指定された順序で表示する必要があります。 そのためのコードは次のようになります。
get_sorted_properties(path, boolTable)
{
; remember all the properties in the temporary global
While $QLENGTH(@path) > 0 {
if ($DATA(@path("Properties"))) {
set ln=""
for {
Set ln = $order(@path("Properties", ln))
Quit: ln = ""
IF boolTable & @path("Properties", ln, "table_view") = 1 {
Set ^tmp(@path("Properties", ln, "sort"), ln) = @path("Properties", ln, "name")
}
ELSE {
Set ^tmp(@path("Properties", ln, "sort"), ln) = @path("Properties", ln, "name")
}
}
}
}
print_sorted_properties_of_good(id_good)
{
Set id_catalog = ^good(id_good, "catalog")
Set path = ^index("path", id_catalog)
Do get_sorted_properties(path, 0)
set ln =""
for {
Set ln = $order(^tmp(ln))
Quit: ln = ""
Set fn = ""
for {
Set fn = $order(^tmp(ln, fn))
Quit: fn = ""
Write ^tmp(ln, fn), " ", ^good(id_good, fn),!
}
}
}
次に、id_catalogに基づいて、カタログセクションの商品を表形式で取得します。
print_goods_table_of_catalog(id_catalog)
{
Set path = ^index("path", id_catalog)
Do get_sorted_properties(path, 1)
set id=""
for {
Set id = $order(@path("goods"), id)
Quit: id = ""
Write id," ", ^good(id, "price"), " "
set ln =""
for {
Set ln = $order(^tmp(ln))
Quit: ln = ""
Set fn = ""
for {
Set fn = $order(^tmp(ln, fn))
Quit: fn = ""
Write ^tmp(ln, fn), " ", ^good(id, fn)
}
Write !
}
}
}
では、EAVとSQLの使用をグローバル変数の使用と比較してみましょう。 コードの明確さについては、これが主観的なパラメーターであることは明らかです。 しかし、例として新しい商品の作成方法を見てみましょう。
SQLを使用したEAVアプローチから確認します。 まず、オブジェクトのプロパティリストを取得する必要があります。 これは別のタスクであり、非常に時間がかかります。 capacity、weight、およびenduranceという3つのプロパティのIDがすでに分かっているとします。
START TRANSACTION
INSERT INTO good (name, price, item_count, catalog_id) VALUES ('F320 3.2TB AIC SSD', 700, 10, 15);
SET @last_id = LAST_INSERT_ID ();
INSERT INTO NumberValues Values(@last_id, @id_capacity, 3200);
INSERT INTO NumberValues Values(@last_id, @id_weight, 0.4);
INSERT INTO NumberValues Values(@last_id, @id_endurance, 29000);
COMMIT
この例ではプロパティが3つしかないため、例にはそれほど圧倒されません。 一般的なケースでは、トランザクション内のテキストテーブルにいくつかの挿入があります。
INSERT INTO TextValues Values(@last_id, @ id_text_prop1, 'Text value of property 1');
INSERT INTO TextValues Values(@last_id, @ id_text_prop2, 'Text value of property 2');
...
INSERT INTO TextValues Values (@last_id, @id_text_propN, 'Text value of property N');
もちろん、数値の代わりに「capacity」を使うというように、IDプロパティの代わりにテキスト表記を使用すれば、SQLバージョンをもう少し簡略することも可能ですが、 SQLの世界では、これは受け入れられません。 エンティティのインスタンスを列挙するには、数値IDを使用するのが慣例です。 このため、インデックス処理が高速化し(インデックス処理のバイトが少なくなるため)、一意性を追跡しやすくなり、新しいIDを自動的に作成しやすくなります。 この場合、挿入フラグメントは次のようになります。
INSERT INTO NumberValues Values(@last_id, 'capacity', 3200);
INSERT INTO NumberValues Values(@last_id, 'weight', 0.4);
INSERT INTO NumberValues Values(@last_id, 'endurance', 29000);
次は、同じ例をグローバル変数を使用した場合のコードです。
TSTART
Set ^good(id, "name") = "F320 3.2TB AIC SSD"
Set ^("price") = 700, ^("item_count") = 10, ^("reserved_count") = 0, ^("catalog") = id_catalog
Set ^("capacity") = 3200, ^("weight") = 0.4, ^("endurance") = 29000
TCOMMIT
では、EAVアプローチで商品を削除してみましょう。
START TRANSACTION
DELETE FROM good WHERE id = @ good_id;
DELETE FROM NumberValues WHERE good_id = @ good_id;
DELETE FROM TextValues WHERE good_id = @ good_id;
COMMIT
そして、グローバル変数でも同じことを行います。
Kill ^good(id_good)
2つのアプローチをコードの長さの観点から比較することもできます。 上記の例からわかるように、グローバル変数を使用した方が、コードは短くなります。 これはメリットです。 コードが短くなるほど、エラーの数も減り、コードを理解して管理するのも容易になります。
一般に、コードが短いほど処理が高速化します。 そして、この場合には、グローバル変数はリレーショナルテーブルよりも低位データ構造であるため、確かにそのとおりです。
次に、水平方向のスケーリングを見てみましょう。 EAVアプローチでは、少なくとも3つの最も大きなテーブル(Good、NumberValues、TextValues)を複数のサーバーに分散する必要があります。 エンティティと属性のあるテーブルにはほとんど情報がないため、これらのテーブルは単純にすべてのサーバーに丸ごとコピーすることができます。
各サーバーでは、水平方向のスケーリングにより、さまざまな商品がGood、NumberValues、およびTextValuesテーブルに保存されます。 異なる商品でIDが重複しないように、各サーバーの商品に対して特定のIDブロックを割り当てる必要があります。
グローバルを使って水平方向のスケーリングを行う場合、グローバルでID範囲を構成し、グローバル範囲を各サーバーに割り当てる必要があります。
複雑さは、EAVとグローバルであまり変わりませんが、EAVアプローチの場合は、3つのテーブルにID範囲を構成しなければなりません。 グローバルの場合は、1つのグローバル変数のみにIDを構成するだけで済みます。 つまり、水平方向のスケーリングを調整するには、グローバル変数の方が簡単と言えます。
最後に、データベースファイルの破損によるデータ損失のリスクを検討してみましょう。 5つのテーブルか3つのグローバル(インデックスグローバルを含む)のどちらにすべてのデータを保存する方が簡単でしょうか。
3つのグローバルの方が簡単だと思います。 EAVアプローチでは、さまざまな商品のデータがテーブルに混在しているのに対し、グローバルでは情報がより全体的に保存されています。 基盤のブランチは、保存されて順に並べ替えられています。 そのため、データがパスタが絡み合うように保存されるEAVアプローチに比べれば、グローバルの一部の破損によってダメージにつながる可能性は低くなります。
データ回復におけるもう1つの悩みの種は、情報の表示方法です。 EAVアプローチでは、情報は複数のテーブルに分割されているため、1つにまとめるには特別なスクリプトが必要です。 グローバルの場合は、ZWRITEコマンドを使用するだけで、ノードのすべての値と基盤のブランチを表示することができます。
EAVアプローチは、階層データを保存するためのトリックとして出現しました。 テーブルは元々、ネストされたデータを保存するようには設計されてはいなかったため、 テーブルでグローバルをエミュレーションするのがEAVの事実上のアプローチです。 テーブルがグローバルよりも高位で低速のデータストレージ構造であることを考えると、EAVアプローチは、グローバルと比較した場合に失敗となります。
個人的な意見を言えば、階層データ構造の場合、グローバルの方がプログラミングの点でより利便性が高く理解しやすいと思います。また、より高速でもあります。
プロジェクトでEAVアプローチを計画している場合は、InterSystems IRISのグローバルを使用して階層データを保存することを検討するようお勧めします。

この連載の最初の記事では、リレーショナルデータベースのEAV(Entity–Attribute–Value)モデルを見て、それがどのように使用されて、何に役立つのかを確認しましょう。 その上で、EAVモデルの概念とグローバル変数と比較します。
原則として検索する必要のある、フィールド数、または階層的にネストされたフィールドの数が不明なオブジェクトがある場合があります。
たとえば、多様な商品群を扱うオンラインストアを考えてみましょう。 商品群ごとに固有の一意のプロパティセットがあり、共通のプロパティもあります。 たとえば、SSDとHDDドライブには共通の「capacity」プロパティがありますが、SSDには「Endurance, TBW」、HDDには「average head positioning time」という一意のプロパティもあります。
場合によっては、同じ商品でも別のメーカーが製造した場合には、それぞれに一意のプロパティが存在します。
では、50種の商品群を販売するオンラインストアがあるとしましょう。 各商品群には、数値またはテキストの固有のプロパティが5つあります。
実際に使用するのは5個だけであっても、各商品に250個のプロパティがあるテーブルを作成するのであれば、ディスク容量の要件が大幅に増える(50倍!)だけでなく、有用性のない空のプロパティによってキャッシュが詰まってしまうため、データベースの速度特性が大幅に減少してしまいます。
さらに、それだけではありません。 固有のプロパティを持つ新しい商品群を追加するたびに、ALTER TABLEコマンドを使用してテーブルの構造を変更する必要があります。 大規模なテーブルであれば、この操作には数時間、さらには数日間かかる可能性もあり、ビジネスでは許容しかねます。
これを注意深く読んでいる方は「商品群ごとに異なるテーブルを用意しては?」と言うでしょう。 もちろんその通りではありますが、このアプローチを使用すると、大型ストアの場合には、数万個ものテーブルでデータベースを作成することになり、管理が困難になります。 さらに、サポートする必要のあるコードがますます複雑化してしまいます。
一方、新しい商品群を追加するときに、データベースの構造を変更する必要はありません。 新しい商品群向けの新しいテーブルを追加すればよいだけだからです。
いずれにせよユーザーは、ストア内の商品を簡単に検索できること、現在のプロパティを示す便利な表形式で商品を表示できること、そして商品を比較できることが必要です。
ご想像のとおり、商品群の5個のプロパティのみが必要であるにもかかわらず、商品テーブルにはさまざまなプロパティを示す250個のフィールドがあれば不便であるのと同様に、250個のフィールドを使った検索フォームは、ユーザーにとって非常に不便です。 これは商品の比較にも当てはまります。
マーケティングデータベースも別の有用な例と言えるでしょう。 それに格納されている人ごとに、絶えず追加、変更、または削除される可能性のある多数のプロパティが必要です(多くの場合はネストされています)。 過去にある商品を特定の数量で購入した、特定の商品群を購入した、何かに参加した、どこかで勤務した、親戚がいる、この都市に住む、特定の社会階級に属する、などのプロパティがあります。 フィールド数は数千個にもなり、変化も絶えないでしょう。 マーケターは常に、さまざまな顧客グループを区別して魅力的な特別オファーを提供する方法を考えています。
これらの問題を解決すると同時に、明確で確定的なデータベース構造を得るために、Entity-Attribute-Valueアプローチが編み出されました。
EAVアプローチの本質は、エンティティ、属性、および属性値を個別に保存することにあります。 一般的に、EAVアプローチを説明するために、Entity、Attribute、およびValueという3つのテーブルのみが使用されます。

保存するデモデータの構造。

5つ(最後の2つのテーブルを1つに統合することにした場合は4つ)のテーブルを使用したより複雑な例を考察してみましょう。

最初のテーブルはСatalogです。
CREATE TABLE Catalog (
id INT,
name VARCHAR (128),
parent INT
);
このテーブルは実際、EAVアプローチのエンティティに対応しています。 階層的な商品カタログのセクションを保存します。
2つ目のテーブルは ****Fieldです。
CREATE TABLE Field (
id INT,
name VARCHAR (128),
typeOf INT,
searchable INT,
catalog_id INT,
table_view INT,
sort INT
);
このテーブルでは、属性の名前、型、および属性が検索可能であるかどうかを指定します。 また、プロパティが属する商品を保持しているカタログのセクションも指定します。 catalog_id以下のカタログセクションにあるすべての商品には、このテーブルに保存されているさまざまなプロパティがある場合があります。
3つ目のテーブルはGoodです。 商品を、商品の価格、商品の合計数量、商品の予約数量、および商品名とともに保存するように設計されています。 厳密にはこのテーブルは必要ではありませんが、個人的には、商品用に別のテーブルを用意しておくと便利だと思います。
CREATE TABLE Good (
id INT,
name VARCHAR (128),
price FLOAT,
item_count INT,
reserved_count,
catalog_id INT
);
4つ目のテーブル(TextValues)と5つ目のテーブル(NumberValues)は、商品のテキストの値と数値属性を保存するように設計されており、構造も似ています。
CREATE TABLE TextValues (
good_id INT,
field_id INT,
fValue TEXT
);
CREATE TABLE NumberValues (
good_id INT,
field_id INT,
fValue INT
);
テキスト値と数値に個別のテーブルを使用する代わりに、次の構造で単一のCustomeValuesテーブルを使用することもできます。
CREATE TABLE CustomValues (
good_id INT,
field_id INT,
text_value TEXT,
number_value INT
);
データ型ごとに個別に保存しておけば、速度が向上し、容量を節約できるため、私は別々に保存する方を好んでいます。
SQLを使用して、カタログ構造マッピングを表示してみましょう。
SELECT * FROM Catalog ORDER BY id;
これらの値からツリーを作成するには、個別のコードが必要となります。 PHPでは、次のようになります。
$stmt = $ pdo-> query ('SELECT * FROM Catalog ORDER BY id');
$aTree = [];
$idRoot = NULL;
while ($row = $ stmt->fetch())
{
$aTree [$row ['id']] = ['name' => $ row ['name']];
if (! $row['parent'])
$idRoot = $row ['id'];
else
$aTree [$row['parent']] ['sub'] [] = $row['id'];
}
将来的には、ルートノードの $aTree[$ idRoot] から始めると、ツリーを簡単に描画できるようになります。
では、特定の商品のプロパティを取得しましょう。
まず、この商品に固有のプロパティのリストを取得し、その後で、それらのプロパティとデータベースにあるプロパティを接続します。 実際には、示されるすべてのプロパティが入力されているわけではないため、LEFT JOINを使用する必要があります。
SELECT * FROM
(
SELECT g. *, F.name, f.type_of, val.fValue, f.sort FROM Good as g
INNER JOIN Field as f ON f.catalog_id = g.catalog_id
LEFT JOIN TextValues as val ON tv.good = g.id AND f.id = val.field_id
WHERE g.id = $ nGood AND f.type_of = 'text'
UNION
SELECT g. *, F.name, f.type_of, val.fValue, f.sort FROM Good as g
INNER JOIN Field as f ON f.catalog_id = g.catalog_id
LEFT JOIN NumberValues as val ON val.good = g.id AND f.id = val.field_id
WHERE g.id = $nGood AND f.type_of = 'number'
) t
ORDER BY t.sort;
数値とテキスト値の両方を保存するために1つのテーブルのみを使用すると、クエリを大幅に簡略化できます。
SELECT g. *, F.name, f.type_of, val.text_value, val.number_value, f.sort FROM Good as g
INNER JOIN Field as f ON f.catalog = g.catalog
LEFT JOIN CustomValues as val ON tv.good = g.id AND f.id = val.field_id
WHERE g.id = $nGood
ORDER BY f.sort;
では、$nCatalogカタログセクションに含まれる商品を表形式で取得します。 まず、カタログのこのセクションのテーブルビューに反映する必要があるプロパティのリストを取得します。
SELECT f.id, f.name, f.type_of FROM Catalog as c
INNER JOIN Field as f ON f.catalog_id = c.id
WHERE c.id = $nCatalog AND f.table_view = 1
ORDER BY f.sort;
次に、テーブルを作成するクエリを構築します。 表形式ビューには、3つの追加プロパティ(Goodテーブルのプロパティのほかに)が必要だとします。 クエリを単純化するために、次を前提としています。
SELECT g.if, g.name, g.price,
f1.fValue as f1_val,
f2.fValue as f2_val,
f3.fValue as f3_val,
FROM Good
LEFT JOIN TextValue as f1 ON f1.good_id = g.id
LEFT JOIN NumberValue as f2 ON f2.good_id = g.id
LEFT JOIN NumberValue as f3 ON f3.good_id = g.id
WHERE g.catalog_id = $nCatalog;
EAVアプローチは明らかに柔軟性のメリットがあります。 テーブルなどの固定されたデータ構造を使用すると、オブジェクトの広範なプロパティセットを保存することが可能になります。 また、データベースのスキーマを変更せずに、別のデータ構造を保存することができます。
また、非常に多くの開発者に馴染みのあるSQLも使用することができます。
最も明白なデメリットは、データの論理構造と物理ストレージの不一致であり、これによって様々な問題が引き起こされます。
さらに、プログラミングには、非常に複雑なSQLクエリが伴うこともよくあります。 EAVデータの表示には標準的に使用されていないツールの作成が必要となるため、デバッグが困難になることがあります。 また、LEFT JOINクエリを使用する必要がある場合があるため、データベースの速度が低下してしまいます。
私はSQLの世界とグローバル変数の世界の両方に精通しているため、EAVアプローチが解決するタスクにグローバルを使用する方がはるかに魅力的になるのではないかと考えました。
グローバル変数はまばらで階層的な情報を保存できるデータ構造です。 グローバル変数は階層情報を保存するために慎重に最適化されているというのが非常に重要なポイントです。 グローバル変数自体はテーブルよりも低レベルの構造であるため、テーブルよりもはるかに素早く動作します。
同時に、グローバル構造自体をデータ構造に従って選択できるため、コードを非常に単純で明確にすることができます。
グローバル変数はデータを保存する上で非常に柔軟でエレガントな構造であるため、1つのグローバル変数を管理するだけでカタログセクション、プロパティ、および商品などのデータを保存することができます。

グローバル構造がデータ構造にどれほど似ているのかに注目してください。 このコンプライアンスによって、コーディングとデバッグが大幅に簡略化されます。
実際には、全ての情報を1つのグローバルに保存したい気持ちが非常に強くても、複数のグローバルを使用することをお勧めします。 インデックス用に別のグローバルを作成することが合理的です。 また、ディレクトリのパーティション構造のストレージを商品から分離することもできます。
この連載の2つ目の記事では、EAVモデルに従う代わりに、InterSystems Irisのグローバルにデータを保存する方法の詳細とメリットについて説明します。
これは InterSystems FAQ サイトの記事です。
ディスクの空きスペースにもよりますが、ブロック別で最大サイズが異なります。
各バージョン共通で、8KBのブロックサイズを使用した場合は、32TBです。
バージョン2008.1以降のバージョンでは、8KB以外のブロックサイズを指定できるようになったため、最大サイズは以下の通りです。
このツールは、データベース内からランダム読み出し入力/出力(IO)を生成するために使用されます。 このツールの目的は、目標IOPSを達成し、許容範囲内のディスク応答時間の維持を確保するために、可能な限り多くのジョブを駆動することです。 IOテストから収集された結果は、IOサブシステムに基づいて構成ごとに異なります。 これらのテストを実行する前に、対応するオペレーティングシステムとストレージレベルの監視が、今後の分析のためにIOパフォーマンスの測定データーを保存するように設定されていることを確認してください。
少数のプロセスでプロセスごとに10,000回の反復から始めます。 オールフラッシュストレージアレイでは、プロセスごとに100,000回の反復を使用します。 次に、10ジョブから開始して、10、20、40など追加し、プロセスの数を増やしていきます。 応答時間が一貫して10ミリ秒を超えるか、計算されたIOPSが直線的に増加しなくなるまで、個々のテストを実行し続けます。
目安として、8KBおよび64KBのデータベースランダム読み出し(キャッシュされていない)の次の応答時間は、通常、オールフラッシュアレイで許容されます。
このツールでは、事前に拡張された空のIRIS.DATデータベースが、サーバーのメモリサイズの少なくとも2倍であり、ストレージコントローラーのキャッシュサイズの少なくとも4倍である必要があります。 読み出しがファイルシステムキャッシュにキャッシュされてしまわないように、データベースをメモリ容量よりも大きくする必要があります。
このツールは、データベースブロックをメモリに読み込ませるObjectScript VIEWコマンドを使用するため、期待した結果が得られない場合は、恐らくすべてのデータベースブロックがすでにメモリ内にあるということになります。
次の表に、環境の仕様と目標を記入してください。
| 仕様 | 例 |
|---|---|
| ストレージ | ストレージアレイの仕様 |
| 物理サーバー | CPU、メモリ仕様 |
| 仮想マシン | Red Hat Enterprise Linux 7 24 vCPU, 40GB vRAM |
| データベースサイズ | 200GB |
| 共有メモリ | Huge Pagesを使用して割り当てられた26956MBの共有メモリ:24000MBのグローバルバッファ、1000MBのルーチンバッファ |
| 目標IOPS | 2000 |
| 目標応答時間 | 5ミリ秒以下 |
こちらからGitHubでPerfTools.RanRead.xmlツールをダウンロードします。
PerfTools.RanRead.xmlをUSERネームスペースにインポートします。
USER> do $system.OBJ.Load("/tmp/PerfTools.RanRead.xml","ckf")Helpメソッドを実行して、すべてのエントリポイントを確認します。 すべてのコマンドが%SYSで実行されます。
USER> do ##class(PerfTools.RanRead).Help()
InterSystems Random Read IO Performance Tool
--------------------------------------------
do ##class(PerfTools.RanRead).Setup(Directory,DatabaseName,SizeGB,LogLevel)
- 同じ名前でデーターベースとネームスペースを作成します。 ログレベルは0〜3の範囲である必要があります。0は「なし」、3は「詳細」となります。
do ##class(PerfTools.RanRead).Run(Directory,Processes,Iterations)
- ランダム読み出しIOテストを実行します。
do ##class(PerfTools.RanRead).Stop()
- 全てのバックグラウンドジョブを終了します。
do ##class(PerfTools.RanRead).Reset()
- ^PerfTools.RanRead* に保管されているランダム読み出し履歴を削除します
do ##class(PerfTools.RanRead).Export(directory)
- 全てのランダム読み出しテストの履歴の概要をタブ区切りテキストファイルにエクスポートします。
テストする物理ホストのメモリの約2倍のサイズのZRANREADという空の(事前に拡張された)データベースを作成します。 空のデータベースがストレージコントローラーのキャッシュサイズの少なくとも4倍であることを確認します。 手動で作成するか、次の方法を使用してネームスペースとデータベースを自動的に作成できます。
USER> do ##class(PerfTools.RanRead).Setup("/usr/iris/db/zranread","ZRANREAD",100,1)
Creating 100GB database in /usr/iris/db/zranread/
Database created in /usr/iris/db/zranread/
Run %Installer Manifest...
2016-05-23 13:33:59 0 PerfTools.RanRead: Installation starting at 2016-05-23 13:33:59, LogLevel=1
2016-05-23 13:33:59 1 CreateDatabase: Creating database ZRANREAD in /usr/iris/db/zranread// with resource
2016-05-23 13:33:59 1 CreateNamespace: Creating namespace ZRANREAD using ZRANREAD/ZRANREAD
2016-05-23 13:33:59 1 ActivateConfiguration: Activating Configuration
2016-05-23 13:34:00 1 EnableEnsemble: Enabling ZRANREAD
2016-05-23 13:34:00 1 ActivateConfiguration: Activating Configuration
2016-05-23 13:34:00 0 PerfTools.RanRead: Installation succeeded at 2016-05-23 13:34:00
2016-05-23 13:34:00 0 %Installer: Elapsed time 1.066633s
Database /usr/iris/db/zranread/ ready for testing.
do ##class(PerfTools.RanRead).Run(directory,processes,iterations) e.g.
do ##class(PerfTools.RanRead).Run("/usr/iris/db/zranread/",1,10000)
プロセスの数を増やしながらRunメソッドを実行して、応答時間をメモします。
テストが速すぎる場合や結果が期待どおりでない場合は、反復回数を10000に増やします。
USER> do ##class(PerfTools.RanRead).Run("/usr/iris/db/zranread",20,10000)
InterSystems Random Read IO Performance Tool
--------------------------------------------
Starting 20 jobs in the background.
To terminate jobs run: do ##class(PerfTools.RanRead).Stop()
Waiting for jobs to finish.........................
Random read background jobs finished.
20 processes (1000 iterations) average response time = 7.18ms
Calculated IOPS = 2787
各実行の結果は、USERのPerfTools.RanReadというSQLテーブルに保存されます。 次のSQLクエリを実行すると、結果の概要を確認できます。
SELECT RunDate,RunTime,Database,Iterations,Processes,
{fn ROUND(AVG(ResponseTime),2)} As ResponseTime,
{fn ROUND(AVG(IOPS),0)} As IOPS
FROM PerfTools.RanRead
GROUP BY Batch
結果セットをタブ区切りのテキストファイルにエクスポートするには、次の手順を実行します。
USER> do ##class(PerfTools.RanRead).Export("/usr/iris/db/zranread/")
Exporting summary of all random read statistics to /usr/iris/db/zranread/PerfToolsRanRead_20160523-1408.txt
Done.
エクスポートしたテキストファイルをExcelで開いてコピーし、PerfToolsRandomRead \ _Analysis \ _Template.xlsxスプレッドシートに貼り付け、グラフ化します。

サンプルスプレッドシートはこちらからGitHubでダウンロードすることができます。
テストの実行が終了したら、次のコマンドを実行して履歴を削除します。
%SYS> do ##class(PerfTools.RanRead).Reset()
MonCaché — InterSystems Caché での MongoDB API 実装
プロジェクトの構想は、クライアント側のコードを変更せずに MongoDB の代わりに InterSystems Caché を使用できるように、ドキュメントを検索、保存、更新、および削除するための基本的な MongoDB(v2.4.9) API 機能を実装するところにあります。
おそらく、MongoDB に基づくインターフェースを使って、データストレージに InterSystems Caché を使用すると、パフォーマンスが向上するのではないか。 このプロジェクトは、学士号を取得するための研究プロジェクトとして始まりました。
ダメなわけないよね?! ¯\(ツ)/¯
この研究プロジェクトを進める過程で、いくつかの簡略化が行われました。
タスクは最終的に次のサブタスクに分割されました。
最初のサブタスクは問題ではなかったので、中間の説明を省略して、インターフェースの実装部分を説明します。
MongoDB は、データベースをコレクションの物理的なコンテナとして定義します。 コレクションはドキュメントのセットで、ドキュメントはデータのセットです。 ドキュメントは JSON ドキュメントのようですが、大量の許容型を持っています。つまり BSON です。
InterSystems Caché では、すべてのデータはグローバルに保存されます。 簡単に言えば、階層データ構造として考えることができます。
このプロジェクトでは、すべてのデータは単一のグローバル(^MonCache )に保存されます。
そのため、階層データ構造を使用して、データベース、コレクション、およびドキュメントの表現スキームを設計する必要があります。
実装したグローバルレイアウトは、数多くの潜在的なレイアウトの 1 つに過ぎず、これらのレイアウトには、それぞれにメリットと制限があります。
MongoDB では、1 つのインスタンスに複数のデータベースが存在する可能性があるため、複数の分離されたデータベースを格納できるようにする表現スキームを設計する必要があります。 MongoDB はコレクションをまったく含まないデータベースをサポートしていることに注意しておきましょう(これらを「空」のデータベースと呼ぶことにします)。
私はこの問題に対し、一番単純で一番明白なソリューションを選択しました。 データベースは、^MonCache グローバルの第 1 レベルノードとして表されます。 さらに、そのようなノードは、「空」のデータベースのサポートを有効にするために ”” 値を取得します。 問題は、これを行わずに子ノードを追加するだけの場合、それらを削除すると親ノードも削除されるということです(これがグローバルの動作です)。
したがって、各データベースは Caché 内で次のように表されます。
^MonCache(<db>) = ""たとえば、「my_database」データベースの表現は次のようになります。
^MonCache("my_database") = ""MongoDB は、コレクションをデータベースの要素として定義します。 単一のデータベース内にあるすべてのコレクションには、正確なコレクションの識別に使用できる一意の名前があります。 このことが、グローバルでコレクションを表現する単純な方法を見つけ、第 2 レベルのノードを使用する上で役立ちました。 次に、2 つの小さな問題を解決する必要があります。 1 つ目の問題は、コレクションがデータベースと同じように空であることができるということです。 2 つ目は、コレクションが一連のドキュメントであるということです。 そして、これらのドキュメントはすべて、互いに分離している必要があります。 正直なところ、コレクションノードの値として自動的に増分する値のようなカウンターを使う以外に良いアイデアが浮かびませんでした。 すべてのドキュメントには一意の番号があります。 新しいドキュメントが挿入されると、現在のカウンターの値と同じ名前が付いた新しいノードが作成され、カウンターの値が 1 つ増加するというアイデアです。
したがって、各 Caché コレクションは、次のように表されます。
^MonCache(<db>) = ""
^MonCache(<db>, <collection>) = 0たとえば、「 my_database」データベース内の「my_collection」コレクションは次のように表されます。
^MonCache("my_database") = ""
^MonCache("my_database", "my_collection") = 0このプロジェクトでは、ドキュメントは追加の ObjectID という型で拡張された JSON ドキュメントです。 ドキュメントの表現スキームは、階層データ構造で設計する必要がありました。 いくつかの驚きに遭遇したのはここです。 まず、Caché では「ネイティブ」の null がサポートされていなかったために、使用できなかったことです。 もう 1 つは、ブール値が 0 と 1 の定数で実装されているということです。 つまり、1 が true で 0 が false ということなのです。 一番予想していた問題は、ObjectId を格納する方法を考え出す必要があるということでした。 結局、これらの問題はすべて最も簡単な方法でうまく解決されたのです。というか、解決されたと思いました。 以下では、各データ型とその表現について説明します。
Node.js ドライバーの選択は、InterSystems Caché と連携する上で論理的かつ単純な決定であるように思われました(ドキュメントサイトには、Caché と対話するためのドライバーがほかにも掲載されています)。 ただし、ドライバーの機能では不十分です。 私が行いたかったのは、1 回のトランザクションで複数の挿入を実行することだったので、 Caché 側で MongoDB API をエミュレートするために使用される一連の Caché ObjectScript クラスを開発することにしました。
Caché Node.js ドライバーは、Caché クラスにアクセスできませんでしたが、Caché からプロフラム呼び出しを行うことができました。 このことから、小さなツールが作成されました。ドライバーと Caché クラスを繋ぐ、一種のブリッジです。
結局、スキームは次のようになりました。
プロジェクトの作業を進めながら、NSNJSON(Not So Normal JSON: あんまり普通じゃない JSON)と名付けた、ドライバーを介して ObjectId、null、true、および false を Caché に「密輸」する特別な形式を作成しました。 この形式の詳細については、GitHub の対応するページ(NSNJSON)をご覧ください。
ドキュメント検索には、次の基準を使用できます。
ドキュメントの更新操作には、次の演算子を使用できます。
以下のコードは、私がドライバーの公式ページから取得して少し修正したコードです。
var insertDocuments = function(db, callback) {
var collection = db.collection('documents');
collection.insertOne({ site: 'Habrahabr.ru', topic: 276391 }, function(err, result) {
assert.equal(err, null);
console.log("Inserted 1 document into the document collection");
callback(result);
});
}var MongoClient = require('mongodb').MongoClient
, assert = require('assert');var url = 'mongodb://localhost:27017/myproject';MongoClient.connect(url, function(err, db) {
assert.equal(null, err);
console.log("Successfully connected to the server"); insertDocument(db, function() {
db.close();
});
});このコードは、MonCaché と互換性を持つように簡単に変更することができます。
ドライバーを変更するだけです!
// var MongoClient = require('mongodb').MongoClient
var MongoClient = require('moncache-driver').MongoClientこのコードが実行されると、^MonCache グローバルは次のようになります。
^MonCache("myproject","documents")=1
^MonCache("myproject","documents",1,"_id","t")="objectid"
^MonCache("myproject","documents",1,"_id","v")="b18cd934860c8b26be50ba34"
^MonCache("myproject","documents",1,"site","t")="string"
^MonCache("myproject","documents",1,"site","v")="Habrahabr.ru"
^MonCache("myproject","documents",1,"topic","t")="number"
^MonCache("myproject","documents",1,"topic","v")=267391ほかのすべてとは別に、小型のデモアプリケーション(ソースコード)を公開しました。また、サーバーの再起動とソースコードの変更を行わないで、MongoDB Node.js から MonCaché Node.js へのドライバーの変更を実演するために、Node.js を使って実装しました。 アプリケーションは、CRUD 演算を製品やオフィスで実行するための小さなツールであり、構成を変更(ドライバーを変更)するためのインア―フェースでもあります。
サーバーでは、構成で選択されたストレージ(Caché または MongoDB)に保存される製品とオフィスを作成できます。
[Orders]タブには、注文のリストが含まれています。 レコードは作成されていますが、フォームは未完成です。 プロジェクトの援護を歓迎しています(ソースコード)。
構成は、Configuration ページで変更できます。 このページには、MongoDB と MonCache の 2 つのボタンがあります。 対応するボタンをクリックすると、希望する構成を選択できます。 構成が変更されると、クライアントアプリケーションはデータソースに再接続します(実際に使用されているドライバーからアプリケーションを分離する概念)。
結論を出すために、根本的な質問に答えさせてください。 そうです! 基本的な操作におけるパフォーマンスを向上させることができました。
MonCaché プロジェクトは GitHub に公開されており、MIT ラインセンスの下に提供されています。
InterSystems テクノロジーに基づく独自の研究プロジェクトを始めたい方は、InterSystems 教育プログラム専用の特設サイトをご覧ください。
以下の記事では、DeepSee の中程度の複雑さのアーキテクチャ設計を説明します。 前の例で説明したとおり、この実装には、DeepSee キャッシュや DeepSee の実装と設定用の個別のデータベースが含まれています。 この記事では、同期に必要なグローバルの保存用と、ファクトテーブルとインデックスの保存用に、2 つの新しいデータベースを紹介します。

前の例で紹介した APP-CACHE と APP-DEEPSEE データベースのほかに、APP-DSTIME と APP-FACT データベースを定義します。
APP-DSTIME データベースには DeppSee の同期グローバルである ^OBJ.DSTIME と ^DeepSee.Update が含まれます。 これらのグローバルは、運用サーバーにある(ジャーナリングされた)データベースからミラーリングされています。 APP-DSTIME データベースは、^DeepSee.Update を使用して caché バージョンの読み取りと書き込みができる必要があります。
APP-FACT データベースは、ファクトテーブルとインデックスを保存します。 ファクトテーブルからインデックスを分離するのは、インデックスのサイズが大きくなる可能性があるためです。 APP-FACT を定義することで、ジャーナル設定の柔軟性をより高めたり、デフォルト以外のブロックサイズを定義したりすることができます。 APP-FACT データベースのジャーナリングはオプションで有効にできますが、 この選択は主に、中断が発生した場合にキューブを再構築する際に、アナリティクスが利用できないままとなるかどう通って決まります。 この例では、ファクトテーブルとインデックスのジャーナリングは無効になっています。無効にする一般的な理由には、キューブサイズが小さいこと、キューブの再構築を比較的素早く行えること、そして定期的な再構築が頻繁に行われることがあります。 より詳しい説明は、下の方にある注意事項をお読みください。
次のスクリーンショットは、上記の実装例のマッピングを示しています。
DeepSee 同期グローバルの ^OBJ.DSTIME と ^DeepSee.Update は、APP-DSTIME データベースにマッピングされています。 ^DeepSee.LastQuery と ^DeepSee.QueryLog グローバルは、実行されるすべての MDX クエリのログを定義します。 この例では、これらのグローバルは DeepSee キャッシュとともに APP-CACHE データベースにマッピングされています。 これらのマッピングはオプションです。
^DeepSee.Fact* と ^DeepSee.Dimension* グローバルは、ファクトテーブルと次元テーブルを保存しますが、^DeepSee.Index グローバルは DeppSee インデックスを定義します。 これらのグローバルは、APP-FACT データベースにマッピングされています。
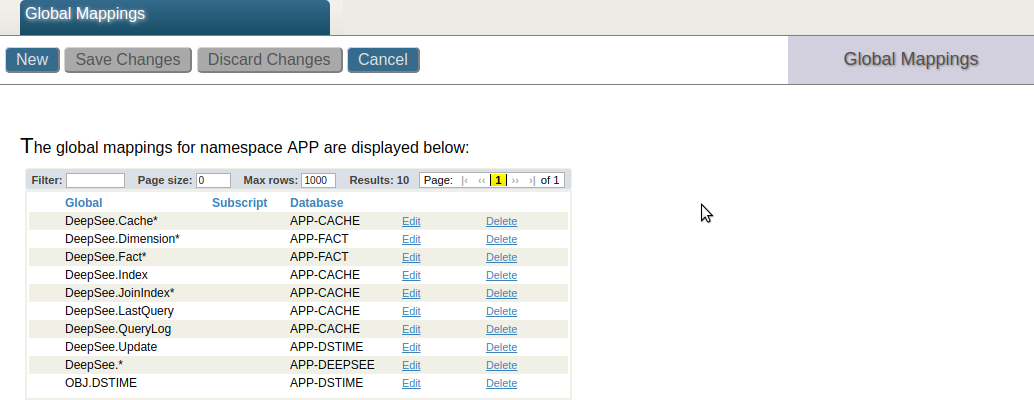
基本的な例のように、DeepSee キャッシュは、ジャーナリングが無効になっている専用のデータベースに正しく保存されています。 DeepSee の実装と設定は、DeepSee 実装を復元できるように、ジャーナリングされたデータベースに個別にマッピングされています。
同期をサポートするグローバルは APP-DSTIME にマッピングされ、プライマリでジャーナリングされています。
ファクトテーブルとインデックスを専用のデータベースにマッピングすると、DeepSee の実装と設定をジャーナリングされる専用のデータベース( APP-DEEPSEE)に保存できるため、DeepSee 実装の復元を簡単に行えるようになります。
最後の 3 つ目の例では、APP-FACT データベースのマッピングを再定義し、DeepSee インデックスのデータベースを作成します。
キューブを構築するとキューブのファクトとインデックステーブルが削除されて再作成されることに注意してください。 つまり、ジャーナリングが有効である場合、^DeepSee.Fact* や ^DeepSee.Index などのグローバルの SET や KILL がジャーナルファイルに記録されるということです。 その結果、キューブを再構築すると、ジャーナルファイルのエントリが膨大化し、ディスク容量に問題が生じる可能性があります。
ファクトテーブルとインデックスを 1 つか 2 つの別々のデータベースにマッピングすることをお勧めします。
ファクトおよびインデックスデータベースにおいては、ジャーナリングはオプションであり、ビジネスのニーズに基づきます。 キューブが比較的小さく、素早く構築できる場合や、キューブの定期的な再構築が計画されている場合には、ジャーナリングを無効にすることをお勧めします。
キューブが比較的大きく、再構築に時間が掛かる場合には、このデータベースのジャーナリングを有効にします。 キューブが安定しており、定期的に同期されるだけで構築は行われない場合には、ジャーナリングを有効にしておくのが理想的と言えます。 キューブを安全に構築する方法の 1 つとして、ファクトデータベースのジャーナリングを一時的に無効にすることが挙げられます。
以下の記事は、DeepSee の基本的なアーキテクチャを実装するためのガイドです。 この実装には、DeepSee キャッシュ用のデータベースと DeepSee 実装と設定用のデータベースが含まれています。

アナリティクスサーバー用のこの構成には、APP-CACHE と APP-DEEPSEE データベースが含まれています。 DeepSee が円滑に実行するためには、DeepSee キャッシュを決してジャーナリングしないことが重要な設定となります。 ジャーナリングしてしまうと、ハイパージャーナリングやディスク容量の問題が発生するだけでなく、DeepSee エンジンのパフォーマンスが低下してしまいます。 このため、DeepSee キャッシュは、ジャーナリングが無効になっている別の DeepSee Cache データベース「APP-CACHE」に格納されます。
APP-DEEPSEE は、^DeepSee.* グローバルが含まれる、DeepSee の実装と設定用のデータベースです。 これらのグローバルは、定義と設定、Cube Manager、ユーザー設定など、ほとんどの DeepSee 実装を定義しています。 次に示すスクリーンショットに見られるように、すべてのデータベースは読み取り/書き込みが可能であり、APP-DEEPSEE でのみジャーナリングが有効となるように決定されていることに注意してください。 このデータベースにはすべての定義、設定、およびユーザーデータが含まれているため、これをジャーナリングすることをお勧めします。
次のスクリーンショットは、APP ネームスペース上のこの基本アーキテクチャ実装のマッピングを示しています。 ^DeepSee.Cache.* と ^DeepSee.JoinIndex は DeepSee キャッシュを APP-CACHE データベースにマッピングしています。 ^DeepSee.* グローバルはとりわけ、DeepSee の実装と設定を APP-DEEPSEE データベースにマッピングしています。

基本アーキテクチャのこの例では、DeepSee キャッシュは専用のデータベースに保存されています。 このため、^DeepSee.Cache* と ^DeepSee.JoinIndex グローバルのジャーナリングを無効にすることができます。
中断が発生した場合に DeepSee 実装(キューブ、サブジェクトエリア、DeepSee アイテム、ユーザー設定など)の復元を実現できるのが、APP-DEEPSEE データベースのジャーナリングです。
この例に説明されている構成には、いくつかの欠点があります。 まず、同期をサポートするグローバルが処理されていない点です。 2 つ目は、APP-DEEPSEE データベースには、ファクトテーブル、インデックス、およびその他の DeepSee グローバルも含まれている点です。 そのため、APP-DEEPSEE のサイズが肥大し、ジャーナリングと復元が実用的でなくなる可能性があります。 この構成は、たとえばキューブに大量のデータが含まれていない場合などに適用できます。
この連載の次の例では、キューブ同期グローバル、ファクトテーブル、およびインデックスを個別のデータベースにマッピングする方法を説明します。
以下の記事は、この連載の締めくくりとして、完全に柔軟なアーキテクチャの例で確認されたすべてのデータベースのリストを掲載しています。

以下で説明するデータベースは、ネームスペース間で共有する必要のあるアプリケーションコードを除き(例では APP-CODE データベースに格納されています)、ネームスペースごとに定義されている必要があります。 DeepSee 実装が実行するすべてのネームスペースはグローバルマッピングを使用し、グローバルが正しいデータベースに保存されて読み取られるようにする必要があります。
このデータベースはすべての DeepSee キャッシュ(^DeepSee.Cache.* および ^DeepSee.JoinIndex グローバル)を保存する必要があります(注意: ドキュメントのこちらのページに、さらに多くのグローバルが DeepSee キャッシュとしてリストされていますが、^DeepSee.Cache.* グローバルが明らかに最も重要なグローバルです)。
DeepSee キャッシュグローバルを専用のデータベースにマッピングすることを強くお勧めします。 DeepSee キャッシュグローバルは決してジャーナル化されてはいけません。ジャーナル化してしまうと、DeepSee のパフォーマンスが低下し、ジャーナルファイルが巨大化する可能性があります。
^DeepSee.Cache.* と ^DeepSee.JoinIndex グローバルをこのデータベースにマッピングします。 必要に応じて、^DeepSee.LastQuery と ^DeepSee.QueryLog グローバルもこのデータベースにマッピングします。これらは実行されたすべての MDX クエリのログを保存するグローバルです。
このデータベースには、DeepSee 実装のほとんどが含まれている ^DeepSee.* グローバルが含まれています。 このデータベースには、すべての DeepSee キューブまたはサブジェクトエリアの定義のほか、Cube Manager(^DeepSee.CubeManager*)、キューブの定義と設定(^DeepSee.Cubes、^DeepSee.Dimensions)、DeepSee のアイテム(^DeepSee.Folder*、^DeepSee.FolderItem*)、ピボット変数(^DeepSee.Variables)、用語リスト(DeepSee.TermList)、ユーザー設定(^DeepSee.DashboardSettings)、DeepSee オーバーライド(^DeepSee.Overrides)などの多数の機能に関する情報も含まれています。
これらの機能は別の読み取り/書き込み可能なデータベースに保存し、そのデータベースにジャーナリングを実行して定期的にバックアップすることをお勧めします。 そうすれば、何らかの中断が生じた場合でも、すべての定義、設定、およびユーザーデータを復元することが可能になります。
残りのすべての ^DeepSee* グローバルをこのデータベースにマッピングします。
DeepSee は、ソーステーブルでキューブを最新の状態に維持するために、^OBJ.DSTIME と ^DeepSee.Update グローバルを使用しています。 運用データベースでは、このデータベースに ^OBJ.DSTIME グローバルを保存し、アナリティクスサーバーにミラーリングします。 システムがアドホックまたは最新バージョンの Caché で実行している場合、これらには ^DeepSee.Update が使用されているため(通常、Caché 2016.1.2 以降で利用可能)、このデータベースにも ^DeepSee.Update が保存されます。 この場合、^OBJ.DSTIME を保存しているアナリティクスサーバーのデータベースは、読み取り/書き込み可能であり、^OBJ.DSTIME が ^DeepSee.Update にコピーされた後に、それをパージできる必要があります。 データベースホスティングデータ(この例では APP-DATA)が読み取り専用の場合、このデータベースを使用する必要があることに注意してください。使用しない場合、^OBJ.DSTIME をパージするのは不可能です。
運用サーバーでは、ジャーナリングが有効になっている必要があります。 ^OBJ.DSTIME と ^DeepSee.Update をこのデータベースにマッピングします。
DeepSee のキューブはソースクラスに基づいていますが、ファクトテーブルと次元テーブルにデータを入力して使用します。 これらのテーブルには、キューブに組み込まれた各レコードの情報が含まれており、ランタイム時に DeepSee によって使用されます。
ファクトテーブル、次元テーブル、およびインデックス用の専用データベースを定義するのは通常、データベースごとに異なるジャーナリングの設定を適用するためです。 ジャーナリングが有効である場合のキューブの構築について、以下の注意事項をお読みください。 ファクトテーブル、次元テーブル、およびインデックスを別のデータベースにマッピングするもう 1 つの理由は、デフォルト以外のブロックサイズを定義することができるからです(デフォルトの 8000 ブロックではなく 16000 ブロックにするなど)。 異なるブロックサイズを使用することで、MDX クエリのパフォーマンスを向上させることができます。
ファクトテーブルと次元テーブルは、^DeepSee.Fact* と ^DeepSee.Dimension* グローバルに保存されています。 DeepSee インデックスは ^DeepSee.Index に保存され、キューブがリレーションを定義するときに ^DeepSee.JoinIndex グローバルが使用されます。 これらのグローバルはこのデータベースにマッピングします。
DeepSee インデックスは、キューブのファクトテーブルのインデックスです。
DeepSee インデックスを別のデータベースに保存するのは、^DeepSee.Index グローバルのサイズが大きくなる可能性があるためです。 異なるジャーナリング設定を使用し、デフォルト以外のブロックサイズを定義すると、復元を簡単に行えるようになり、パフォーマンスの改善にも役立ちます。
ジャーナリングはオプションです。前のデータベースと同じ設定を選択してください。
^DeepSee.Index グローバルはこのデータベースにマッピングします。
キューブを構築するとキューブのファクトとインデックステーブルが削除されて再作成されることに注意してください。 つまり、ジャーナリングが有効である場合、^DeepSee.Fact* や ^DeepSee.Index などのグローバルの SET や KILL がジャーナルファイルに記録されるということです。 その結果、キューブを再構築すると、ジャーナルファイルのエントリが膨大化し、ディスク容量に問題が生じる可能性があります。
ファクトテーブルとインデックスを 1 つか 2 つの別々のデータベース(上記のデータベース 4 とデータベース 5)にマッピングすることをお勧めします。
ファクトおよびインデックスデータベースにおいては、ジャーナリングはオプションであり、ビジネスのニーズに基づきます。 キューブが比較的小さく、素早く構築できる場合や、キューブの定期的な再構築が計画されている場合には、ジャーナリングを無効にすることをお勧めします。
キューブが比較的大きく、再構築に時間が掛かる場合には このデータベースのジャーナリングを有効にします。 キューブが安定しており、定期的に同期されるだけで構築は行われない場合には、ジャーナリングを有効にしておくのが理想的と言えます。 キューブを安全に構築する方法の 1 つとして、ファクトデータベースとインデックスデータベース(順にデータベース 4 と 5)のジャーナリングを一時的に無効にすることが挙げられます。
| データベース |
この連載では、Caché と DeepSee を使用したビジネスインテリジェンスの実装に関して考慮する必要のあるデータベースとマッピング関連のベストプラクティスを説明しました。 この連載で推奨したデータベースより少ない数のデータベースを使って DeepSee 実装をデプロイすることはもちろん可能ですが、実装に制限がかかる可能性があります。
これは InterSystems FAQ サイトの記事です。
このエラーが発生する原因としては、アプリケーションの中で既に他のプロセスからロック対象リソースがロックされていて、何らかの理由でそのロックが解放されていないケースが考えられます。
他のプロセスがロックしている兆候がない場合は、ロックテーブルの空き領域が不足しているケースが想定されます。
その場合は、メッセージログ(コンソールログ)に LOCK TABLE FULL のメッセージが出力されます。
トランザクション処理を行なっている場合には、ロック解放の延期が影響しているケースも考えられます。
トランザクションとロック解放の延期については、以下のドキュメントをご参照下さい。
また、トランザクション中に、同一テーブルに対する大量レコードのSQL 文による更新がある場合、ロックしきい値(既定値は1000)に到達してロックエスカレーションが発生し、その結果として、テーブルロック状態になっている可能性もあります。
このように、ロックタイムアウトエラーの原因は幾つか考えられますので、まずは、管理ポータル(バージョン2010.2以前では、[システム管理ポータル])の、ロックメニューにて、現在のロックの状態をご確認下さい。
InterSystems IRIS では、情報を格納する「グローバル」というユニークなデータ構造をサポートしています。 基本的に、グローバルとは、マルチレベルのインデックスを持つ永続配列であり、トランザクションの実行やツリー構造のスピーディなトラバーサルといった機能が備えられているほか、ObjectScript として知られるプログラミング言語にも対応しています。
ここから先、少なくともコードサンプルについては、グローバルの基礎を理解されているという想定のもとに話しを進めていきます。
グローバルはデータを保存するための魔法の剣です パート1
グローバルはデータを保存するための魔法の剣ですパート2 - ツリー
グローバルはデータを保存するための魔法の剣です パート3 - 疎な配列
グローバルは、普通のテーブルとは全く異なる構造でデータを格納し、OSI モデルの下位層で動作します。 それでは、グローバルを使ったトランザクションとはいかなるもので、どのような特性が見られるのでしょうか。
リレーショナルデータベースの理論では、ACID テスト (Wikipedia で ACID を参照する) に合格するトランザクションこそが、適切に実装されたトランザクションとされています。
グローバルは、非リレーショナルなデータ構造です。 メモリーフットプリントを最小限に抑えながらハードウェアの超高速作業をサポートできるようにデザインされています。 それでは、IRIS/docker-image を使って、トランザクションがグローバルに実装される仕組みを見てみましょう。
3 の値を一緒にデータベースに保存する必要があるが、そうならない場合はそのいずれも保存されないという状況について考えます。
不可分性を一番手っ取り早く確認するには、ターミナルで次のコードを入力します。
Kill ^a
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TCOMMIT
最後に次を入力します。
ZWRITE ^a
結果は以下のようになるはずです。
^a(1)=1
^a(2)=2
^a(3)=3
予想とおり、不可分性を確認できました。 では、わざとエラーを導入してタスクを少し複雑にします。トランザクションが部分的に保存されるのか、全く保存されないのかを見てみましょう。 まずは、先ほどと同じように不可分性を確認します。
Kill ^a
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
今回は、ここで docker kill my-iris というコマンドを使い、コンテナを強制的に終了します。これにより SIGKILL (即座にプロセスを停止する) シグナルが送られるため、電源を強制的にオフにしているようなものです。 コンテナを再起動してから、グローバルの中身をチェックして、結果を確認します。 トランザクションは部分的に保存されているでしょうか?
ZWRITE ^a
何も表示されませんでした
いいえ、何も保存されませんでした。 これにより、アクシデントでサーバーが停止する場合、IRIS データベースでは不可分性が保証されることが分かりました。
では、変更内容を意図的にキャンセルするとしたらどうでしょう? 次のように rollback コマンドを使って試してみます。
Kill ^a
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TROLLBACK 1
ZWRITE ^a
Nothing got out
またしても、何も保存されませんでした。
グローバルは、リレーショナルテーブルよりも低い層でデータを格納する構造であることを覚えていますか?また、グローバルデータベースでは、インデックスもグローバルとして格納されます。 従い、永続性の要件を満たすには、グローバルノードの値が変更される同じトランザクションにインデックの変更も含める必要があります。
例えば、^person というグローバルがあり、それに個人情報を格納するとします。キーにはソーシャルセキュリティ番号 (SSN) を使用します。
^person(1234567, 'firstname') = 'Sergey'
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
...
以下のように、^index というキーを作成し、ラストネームだけ、もしくはファーストネームとラストネームの組み合わせを使って、素早く検索できるようにしました。
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1
データベースの永続性を維持するには、person を以下のように追加する必要があります。
TSTART
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1
TCOMMIT
従い、person を削除する場合は、以下のトランザクションを使う必要があります。
TSTART
Kill ^person(1234567)
Kill ^index(‘Kamenev’, ‘Sergey’, 1234567)
TCOMMIT
つまり、グローバルのような下位層の格納形式を使う場合、どのようなロジックを使ってアプリケーションの永続性の要件を満たすかは、プログラマー次第ということです。
幸い、IRIS にはトランザクションを整理して、アプリケーションの永続性を保証するためのコマンドが備えられています。 SQL が使用される場合、IRIS は内部でこれらのコマンドを実行して、INSERT、UPDATE、DELETE 式が実行されるときに、基となるグローバルのデータ構造を持続します。 もちろん、トランザクションを開始および停止する SQL コマンドは、IRIS SQL にも備えられているので、(SQL) アプリケーションロジックに活用することができます。
ここからが本番です。 多くのユーザーが同時に同じデータベースにアクセスして、同じデータを変更するとしましょう。 多くのデベロッパーが同じコードリポジトリにアクセスし、多くのファイルの変更内容を同時にコミットしようと試みる状況に似ています。
データベースはすべてをリアルタイムに処理しなくてはいけません。 大手企業なら通常はバージョンコントロール (ブランチのマージや競合解決の管理など) の担当者がいて、かつ データベースはこれをリアルタイムに処理する必要があることを考えると、その問題の複雑さや、データベースとその機能を支えるコードを適切に設計することが大切なのは言うまでもありません。
データベースは、ユーザーの操作が意味することを理解できなければ、ユーザーが同じデータを操作する際に起こる競合を回避することもできません。 他のトランザクションと矛盾するトランザクションを 1 つキャンセルするか、それらを順番に実行することしかできません。
また、トランザクションの実行中 (コミットの前) は、データベースの状態の一貫性が失われている能性もあります。 一貫性を失ったデータベースの状態に他のトランザクションがアクセスできるのはよくありません。 しかし、リレーショナルデータベースでは、スナップショットを作成したり、複数バージョンの行を使用したりするなど、アクセスできてしまう方法がたくさんあります。
複数のトランザクションが並列に実行される場合は、お互いを干渉しないことが大切です。 それを確保するのが分離性です。
SQL では、分離性は分離する程度の順に 4 つのレベルで定義されます。 以下がその 4 つのレベルです。
では、それぞれのレベルを一つずつ見ていきましょう。 各レベルの実装コストは、スタックを上がるにつれてほぼ指数関数的に増加していきますので、ご注意ください。
READ UNCOMMITTED は、分離の一番低いレベルですが、一番速いレベルでもあります。 トランザクションは、別のトランザクションによりコミットされた変更内容を読み取ることができます。
READ COMMITTED は、次の分離レベルで、譲歩することを意味します。 トランザクションは、コミットの前にお互いの変更を読み取ることはできませんが、コミットの後ならどの変更でも読み取ることができます。
長時間に渡って実行されるトランザクション (T1) があり、その間に T1 と同じデータを操作するトランザクション T2、T3 ... Tn がそれぞれでコミットしたとします。 このような場合は、T1 のデータをリクエストする度に異なる結果が得られる可能性があります。 これは Non-Repeatable Read (非再現リード) と呼ばれています。
次の分離レベルは、REPEATABLE READ です。データの読み取りをリクエストすると、その都度結果のスナップショットがとられるため、ここではもはや非再現リードは起りません。 同じトランザクションの実行中に同じデータがもう一度リクエストされることがあれば、スナップショットが使用されます。 但し、この分離レベルでは、ファンタムデータ (並列に実行されていた別のトランザクションによってコミットされた新しい文字列) が読み取られる可能性があります。
一番高い分離レベルは、SERIALIZABLE です。 トランザクションで使用 (読み取りまたは変更) されたデータに他のトランザクションがアクセスできるのは、最初のトランザクションが終了した後に限定されるという特徴があります。
まずは、トランザクションのあるスレッドとないスレッドとの間で操作が分離されているかどうかを確認してみましょう。 ターミナルを 2 つ開いて、以下を入力します。
| Kill ^t Write ^t(1) 2 |
分離はされていません。 片方のスレッドはトランザクションを開くと、もう片方のスレッドの動作を見ることができます。
それでは、異なるスレッドで実行中のトランザクションがお互いの中の状況を見れるかどうかを確認しましょう。 ターミナルウィンドウを 2 つ開き、2 つのトランザクションを並列に実行します。
| Kill ^t TSTART Write ^t(1) 2 |
画面に A 3 が表示されます。 ここでは、一番シンプルで一番速い分離レベル READ UNCOMMTTED が設定されています。
原則として、グローバルのような常にスピードを優先する下位層のデータ表現手段では、このレベルが主流となっています。 IRIS SQL では、トランザクションの異なる分離レベルを選択できますが、直接グローバルを操作する時にもっと高い分離レベルが必要になったらどうすればよいでしょう?
ここで、分離レベルの目的とそれぞれの仕組みについて考える必要があります。 例えば、低い分離レベルは、データベースを高速化するための譲歩を目的にしています。
最高の分離レベルを提供する SERIALIZABLE では、並列に実行されたトランザクションの結果がそれらを順に実行した場合の結果と同じになることが保証されます。 これにより、衝突を完全に防ぐことができます。 これは、ObjectScript で適切にロックを使用しても実現できる上に、適用方法も多数あります。 つまり、LOCK コマンドを使えば、普通のロックやインクリメンタルロックを作成したり、ロックを複数個作成することもできます。
それでは、ロックを使って異なる分離レベルを作る方法を見てみましょう。 ObjectScript では、LOCK オペレーターを使います。 このオペレーターは、データを変更するのに必要な排他ロックに限らず、共有ロックと呼ばれるロックも許可します。 共有ロックは、複数のスレッドがデータを読み取る目的で同時にアクセスできるロックであり、そのデータが読み取りプロセス中に他のプロセスによって変更されることはありません。
ロック方式に関する詳細については、「ロックと並行処理の制御」と題した記事をお読みください。 ツーフェーズロック方式の詳細については、Wikipedia で「ツーフェーズロック」と題された記事をお読みください。
難しいのは、トランザクションの実行中に、データの状態の一貫性が失われ、そのデータが他のプロセスに表示されてしまうという点です。 これはどうすれば回避できるのか? この例では、ロックを使って、データベースの状態が一貫して持続される可視性ウィンドウを作成します。 可視性ウィンドウには、ロックを使ってアクセスします。
同じデータに使われているロックは、再利用できるほか、複数のプロセスによる取得が可能です。 これらのロックを使うことで、データが他のプロセスにより変更されるのを防ぎます。 つまり、データベースの状態を一貫させるためのウィンドウを形成するのに使用されるというわけです。
一方の排他ロックは、データを変更するときに使用されるもので、一度に 1 つのプロセスしか取得できません。
排他ロック方式を使用できるシナリオは、2 つあります。 1 つ目は、対象となるデータに対し他のプロセスがロックを取得していないため、どのプロセスでもアクセスできるという場合。 2 つ目は、対象となるデータに対し共有ロックを取得し、かつ排他ロックを最初にリクエストしたプロセスだけがそのデータにアクセスできるという場合。

可視性ウィンドウが狭ければ狭いほど、他のプロセスが待機する時間が長くなる一方で、その中にあるデータベースの状態の一貫性は高まります。
READ COMMITTED では、他のスレッドがコミットしたデータしか見えないようになります。 他のトランザクションのデータがまだコミットされていない場合は、古いバージョンが表示されます。 このおかげで、ロックがリリースされるのを待たずに、作業を並列化することができます。
IRIS では、データの古いバージョンを見るには、特殊な裏技が必要になるので、ロックで何とか対処するしかありません。 共有ロックを使って、一貫性が維持されているポイントでのみデータの読み取りを許可する必要があります。
例えば、複数のユーザー「^person」で構成されるデータベースがあり、ユーザー間で資金の送金が行われるとします。 以下のコードは、person 123 から person 242 に資金が送金されるポイントを示しています。
LOCK +^person(123), +^person(242)
TSTART
Set ^person(123, amount) = ^person(123, amount) - amount
Set ^person(242, amount) = ^person(242, amount) + amount
TCOMMIT
LOCK -^person(123), -^person(242)
金額が差し引かれる前の段階で、person 123 に送金のリクエストが出るポイントでは、(デフォルトで) 排他ロックが取得されている必要があります。
LOCK +^person(123)
Write ^person(123)
ですが、ユーザーの個人アカウントのアカウント状況を表示する必要がある場合は、共有ロックを使うか、ロックを一切使わないという選択肢があります。
LOCK +^person(123)#”S”
Write ^person(123)
LOCK -^person(123)#”S”
但し、データベースの操作がほぼ瞬間的に実行されることを許可するのであれば (グローバルはリレーショナルテーブルよりもずっと下位のレベルの構造であることをお忘れなく)、より高い分離レベルが優先されるのでこのレベルはさほど必要ではなくなります。
以下は、READ COMMITTED の完全な例です。
LOCK +^person(123)#”S”, +^person(242)#”S”
Read data (сoncurrent committed transactions can change the data)
LOCK +^person(123), +^person(242)
TSTART
Set ^person(123, amount) = ^person(123, amount) - amount
Set ^person(242, amount) = ^person(242, amount) + amount
TCOMMIT
LOCK -^person(123), -^person(242)
Read data (сoncurrent committed transactions can change the data)
LOCK -^person(123)#”S”, -^person(242)#”S”
REPEATABLE READ は、2 番目に高い分離レベルです。 このレベルでは、1 つのトランザクションでデータが複数回読み取られ、その都度同じ結果が出ること、かつ並列に実行されているトランザクションがそのデータを変更できることを許可します。
分離レベルを確実に REPEATABLE READ にするには、データに対し排他ロックを取得します。それにより、分離レベルは自動的に SERIALIZABLE に引き上げられます。
LOCK +^person(123, amount)
read ^person(123, amount)
その他の操作 (並列ストリームは ^person(123, amount) を変更しようと試みますができません)
change ^person(123, amount)
read ^person(123, amount)
LOCK -^person(123, amount)
ロックがコンマで区切られている場合は、連続的に取得されていることを意味します。 ですが、以下のようにリストアップされている場合は、一斉にアトミックに取得されます。
LOCK +(^person(123),^person(242))
SERIALIZABLE は、最も高い分離レベルであり、コストも一番高くなります。 上の例で行ったように、従来のロックを操作する場合は、同じデータを持つすべてのトランザクションが連続的に実行されるようにロックを設定する必要があります。 このアプローチでは、ほぼすべてのロックが排他ロックである必要があり、パフォーマンスを確保するためにグローバルの最も小さいフィールドに対し取得される必要もあります。
^person グローバルから金額を差し引くという場合、SERIALIZABLE 以外のレベルは使えません。 資金の消費は、あくまで連続的なアクションである必要があり、そうでなければ同じ金額が複数回も消費されることになります。
docker kill my-iris コマンドを使い、コンテナの hard cut-off をテストしたところ、 データベースはこれらのテストに対して良い結果を出し、 問題は一切見られませんでした。
IRIS Management ポータルでご紹介している以下のツールがお役に立つかもしれません:
InterSystems IRIS は、グローバルを使ったアトミックかつ永続的なトランザクションをサポートしています。 データベースとグローバルの一貫性を確保するには、ある程度のプログラミングやトランザクションが必要です。それは、外部キーなどの複雑な構造が組み込まれていないためです。
ロックを取得せずにグローバルを使うのは、READ UNCOMMITTED の分離レベルを使うのと同じことですが、ロックを使えばそのレベルを SERIALIZABLE に引き上げることができます。 グローバルを使って実現可能な正確性およびトランザクションの処理速度は、プログラマーのスキルと意図によって大きく左右します。 データを読み取るときに、共有ロックが使用される幅が広ければ広いほど、それだけ分離レベルは高くなります。 また、排他ロックが使用される幅が狭ければ狭いほど、それだけトランザクションの処理速度も速くなります。
これは InterSystems FAQ サイトの記事です。
管理ポータル:システムオペレーション > データベース にあるオプションボタン(ラジオボタン)「空き容量ビュー」で表示される内容は、システムクラス SYS.Database のFreeSpace クエリで取得可能です。
次のようなコードでクエリを実行します。
例:
(%SYSネームスペースにて作成、実行します)
/// ZISJ.mac
Set stmt=##class(%SQL.Statement).%New()
Set status=stmt.%PrepareClassQuery("SYS.Database","FreeSpace")
Set rs=stmt.%Execute()
While rs.%Next() {
Write !
For i=1:1:9 {
Write rs.%GetData(i),","
}
}
もしくは、以下のようにも行えます。