開発者の皆さん、こんにちは!
多くの方が、Open Exchange と GitHub で InterSystems ObjectScript ライブラリを公開しています。
でも、開発者がプロジェクトの使用とコラボレーションを簡単に行えるようにするにはどうしていますか?
この記事では、ファイルの標準セットをリポジトリにコピーするだけで、ObjectScript プロジェクトを簡単に起動して作業する方法をご紹介します。
では始めましょう!
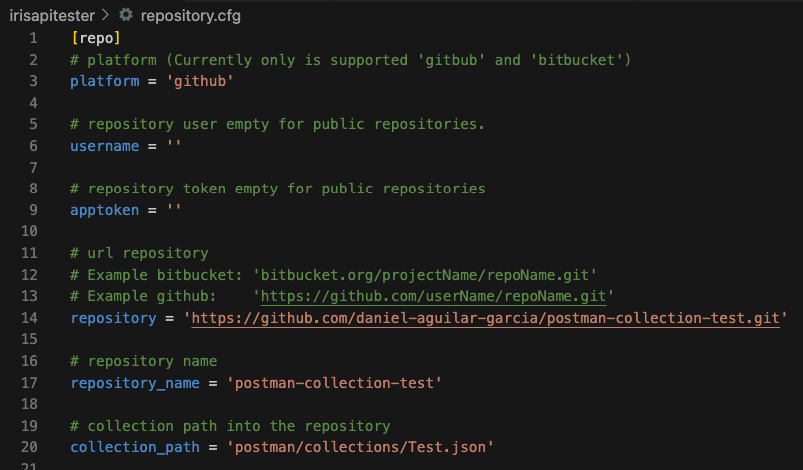
概要 - 以下のファイルをこちらのリポジトリからお使いのリポジトリにコピーしてください。
Dockerfile
docker-compose.yml
Installer.cls
iris.script
settings.json{#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
.dockerignore{#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
.gitattributes{#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
.gitignore{#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
すると、プロジェクトを起動して共同作業する標準的な方法が得られます。 以下は、この仕組みと動作する理由についての記事です。
注意: この記事では、InterSystems IRIS 2019.1 以降で実行可能なプロジェクトを対象としています。
InterSystems IRIS プロジェクトの起動環境の選択
通常、開発者には、プロジェクト/ライブラリを試して、素早く安全な方法であることを確認していただきたいと思っています。
私見としては、新しいものを素早く安全に起動するには、Docker コンテナが理想的だと考えています。起動、インポート、コンパイル、計算するあらゆるものがホストマシンにとって安全であり、いかなるシステムやコードも破壊されたり損なわれたりすることがないことを開発者に保証できるためです。 何らかの問題が発生した場合は、コンテナを止めて削除するだけで済みます。 アプリケーションが膨大なディスクスペースを占有するのであれば、コンテナを削除すれば、容量を解放できます。 アプリケーションがデータベース構成を破損するのであれば、破損した構成のあるコンテナを削除するだけです。 このように単純で安全なのです。
Docker コンテナでは、安全と標準化を得られます。
バニラ InterSystems IRIS Docker コンテナを実行するには、IRIS Community Edition イメージを実行するのが最も簡単です。
Docker デスクトップをインストールします。
OS のターミナルで以下を実行します。
docker run --rm -p 52773:52773 --init --name my-iris store/intersystems/iris-community:2020.1.0.199.0
- 次に、ホストブラウザで管理ポータルを開きます。
http://localhost:52773/csp/sys/UtilHome.csp
または IRIS へのターミナルを開きます。
docker exec -it my-iris iris session IRIS
IRIS コンテナが不要になれば、それを停止します。
docker stop my-iris
さて、 IRIS を Docker コンテナで実行しますが、 開発者にはコードを IRIS にインストールして、いくらかの設定を行ってほしいと考えているとします。 以下ではこれについて説明します。
ObjectScript ファイルのインポート
最も単純な InterSystems ObjectScript プロジェクトには、クラス、ルーチン、マクロ、グローバルなどの一連の ObjectScript ファイルが含めることができます。 命名規則とフォルダ構造の提案についての記事をご覧ください。
問題は、このコードをどのようにして IRIS コンテナにインポートするかです。
ここで役立つのが Dockerfile です。これを使用して、バニラ IRIS コンテナを取得し、リポジトリから IRIS にすべてのコードをインポートして、必要に応じて IRIS で設定を行います。 リポジトリに Dockerfile を追加する必要があります。
ObjectScript テンプレートリポジトリから取得した Dockerfile を調べてみましょう。
ARG IMAGE=store/intersystems/irishealth:2019.3.0.308.0-community
ARG IMAGE=store/intersystems/iris-community:2019.3.0.309.0
ARG IMAGE=store/intersystems/iris-community:2019.4.0.379.0
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
最初の ARG の行は $IMAGE 変数を設定しており、それを FROM で使用します。 これは、$IMAGE 変数を変更するために FROM の前の最後の行が何であるかだけを切り替えて、さまざまな IRIS バージョンでコードをテスト/実行するのに適しています。
以下のコードがあります。
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
これは、IRIS 2020 Community Edition ビルド 199 を使用するということです。
リポジトリからコードをインポートするため、リポジトリのファイルを Docker コンテナにコピーする必要があります。 以下の行はそれを行います。
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src srcUSER root - ここで、ユーザーをルートに切り替えて、フォルダを作成してファイルを Docker にコピーします。
WORKDIR /opt/irisapp - この行では、ファイルをコピーする workdir をセットアップしています。
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp - ここでは、irisowner ユーザーと IRIS を実行するグループに権限を付与しています。
USER irisowner - ユーザーを root から irisowner に切り替えます。
COPY Installer.cls . - workdir のルートに Installer.cls をコピーしています。 このピリオドを忘れないでください。
COPY src src - ソースファイルをリポジトリの src フォルダから Docekr の workdir の src フォルダにコピーします。
次のブロックでは、初期スクリプトを実行し、インストーラーと ObjectScript コードを呼び出します。
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
COPY iris.script / - iris.script をルートディレクトリにコピーします。 コンテナをセットアップするために呼び出す ObjectScript が含まれます。
RUN iris start IRIS</span> - IRIS を起動します。
&& iris session IRIS < /tmp/iris.script - IRIS ターミナルを起動し、それに最初の ObjectScript を入力します。
以上です! Docker にファイルをインポートする Dockerfile ができました。 installer.cls と iris.script の 2 つのファイルが残っています。ではそれらを詳しく見てみましょう。
Installer.cls
Class App.Installer
{
XData setup
{
<Manifest>
<Default Name="SourceDir" Value="#{$system.Process.CurrentDirectory()}src"/>
<Default Name="Namespace" Value="IRISAPP"/>
<Default Name="app" Value="irisapp" />
<Namespace Name="${Namespace}" Code="${Namespace}" Data="${Namespace}" Create="yes" Ensemble="no">
<Configuration>
<Database Name="${Namespace}" Dir="/opt/${app}/data" Create="yes" Resource="%DB_${Namespace}"/>
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
</Configuration>
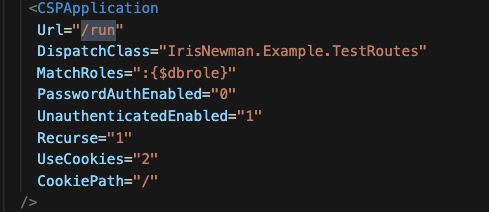
<CSPApplication Url="/csp/${app}" Directory="${cspdir}${app}" ServeFiles="1" Recurse="1" MatchRoles=":%DB_${Namespace}" AuthenticationMethods="32"
/>
</Namespace>
</Manifest>
}
ClassMethod setup(ByRef pVars, pLogLevel As %Integer = 3, pInstaller As %Installer.Installer, pLogger As %Installer.AbstractLogger) As %Status [ CodeMode = objectgenerator, Internal ]
{
#; Let XGL document generate code for this method.
Quit ##class(%Installer.Manifest).%Generate(%compiledclass, %code, "setup")
}
}
率直に言って、ファイルのインポートに Installer.cls は必要ありません。 これは 1 行で実行可能です。 ただし、コードをインポートするほかに、CSP アプリのセットアップ、セキュリティ設定の追加、データベースとネームスペースの作成を行わなければなりません。
この Installer.cls では、 IRISAPP という名前で新しいデータベースとネームスペースを作成し、このネームスペースのデフォルトの /csp/irisapp アプリケーションを作成します。
すべては、<Namespace> 要素で行います。
<Namespace Name="${Namespace}" Code="${Namespace}" Data="${Namespace}" Create="yes" Ensemble="no">
<Configuration>
<Database Name="${Namespace}" Dir="/opt/${app}/data" Create="yes" Resource="%DB_${Namespace}"/>
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
</Configuration>
<CSPApplication Url="/csp/${app}" Directory="${cspdir}${app}" ServeFiles="1" Recurse="1" MatchRoles=":%DB_${Namespace}" AuthenticationMethods="32"
/>
</Namespace>そして、Import タグを使って、SourceDir からすべてのファイルをインポートします。
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>この SourceDir は変数であり、現在のディレクトリ/src フォルダに設定されています。
<Default Name="SourceDir" Value="#{$system.Process.CurrentDirectory()}src"/>これらの設定を含む Installer.cls によって、src フォルダから任意の ObjectScript コードをインポートするわかりやすい新しいデータベース IRISAPP を作成できるという確信を持つことができます。
iris.script
ここに、IRIS コンテナを起動する初期の ObjectScript セットアップコードを挿入してください。
例: 開発にはパスワードのプロンプトは不要であるため、ここでは、installer.cls を読み込んで実行してから、パスワードの初回変更リクエストを回避するために、UserPasswords を永久にしています。
; run installer to create namespace
do $SYSTEM.OBJ.Load("/opt/irisapp/Installer.cls", "ck")
set sc = ##class(App.Installer).setup() zn "%SYS"
Do ##class(Security.Users).UnExpireUserPasswords("*") ; call your initial methods here
halt
docker-compose.yml
docker-compose.yml はなぜ必要なのでしょうか。Dockerfile と同様に、イメージをただビルドして実行するだけではいけないのでしょうか。 もちろん、そうすることは可能です。 ただし、docker-compose.yml を使用すれば作業が単純になります。
通常、docker-compose.yml は、1 つのネットワークに接続された複数の Docker イメージを起動するために使用されます。
docker-compose.yml は、多数のパラメーターを処理する場合に、1 つの Docker イメージの起動をより簡単にするためにも使用できます。 これを使用すれは、ポートのマッピング、ボリューム、VSCode 接続パラメーターなどを Docker に渡すことができます。
version: '3.6'
services:
iris:
build:
context: .
dockerfile: Dockerfile
restart: always
ports:
- 51773
- 52773
- 53773
volumes:
- ~/iris.key:/usr/irissys/mgr/iris.key
- ./:/irisdev/appここでは、サービス iris を宣言しています。これは Dockerfile を使用し、IRIS の 51773、52773、53773 ポートを公開するサービスです。 また、このサービスは、ホストマシンのホームディレクトリの iris.key と期待される IRIS フォルダ、およびソースコードのルートフォルダと /irisdev/app フォルダの 2 つのボリュームのマッピングも行います。
docker-compose によって、セットアップされるパラメーターに関係なく、イメージをビルドして実行するためのコマンドをより短く、統一することができます。
いずれの場合でも、以下のようにしてイメージをビルドします。
$ docker-compose up -d
そして以下のようにして IRIS ターミナルを開きます。
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>
また、docker-compose.yml では、VSCode ObjectScript プラグインの接続もセットアップできます。
.vscode/settings.json
ObjectScript アドオン接続設定に関連しているのは、以下の部分です。
{
"objectscript.conn" :{
"ns": "IRISAPP",
"active": true,
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
}
}ここにあるのは設定です。VSCode ObjectScript プラグインのデフォルトの設定とは異なります。
ここでは、IRISAPP ネームスペース(Installer.cls で作成)に接続すると述べています。
"ns": "IRISAPP",
そして、docker-compose の設定があります。これは、サービス「iris」内の docker-compose ファイルで、VSCode が 52773 がマッピングされているポートに接続すると書かれています。
"docker-compose": {
"service": "iris",
"internalPort": 52773
}52773 について調べたところ、これはマップされたポートが 52773 に対して定義されていないことがわかります。
ports:
- 51773
- 52773
- 53773つまり、ホストマシンのポートで利用できるランダムなポートが取得され、VSCode は自動的にランダムなポートを介して、docker 上でこの IRIS に接続するということです。
これは非常に便利な機能です。IRIS を使用して任意の量の Docker イメージをランダムなポート上で実行し、VSCode をそれらのポートに自動的に接続するオプションが提供されるためです。
他のファイルはどうでしょうか?
以下のファイルもあります。
.dockerignore - 作成した Docker ファイルにコピーしない不要なホストマシンのファイルをフィルターするために使用できるファイル。 通常、.git や .DS_Store は必須です。
.gitattributes - git の属性。ソース内の ObjectScript ファイルの行末を統一します。 Windows と Mac/Ubuntu オーナーがリポジトリで共同作業する場合に非常に便利です。
.gitignore - Git で変更履歴を追跡しないファイル。 通常、.DS_Store などの非表示の OS レベルのファイルです。
以上です!
リポジトリを Docker 実行可能にし、コラボレーションしやすくするにはどうすればよいでしょうか。
このリポジトリをクローンします。
以下のファイルをすべてコピーします。
Dockerfile
docker-compose.yml
Installer.cls
iris.script
settings.json{#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
.dockerignore{#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
.gitattributes{#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
.gitignore{#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
上記をリポジトリにコピーしてください。
Dockerfile のこの行を IRIS にインポートする ObjectScript のあるリポジトリ内のディレクトリに一致するように変更します(in /src フォルダにある場合は変更しません)。
それだけです。 すべての人(あなた自身も含む)が、新しい IRISAPP ネームスペースでコードをインポートできるようになります。
プロジェクトの起動方法
IRIS で ObjectScript プロジェクトを実行するためのアルゴリズムは以下の通りです。
プロジェクトをローカルに Git clone します。
プロジェクトを実行します。
$ docker-compose up -d
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>zn "IRISAPP"
**開発者によるプロジェクトへの貢献方法 **
リポジトリをフォークして、フォークされたリポジトリをローカルに Git clone します。
VSCode でフォルダを開きます(Docker と ObjectScript の拡張機能が VSCode にインストールされている必要があります)。
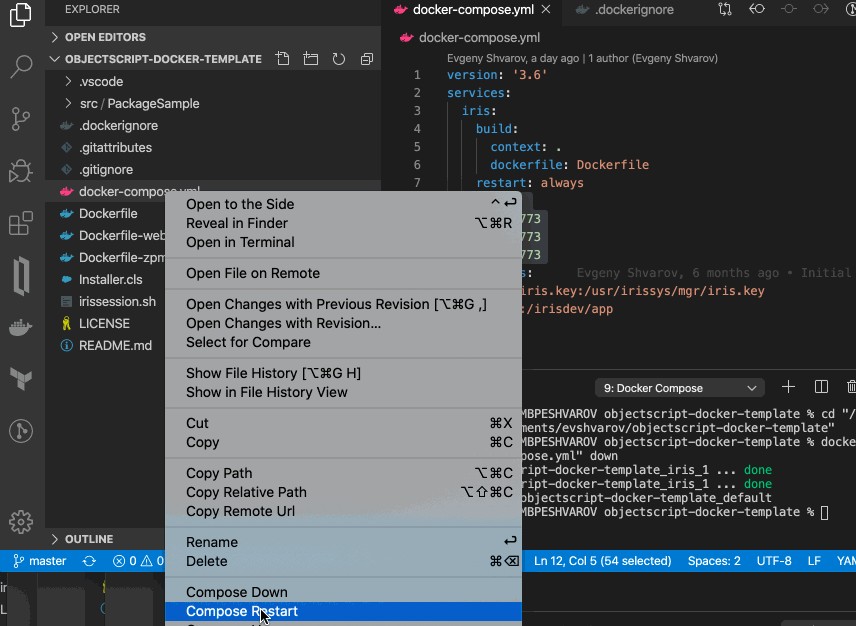
docker-compose.yml を右クリックし、再起動します。VSCode ObjectScript が自動的に接続され、編集/コンパイル/デバッグできるうようになります。
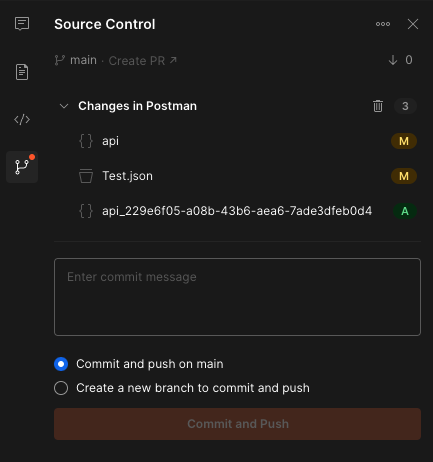
リポジトリに変更をコミット、プッシュ、およびプルリクエストします。
以下は、この仕組みを説明する簡単な Gif です。
以上です! それでは、コーディングをお楽しみください!
.png) ボタンをクリックするだけで始められます👍
ボタンをクリックするだけで始められます👍












.png)
.png)
.png)



.png)



.png)




.png)

.png)
.png)
 )
).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png) ボタンをクリックするだけで
ボタンをクリックするだけで.png)
.png) 👈開発者コミュニティのページの左端にこんなリンク集がありますので、「
👈開発者コミュニティのページの左端にこんなリンク集がありますので、「.png)








