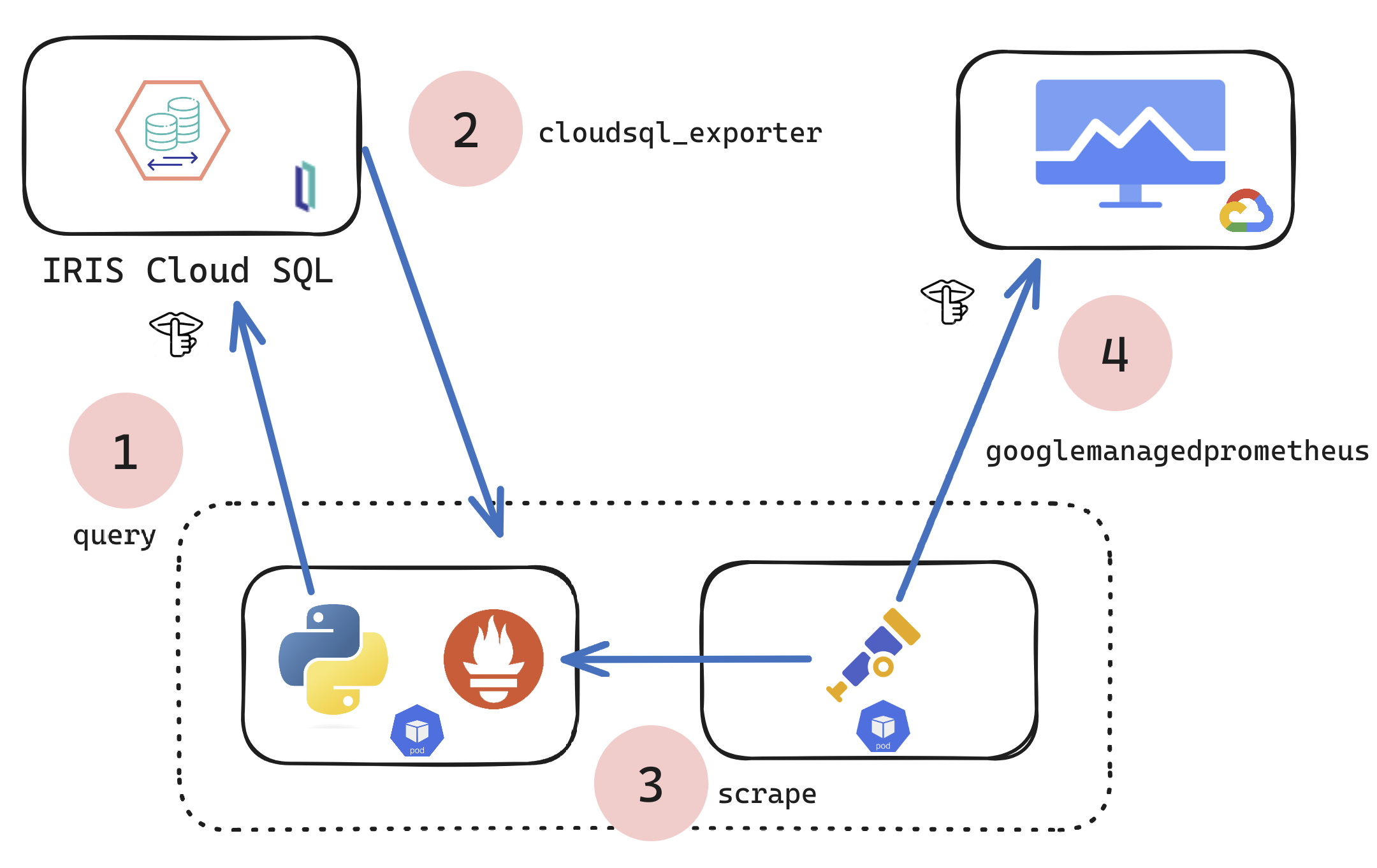
新しい InterSystems IRIS® Cloud SQL と InterSystems IRIS® Cloud IntegratedML® クラウド製品のユーザーであり、デプロイメントのメトリクスにアクセスして独自の可観測性プラットフォームに送信しようと考えている方のために、メトリクスを Google Cloud Platform Monitoring(旧称 StackDriver)に送信して手っ取り早く行う方法をご紹介します。
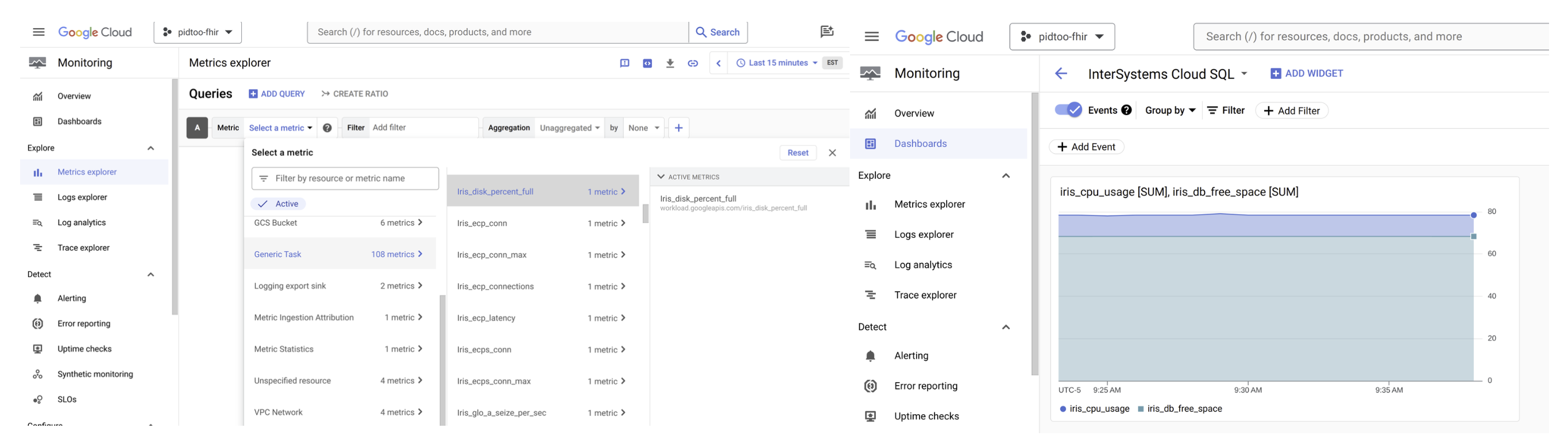
クラウドポータルには、概要メトリクス表示用のトップレベルのメトリクスが含まれており、ユーザーに公開されているメトリクスエンドポイントを使用しますが、ある程度探索しなければ、そこにあることには気づきません。
🚩 このアプローチは、「今後名前が付けられる予定の機能」を利用している可能性があるため、それを踏まえると将来性があるものではなく、確実に InterSystemsでサポートされているアプローチではありません。
.png) | .png) |
では、より包括的なセットをエクスポートしたい場合はどうでしょうか?この技術的な記事/例では、メトリクスを取得して可観測性に転送する方法を紹介します。Open Telemetry Collector を使用して、任意のメトリクスターゲットを取得し、任意の可観測性プラットフォーム送信できるように、ニーズに合わせて変更することができます。
上記の結果に導く仕組みは多数の方法で得られますが、ここでは Kubernetes pod を使用して、1 つのコンテナーで Python スクリプトを実行し、もう 1 つのコンテナーで Otel を実行して、メトリクスのプルとプッシュを行います... 自分のやり方を選択することはできますが、この例と記事では、k8s を主人公に Python を使って行います。
手順:
- 前提条件
- Python
- コンテナー
- Kubernetes
- Google Cloud Monitoring
前提要件:
- IRIS® Cloud SQL の有効なサブスクリプション
- 実行中の 1 つのデプロイメント(オプションで Integrated ML を使用)
- 環境に提供するシークレット
環境変数
ENV IRIS_CLOUDSQL_USER 'user' ENV IRIS_CLOUDSQL_PASS 'pass'
☝ これは https://portal.live.isccloud.io の認証情報です。
ENV IRIS_CLOUDSQL_USERPOOLID 'userpoolid' ENV IRIS_CLOUDSQL_CLIENTID 'clientid' ENV IRIS_CLOUDSQL_API 'api'
☝ これはブラウザの開発ツールから取得する必要があります。
- `aud` = clientid
- `userpoolid`= iss
- `api` = request utl

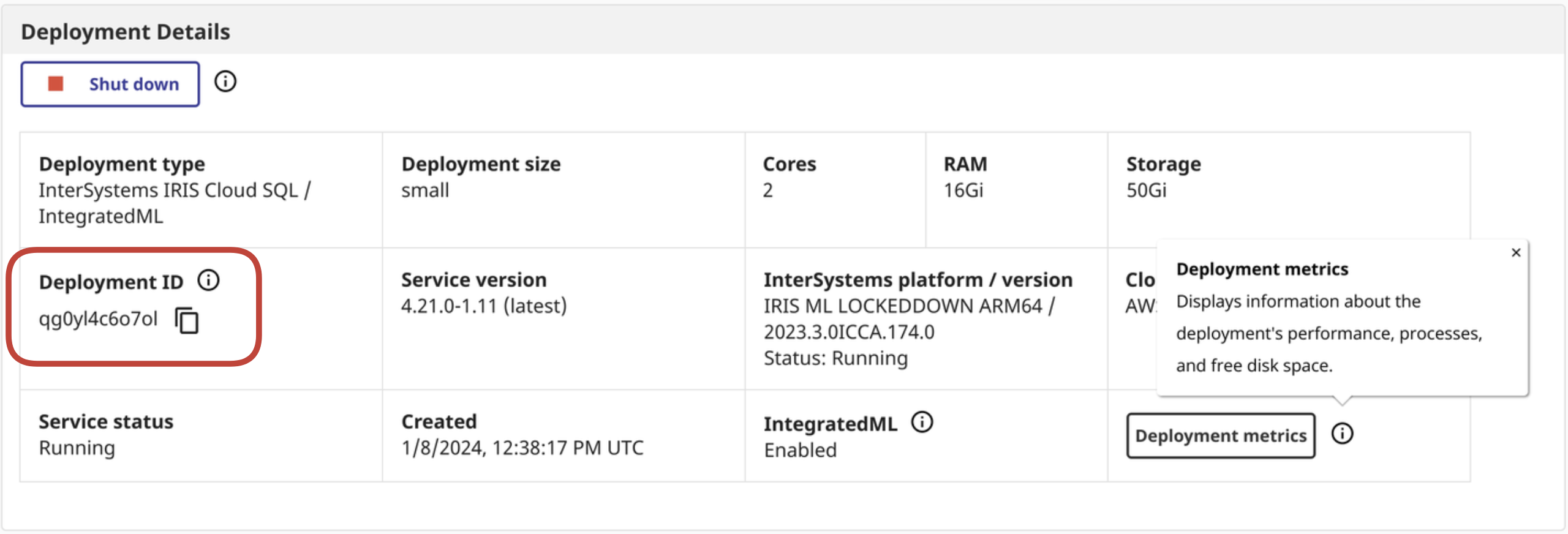
ENV IRIS_CLOUDSQL_DEPLOYMENTID 'deploymentid'
☝これはクラウドサービスポータルから取得できます
Python:
以下に、クラウドポータルからメトリクスを取得し、それを Otel Collectorが取得するメトリクスとしてローカルにエクスポートする Python ハッキングを示します。
import time
import os
import requests
import json
from warrant import Cognito
from prometheus_client.core import GaugeMetricFamily, REGISTRY, CounterMetricFamily
from prometheus_client import start_http_server
from prometheus_client.parser import text_string_to_metric_families
classIRISCloudSQLExporter(object):definit(self):
self.access_token = self.get_access_token()
self.portal_api = os.environ['IRIS_CLOUDSQL_API']
self.portal_deploymentid = os.environ['IRIS_CLOUDSQL_DEPLOYMENTID']
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">collect</span><span class="hljs-params">(self)</span>:</span>
<span class="hljs-comment"># Requests fodder</span>
url = self.portal_api
deploymentid = self.portal_deploymentid
print(url)
print(deploymentid)
headers = {
<span class="hljs-string">'Authorization'</span>: self.access_token, <span class="hljs-comment"># needs to be refresh_token, eventually</span>
<span class="hljs-string">'Content-Type'</span>: <span class="hljs-string">'application/json'</span>
}
metrics_response = requests.request(<span class="hljs-string">"GET"</span>, url + <span class="hljs-string">'/metrics/'</span> + deploymentid, headers=headers)
metrics = metrics_response.content.decode(<span class="hljs-string">"utf-8"</span>)
<span class="hljs-keyword">for</span> iris_metrics <span class="hljs-keyword">in</span> text_string_to_metric_families(metrics):
<span class="hljs-keyword">for</span> sample <span class="hljs-keyword">in</span> iris_metrics.samples:
labels_string = <span class="hljs-string">"{1}"</span>.format(*sample).replace(<span class="hljs-string">'\''</span>,<span class="hljs-string">"\""</span>)
labels_dict = json.loads(labels_string)
labels = []
<span class="hljs-keyword">for</span> d <span class="hljs-keyword">in</span> labels_dict:
labels.extend(labels_dict)
<span class="hljs-keyword">if</span> len(labels) > <span class="hljs-number">0</span>:
g = GaugeMetricFamily(<span class="hljs-string">"{0}"</span>.format(*sample), <span class="hljs-string">'Help text'</span>, labels=labels)
g.add_metric(list(labels_dict.values()), <span class="hljs-string">"{2}"</span>.format(*sample))
<span class="hljs-keyword">else</span>:
g = GaugeMetricFamily(<span class="hljs-string">"{0}"</span>.format(*sample), <span class="hljs-string">'Help text'</span>, labels=labels)
g.add_metric([<span class="hljs-string">""</span>], <span class="hljs-string">"{2}"</span>.format(*sample))
<span class="hljs-keyword">yield</span> g
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">get_access_token</span><span class="hljs-params">(self)</span>:</span>
<span class="hljs-keyword">try</span>:
user_pool_id = os.environ[<span class="hljs-string">'IRIS_CLOUDSQL_USERPOOLID'</span>] <span class="hljs-comment"># isc iss </span>
username = os.environ[<span class="hljs-string">'IRIS_CLOUDSQL_USER'</span>]
password = os.environ[<span class="hljs-string">'IRIS_CLOUDSQL_PASS'</span>]
clientid = os.environ[<span class="hljs-string">'IRIS_CLOUDSQL_CLIENTID'</span>] <span class="hljs-comment"># isc aud </span>
print(user_pool_id)
print(username)
print(password)
print(clientid)
<span class="hljs-keyword">try</span>:
u = Cognito(
user_pool_id=user_pool_id,
client_id=clientid,
user_pool_region=<span class="hljs-string">"us-east-2"</span>, <span class="hljs-comment"># needed by warrant, should be derived from poolid doh</span>
username=username
)
u.authenticate(password=password)
<span class="hljs-keyword">except</span> Exception <span class="hljs-keyword">as</span> p:
print(p)
<span class="hljs-keyword">except</span> Exception <span class="hljs-keyword">as</span> e:
print(e)
<span class="hljs-keyword">return</span> u.id_token
ifname == 'main':
start_http_server(<span class="hljs-number">8000</span>)
REGISTRY.register(IRISCloudSQLExporter())
<span class="hljs-keyword">while</span> <span class="hljs-keyword">True</span>:
REGISTRY.collect()
print(<span class="hljs-string">"Polling IRIS CloudSQL API for metrics data...."</span>)
<span class="hljs-comment">#looped e loop</span>
time.sleep(<span class="hljs-number">120</span>)</code></pre>
Docker:
FROM python:3.8ADD src /src
RUN pip install prometheus_client
RUN pip install requests
WORKDIR /src
ENV PYTHONPATH '/src/'ENV PYTHONUNBUFFERED=1ENV IRIS_CLOUDSQL_USERPOOLID 'userpoolid'ENV IRIS_CLOUDSQL_CLIENTID 'clientid'ENV IRIS_CLOUDSQL_USER 'user'ENV IRIS_CLOUDSQL_PASS 'pass'ENV IRIS_CLOUDSQL_API 'api'ENV IRIS_CLOUDSQL_DEPLOYMENTID 'deploymentid'RUN pip install -r requirements.txt
CMD ["python" , "/src/iris_cloudsql_exporter.py"]docker build -t iris-cloudsql-exporter . docker image tag iris-cloudsql-exporter sween/iris-cloudsql-exporter:latest docker push sween/iris-cloudsql-exporter:latest
デプロイメント:
k8s、ネームスペースを作成します:
kubectl create ns iris
k8s、シークレットを追加します:
kubectl create secret generic iris-cloudsql -n iris \
--from-literal=user=$IRIS_CLOUDSQL_USER \
--from-literal=pass=$IRIS_CLOUDSQL_PASS \
--from-literal=clientid=$IRIS_CLOUDSQL_CLIENTID \
--from-literal=api=$IRIS_CLOUDSQL_API \
--from-literal=deploymentid=$IRIS_CLOUDSQL_DEPLOYMENTID \
--from-literal=userpoolid=$IRIS_CLOUDSQL_USERPOOLIDotel、構成を作成します:
apiVersion: v1
data:
config.yaml: |
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'IRIS CloudSQL'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 30s
scrape_timeout: 30s
static_configs:
- targets: ['192.168.1.96:5000']
metrics_path: /
exporters:
googlemanagedprometheus:
project: "pidtoo-fhir"
service:
pipelines:
metrics:
receivers: [prometheus]
exporters: [googlemanagedprometheus]
kind: ConfigMap
metadata:
name: otel-config
namespace: iris
k8s、otel 構成を configmap としてロードします:
kubectl -n iris create configmap otel-config --from-file config.yaml
k8s、ロードバランサー(確実にオプション)、MetalLB をデプロイします。これはクラスタ外部からグスクレイピングして検査するために行っています。
cat <<EOF | kubectl apply -f -n iris - apiVersion: v1 kind: Service metadata: name: iris-cloudsql-exporter-service spec: selector: app: iris-cloudsql-exporter type: LoadBalancer ports: - protocol: TCP port: 5000 targetPort: 8000 EOF
gcp、Google Cloud へのキーが必要です。サービスアカウントにスコープを設定する必要があります
roles/monitoring.metricWriter
kubectl -n iris create secret generic gmp-test-sa --from-file=key.json=key.json
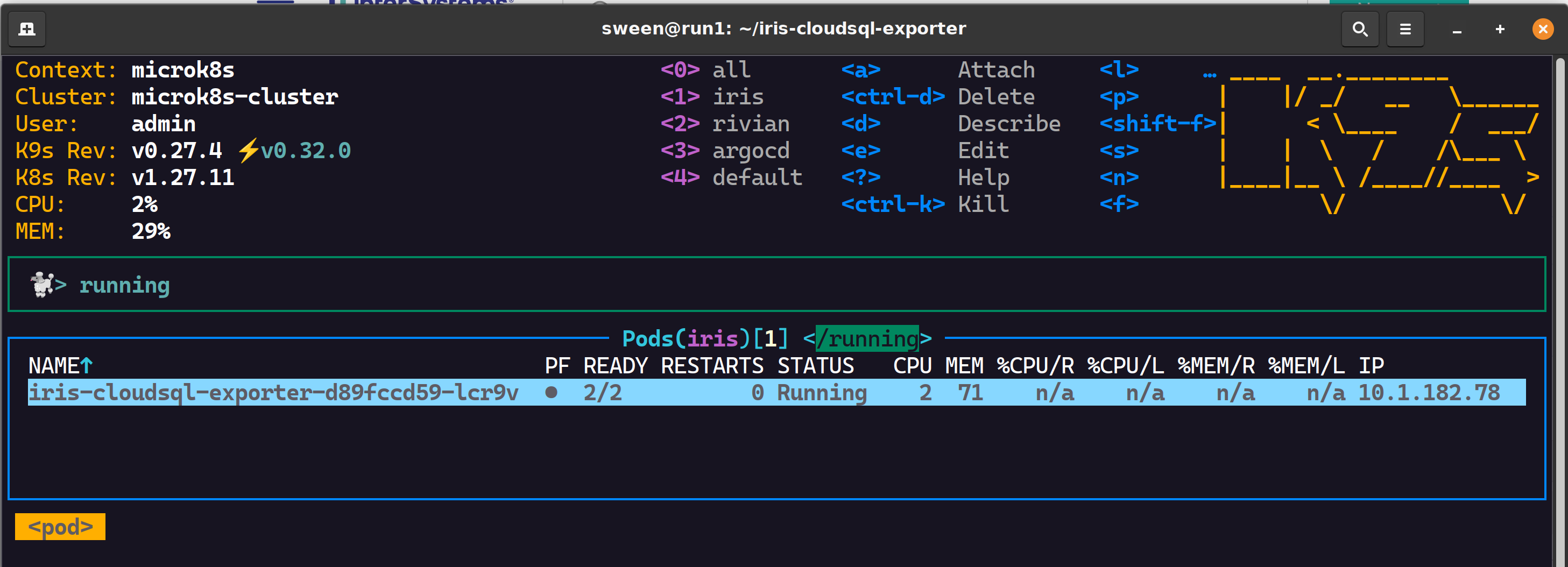
k8s; deployment/pod そのもの。2 つのコンテナー:
kubectl -n iris apply -f deployment.yaml
実行
特に問題がなければ、ネームスペースを詳しく調べて、状況を確認してみましょう。
✔ GCP と Otel 用の 2 つの configmap
✔ 1 つのロードバランサー
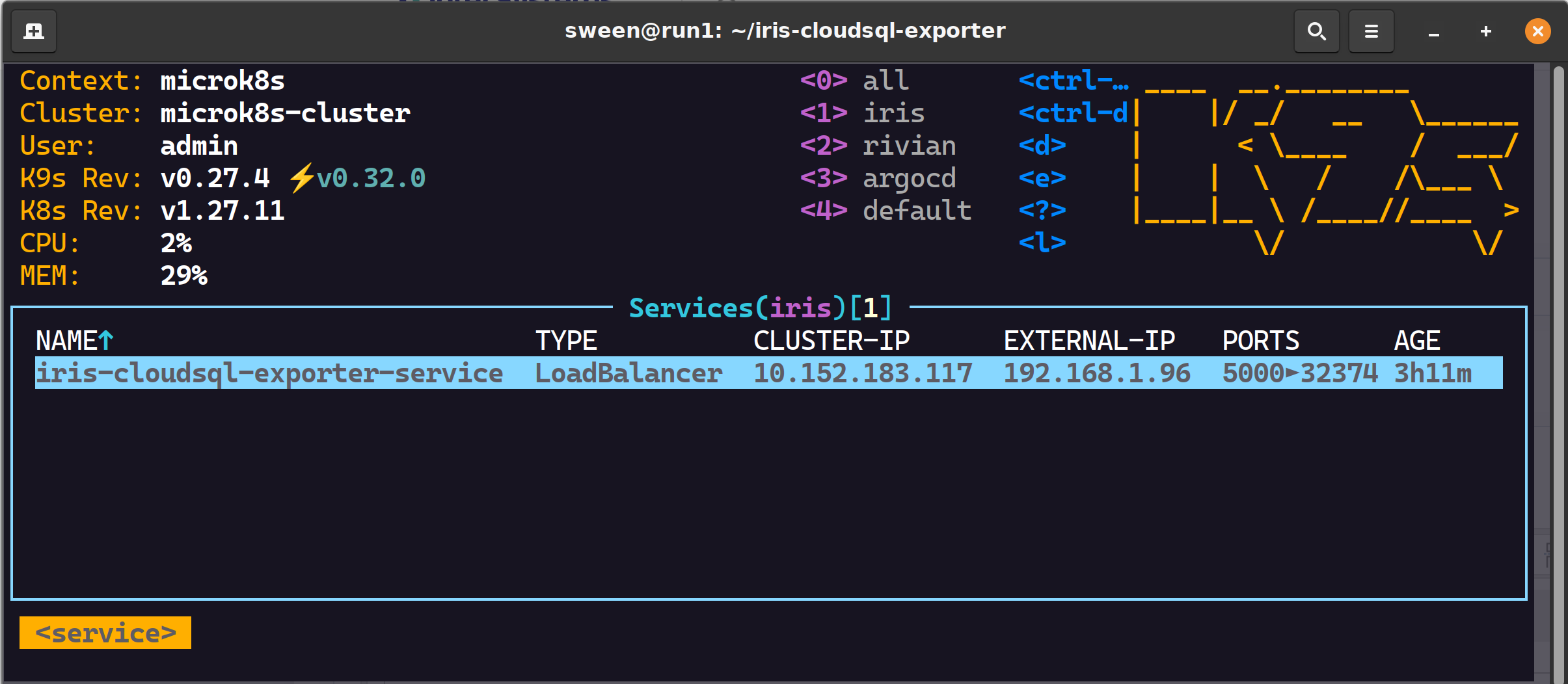
✔ 1 つの pod、2 つのコンテナーが正しくスクレイピングされます

Google Cloud Monitoring
可観測性を調べてメトリクスが正しく受信されていることを確認し、可観測性を高めましょう!



.png)
.png)
.png)
.png)

.png)
.png)
