Ansible は Caché とアプリケーションコンポーネントをいかに迅速にデータプラットフォームのベンチマークにデプロイするかという課題を解決するのに役立ちました。 同じツールと方法をテストラボ、トレーニングシステム、開発環境、またはその他の環境の立ち上げも使うことができます。 顧客サイトにアプリケーションをデプロイする場合、デプロイの大部分を自動化し、アプリケーションのベストプラクティス標準に合わせてシステム、Caché、アプリケーションを確実に構成することができます。
概要
テクノロジーアーキテクトである私たちのグループの仕事の一つに、さまざまなベンダーのハードウェアやオペレーティングシステムでの InterSystems データプラットフォームのベンチマークがあります。 多くの場合、インフラストラクチャはリリース前のものであり、返却や他者への引き渡しが必要になるまでの時間が決まっているため、ベンチマークを迅速かつ正確に設定し、実際のベンチマーク作業にできるだけ多くの時間をかけることが不可欠です。
私たちは長年にわたってシェルスクリプトレットとチートシートやチェックリストからのカットアンドペーストを使用し、多くのベンチマークインストール作業を自動化していましたが、多くのサーバーがあり、異なるオペレーティングシステムを使用する場合は特に非常に激しくエラーが発生する傾向がありました。SLES 11、Red Hat 6、Red Hat 7、AIX などでのサービスのインストールや使用には、微妙で厄介な違いがある場合があるからです。
私はシステムの自動構成と管理に使用できるいくつかのソフトウェアオプションを検討した後、データプラットフォームアプリケーションとベンチマークコンポーネントをプロビジョニングする作業のために Ansible を選択しました。 なお、Ansible がデプロイと構成に最適なソリューションであると決めつけているわけではありませんのでご了承ください。 私は Ansible を選択する前に、Puppet や Chef などの他のツールの機能や操作を確認しました。 あなたの組織がすでに他のツールを使用しており、あなたがそれを使用できるのなら、私が Ansible で使用する方法やコマンドなどは他のソフトウェアに読み替えることができるはずです。この投稿が、使用しているツールに関係なく役立つことを願っています。
これは、InterSystems データプラットフォームのアプリケーションをデプロイする際に Ansible を使用する方法を説明する連載の最初の投稿です。 この投稿では、Caché をインストールして基盤を構築する方法について説明します。次の投稿では、ソリューションを拡張し、%installer クラスの使用を含むアプリケーションのインストールについて掲載します。 この記事では以下について説明します。
- Ansible の概要とインストール。
- 簡単な管理とスケーリングのための Ansible のレイアウト。
- 1つ以上のサーバーでの Caché のインストール。
Ansible とは?
Ansible では複雑なタスクを自動化しながら1つ以上のサーバーを構成でき、新しいサーバーを非常に簡単に追加できます。 タスクは冪等性が保たれるように設計されています(同じサーバーで同じスクリプトを何度でも実行でき、結果のサーバー構成は同じになります)。
Ansible をプロビジョニングタスク用に選択した主な理由は、システム要件が最小(Linux サーバーに Python 2.7 がインストールされていること)であり、自己完結型のソリューションであることです。Ansible のコードは管理サーバーにのみインストールされ、プッシュアーキテクチャを使用して OpenSSH 経由でターゲットサーバー上のコマンドとスクリプトを実行します。 プロビジョニングされるサーバーにはエージェントは必要ありません。 対照的に、Chef と Puppet はプルクライアントアーキテクチャであり、クライアントサーバー(Web、データベースなど)にソフトウェアが読み込まれ、クライアントは継続的に更新をマスターにポーリングします。 Ansible のプッシュアーキテクチャは、スケジュールに応じてサーバーを段階的に実装するのにも適しています。
Ansible はオープンソースであり、コミュニティによってメンテナンスされています。 Ansible, Inc は 2015 年 から Red Hat が所有しています。 Ansible, Inc は付加価値の高いライフサイクル製品(Ansible Tower)と共に有償のサポートとトレーニングを提供していますが、この投稿で使用されているものはすべてオープンソースのコマンドラインバージョンです。 活発なコミュニティ(Ansible Galaxy)があり、Web サーバー、ftp、Kerbros のインストールなどの多数のタスク用にダウンロードできる既成のソリューションが豊富に存在し、拡充され続けています。 完全なベンチマークのデプロイプロジェクトの例に、RHEL、SLES、または Solaris に(他のプラットフォームと共に)Apache 2.x をインストールして構成するためにダウンロードしてカスタマイズした Apache モジュールを含めています。
Ansible のダウンロードとインストールの手順は、Ansible の Web サイトと github にあります。 質問がある場合や貢献したい場合は、活発なコミュニティがあります。
https://www.ansible.com/get-started
http://docs.ansible.com
Ansible のインストール
この投稿の例は、Red Hat 7.0 および 7.2 が稼働中の VM でテストされています。また、Centos 7 を搭載した私のノートパソコンで VirtualBox と Vagrant を使用し、Ansible コントローラーサーバーの初期テストも行いました。 Caché をコントローラーにインストールする必要はないため、Caché でサポートされているよりも多くのプラットフォームからオペレーティングシステムを選択できます。 話を簡単にするため、私は Red Hat で利用可能な Ansible の最新 rpm バージョン(Ansible 1.9.4)を使用しました。それ以降のバージョンは github から入手できます。
この例では、cache-2015.2.2.805.0-lnxrhx64 をインストールしていますが、HealthShare または Ensemble ディストリビューションにも同じ一般的な手順を適用できます。 後述するように、特定のファイル名、ディレクトリパスなどの変数を使用してインストールオプションをパラメーター化します。
この最初の投稿ではタスクを基本的な Caché のインストールに限定しています。そのため、ほとんどのタスクはプラットフォームに依存しません。 Ansible プレイブックが開始する最初のタスクの 1 つは、ターゲットマシンのマニフェスト(オペレーティングシステム、インターフェースカード、メモリ情報、CPU 数、ディスクレイアウトなど)を取得することです。このターゲットオペレーティングシステムの情報は、ターゲットで実行される実際のコマンドから Ansible スクリプトのコマンドを抽象化するためにコマンドが実行される際に使用されます(Red Hat の service httpd on や SLES の /etc/init.d/apache2 など)。
ここでは皆さんがプラットフォームの説明に従い、説明を読んで管理マシンに Ansible をインストールしたと想定します。
https://docs.ansible.com/ansible/2.9_ja/installation_guide/intro_installation.html
Ansible では Linux システムをコントローラーとして使用する必要がありますが、ターゲットシステムは Linux または Windows にすることができます。 Windows ターゲットの詳細については、Ansible のドキュメントを参照してください。
https://docs.ansible.com/ansible/2.9_ja/user_guide/windows.html
コントローラーシステムのインストール例:RHEL/CentOS 7 64ビット上の Ansible
Red Hat または CentOSでは、Ansible を含む epel-release(Enterprise Linux 用の追加パッケージ)RPM を先にインストールする必要があります。 epel プロジェクトは多くの有用なオープンソースパッケージ(ネットワーク、システム管理、監視など)をまとめて提供しており、主要な Linux ディストリビューション向けに設計されています。
[root@localhost tmp]# wget http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-5.noarch.rpm : : [root@localhost tmp]# rpm -ivh epel-release-7-5.noarch.rpm : : [root@localhost tmp]# yum --enablerepo=epel info ansible Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager Installed Packages Name : ansible Arch : noarch Version : 1.9.4 Release : 1.el7 Size : 7.0 M Repo : installed From repo : epel Summary : SSH-based configuration management, deployment, and task execution system URL : http://ansible.com License : GPLv3+ Description : : Ansible is a radically simple model-driven configuration management, : multi-node deployment, and remote task execution system. Ansible works : over SSH and does not require any software or daemons to be installed : on remote nodes. Extension modules can be written in any language and : are transferred to managed machines automatically. [root@localhost tmp]# [root@localhost tmp]# sudo yum install ansible : : [root@localhost tmp]# ansible --version ansible 1.9.4 configured module search path = None
成功しました。 始めましょう!
Ansible について
インベントリ、プレイブック、モジュール、ロールなどのさまざまな Ansible コンポーネントの使用方法を Ansible のドキュメントでよく確認する必要があります。
管理を単純化し、大規模で複雑なスクリプトファイルを回避するため、事前定義されたディレクトリ構造と検索パスが使用されています。 この投稿では Ansible の推奨事項を使用し、より大きなインストールの例を作ることを検討する際のモデルとして使用できるファイル構造を使用する予定です。
使用されている Ansible モジュールはコメントが付いた分かりやすいもので、github から入手できます。 ファイルをダウンロードして内容を読み、ワークフローの感触をつかんでください。
https://github.com/intersystems/ansible-deploy-cache
この例のベースディレクトリには、次のファイルがあります。
- ansible.cfg:Ansible のデフォルト値を変更します。
- inventory:作業環境を定義し、記述します (サーバー名/IPなど)。
- >任意の名前<.yml ファイル:これらのファイルは、特定のサーバーのロールに対して実行されるタスクセットを記述します。
用語集
今後の説明をより分かりやすくするため、いくつかの Ansible 用語について簡単に説明します。
モジュールは、システムで実行する自動化アクションを作成するビルディングブロックです。 各モジュールは特定のタスク用に構築されており、パラメーターを使用してそのタスクを変更できます。 例えば、ファイルのコピー、ユーザーの作成、コマンドの実行、サービスの開始などがあります。 現在、デフォルトの Ansible インストールには 400 種類以上のモジュールが含まれており、さらにはコミュニティからも多くのモジュールが提供されていますが、独自に作成することもできます。
モジュールは自動化ワークフローを実行する手段として、プレイとプレイブックを作成するために組み合わされます。 プレイは複数のタスクを持つことができ、プレイブックは複数のプレイを持つことができます。
ロールを使うと、複数のプレイブックを組み合わせることができます。 ロールは、ターゲットサーバーの使用状況に応じてサーバーのコンポーネント構成をグループ化するものと考えることができます。 この投稿のロールの例では、サーバーを構築するための構成レイヤーを構築します。
私のベンチマーク環境では、次のロールを使用してサーバーを構築しています。
- hs_server_common: OS の構成、Apache のインストール、Caché のインストール。
- webserver: Webファイル(csp、html、js など)のコピー、アプリケーション用のApacheの構成。
- generator: ファイルのコピー、Webストレスジェネレーターのデータベース / ネームスペース / グローバルマッピングなどの作成と構成。
- dbserver:ファイルのコピー、DBサーバーシステムの設定 / アプリケーションデータベース / ネームスペース / グローバルマッピングなどの構成。
これらのロールを組み合わせて、さまざまなサーバータイプを構築できます。
- hs_server_common + webserver + generator = Web ストレスジェネレーターサーバー。
- hs_server_common + webserver = アプリケーション Web サーバー。
- hs_server_common + dbsevrer = データベースサーバー。
ロールを構成するものや各ロールに含まれる構成は、デプロイされるアプリケーションによって大きく異なります。 この投稿の例では、オペレーティングシステムの事前構成を前提とする最小限のタスクセットを使用しますが、Ansible や Galaxy で利用可能なモジュールを使用すると、はるかに複雑なフル機能のシステム構成が可能になります。
Caché のインストールに関するメモ {.MsoNormal}
私はいくつかの興味く便利な機能を紹介するため例を記載しましたが、その中でも以下は特に注目すべきものです。 注: これらの例は、InterSystems データプラットフォーム(Caché、HealthShare、Ensemble)をインストールするためのガイドとして使用できます。 HealthShare をインストールする例を書きましたが、HealthShare と Caché には同じ機能があります。
./testserver/roles/hs_server_common/tasks/main.yml
これは、一般的な OS の構成、Apache のインストール、Caché のインストールの各タスクに使えるメインラインスクリプトです。 この投稿ではCaché をインストールおよび構成するため、Red Hat のインクルードファイルのみに短縮しています。 Ansible が起動した後、オペレーティングシステムの情報がスクリプトで決定を行うために使用できる ansible_os_family などの ansible* _変数に保持されていることがわかります。
./testserver/roles/hs_server_common/tasks/configure-healthshare2015.yml
これは、Caché をインストールするためのメインスクリプトです。 スクリプトを見ると、次のようなターゲット上のタスクの論理ワークフローがわかります。
- オペレーティングシステムのユーザーとグループを作成する。
- コントローラーのマニフェストフォルダーからインストールファイルをコピーする。
- インストールファイルを解凍する。
- サイレントインストールを使用して Caché をインストールする(以下の注意書きを参照)。
- Caché キーファイルをコピーする。
- デフォルト Caché インスタンスを設定する。
- Apache を再起動する。
- Caché を再起動する。
Caché のサイレントインストールには、次のようないくつかのオプションがあります。
- parameters.is ファイルを使用する。 テンプレートの .isc ファイルは以前のインストールによって作成されたもので、そのまま使用することも、変更して使用することもできます。
- 環境で設定されたキーと値のペアで cinstall_silent を使用する。
- %installer クラスを使用する。
この例では、install_silent を使用することを選択しましたが、Ansible でテンプレートファイルを使用する方法を示すため、パラメーターファイルを使用する代替方法もコメントに含めています(./roles/hs_server_common/templates/parameters_hs20152_rh64.isc を参照してください)。
後の投稿では、Caché をインストールする際とデータベースおよびネームスペースを設定する際に %installer クラスを使用する方法を説明します。 インストールオプションの詳細は、Caché のオンラインドキュメントで確認できます。また、コミュニティには %installer クラスの使用に関する素晴らしい投稿もあります。
パラメーターファイルは、旧バージョンの Caché で Caché 組み込みの Apache バージョン以外の Web サーバで CSP Gateway を使用するように Cachéをインストールして構成する場合に役立ちます。 この機能は、Caché 2016.1の %installer で使用できます。
./testserver/roles/hs_server_common/tasks/setup_RedHat.yml
この例は、システム固有の変数(ansible_*)の使用方法とオペレーティングシステム変数の設定を説明するためのものです。
./testserver/roles/hs_server_common/vars/*
変数ファイルのキーと値のペアには変数が含まれています。ご覧のとおり、さまざまな環境や状況で同じスクリプトを再利用することができます。
Caché インストールの実行
この例では、システムが使用可能であり、次のように設定されていることを想定しています。
- コントローラーに Ansible がインストールされており、次のディレクトリに GitHub からファイルと構造が読み込まれていること。
- ./testserver/* : インベントリ、.yml ファイルなどを含むディレクトリツリー。 次のディレクトリを含みます。
- ./testserver/Distribution_Files/Cache : (Caché ディストリビューションと cache.key を含むマニフェスト)。
- ターゲットマシンに Red Hat と Apache がインストールされていること。
テスト環境に合わせてインストールをカスタマイズするには、次のファイルを編集する必要があります。
- inventory_test
テストサーバー名または IP アドレスを編集する必要があります。
- ./testserver/roles/hs_server_common/vars/healthshare2015.yml
テスト環境に合わせてパスを編集する必要があります。 ターゲットサーバーの次のパスを確認します。
- common_install_base_path: マニフェストファイルがコピーされ、解凍され、Caché インストールが実行されるパスです。
- ISC_PACKAGE_INSTALLDIR: Caché のインストールディレクトリです。
ディレクトリパスが存在しない場合は、ターゲットサーバー上に作成されます。
- name: unattended install of hs using cinstall_silent
shell: >
ISC_PACKAGE_INSTANCENAME="{{ ISC_PACKAGE_INSTANCENAME }}"
ISC_PACKAGE_INSTALLDIR="{{ ISC_PACKAGE_INSTALLDIR }}"
ISC_PACKAGE_UNICODE="{{ ISC_PACKAGE_UNICODE }}"
ISC_PACKAGE_INITIAL_SECURITY="{{ ISC_PACKAGE_INITIAL_SECURITY }}"
ISC_PACKAGE_MGRUSER="{{ ISC_PACKAGE_MGRUSER }}"
ISC_PACKAGE_MGRGROUP="{{ ISC_PACKAGE_MGRGROUP }}"
ISC_PACKAGE_USER_PASSWORD="{{ ISC_PACKAGE_USER_PASSWORD }}"
ISC_PACKAGE_CACHEUSER="{{ ISC_PACKAGE_CACHEUSER }}"
ISC_PACKAGE_CACHEGROUP="{{ ISC_PACKAGE_CACHEGROUP }}" ./cinstall_silent
chdir="{{ common_install_base_path }}/{{ hs_install_unpack_path }}"
args:
creates: "{{ ISC_PACKAGE_INSTALLDIR }}/cinstall.log"上の節は creates パラメータを使用し、このアクションが cinstall.log ファイルを作成することを Ansible モジュール(この場合は shell モジュール)に知らせています。 モジュールがこのファイルを検出した場合(Caché はすでにインストールされている状態)、このステップは実行されません。
すべての設定が完了したら、インストールを実行できます。
$ ansible-playbook dbserver.yml PLAY [dbservers] ************************************************************** GATHERING FACTS *************************************************************** ok: [db1] TASK: [hs_server_common | include_vars healthshare2015.yml] ******************* ok: [db1] TASK: [hs_server_common | include_vars os-RedHat.yml] ************************* ok: [db1] etc etc etc TASK: [hs_server_common | Create default cache group] ************************* changed: [db1] TASK: [hs_server_common | Create default cache manager group] ***************** changed: [db1] TASK: [hs_server_common | Create default cache user] ************************** changed: [db1] TASK: [hs_server_common | Create default cache system users] ****************** changed: [db1] TASK: [hs_server_common | Create full hs install temp directory] ************** changed: [db1] TASK: [hs_server_common | Check tar file (gunzipped already) does not exist] *** ok: [db1] TASK: [hs_server_common | Copy healthshare install file] ********************** changed: [db1] TASK: [hs_server_common | un zip hs folder] *********************************** changed: [db1] TASK: [hs_server_common | un tar hs install] ********************************** changed: [db1] TASK: [hs_server_common | Create hs install directory] ************************ changed: [db1] TASK: [hs_server_common | touch ztrak.conf.] ********************************** changed: [db1] TASK: [hs_server_common | Process parameters file] **************************** changed: [db1] TASK: [hs_server_common | unattended install of hs using cinstall_silent] ***** changed: [db1] TASK: [hs_server_common | copy hs key] **************************************** changed: [db1] TASK: [hs_server_common | Set default hs instance] **************************** changed: [db1] TASK: [hs_server_common | restart apache to initialize CSP.ini file] ********** changed: [db1] NOTIFIED: [hs_server_common | restart healthshare] **************************** changed: [db1] PLAY RECAP ******************************************************************** db1 : ok=32 changed=21 unreachable=0 failed=0
ターゲットサーバーを見ると、db サーバーの Caché が稼働しています。
$ ccontrol list
Configuration 'H2015' (default) directory: /test/hs2015 versionid: 2015.2.1.705.0 conf file: cache.cpf (SuperServer port = 1972, WebServer = 57772) status: running, since Wed Feb 17 15:59:11 2016 state: ok
最後に
次の投稿では、構成ファイルの編集や %installer クラスを使用したアプリケーションの構成など、他のタスクでスクリプトを構築します。
この投稿に興味を持ち、独自のデプロイを作成し始めた方は、ご質問やご提案がございましたらお気軽にお問い合わせください。 私は仮想化とパフォーマンスについて Global Summit で定期的に講演を行っています。今年の Global Summit に参加される予定の方は自己紹介をお願いします。Ansible やその他のシステムアーキテクチャに関する皆様のご経験をお聞かせください。















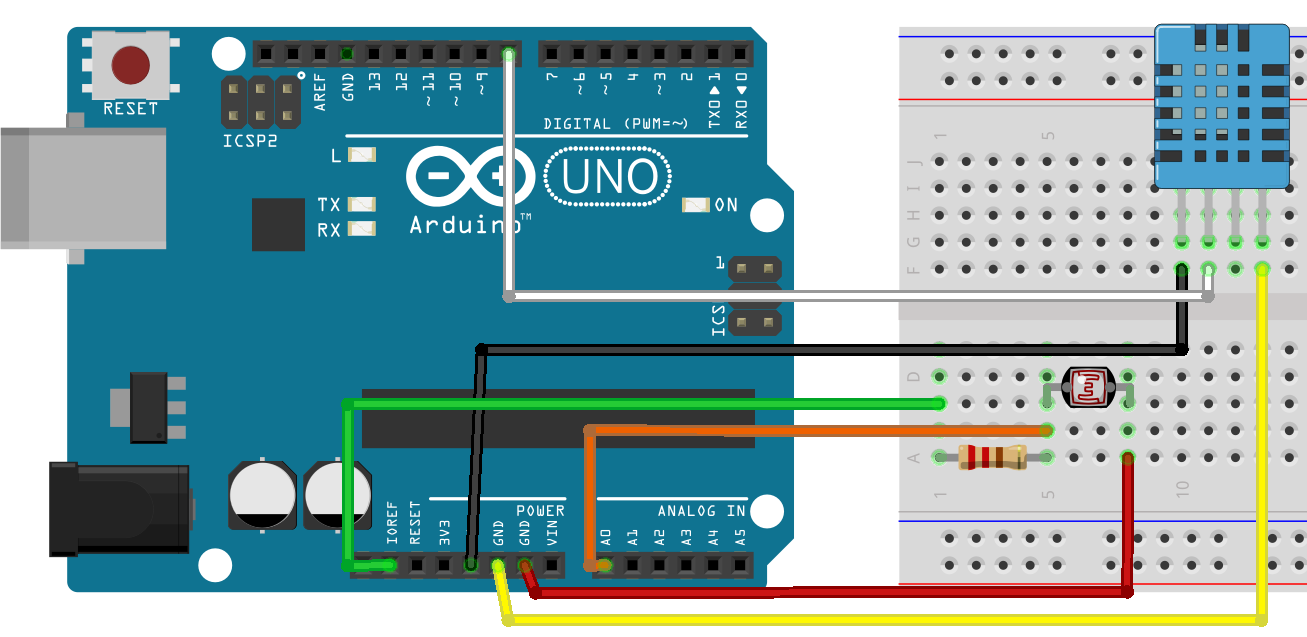







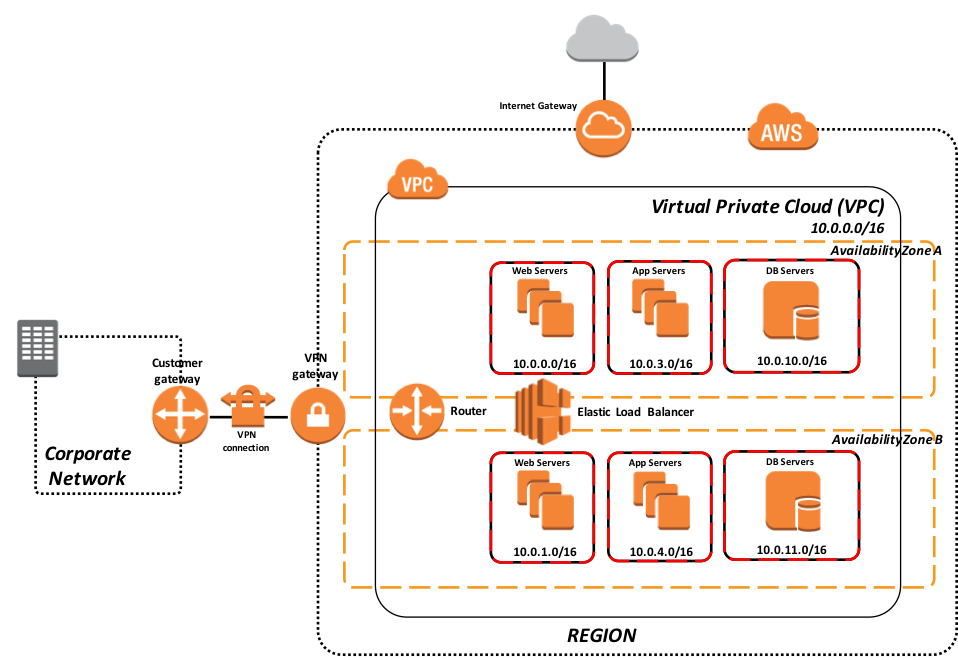
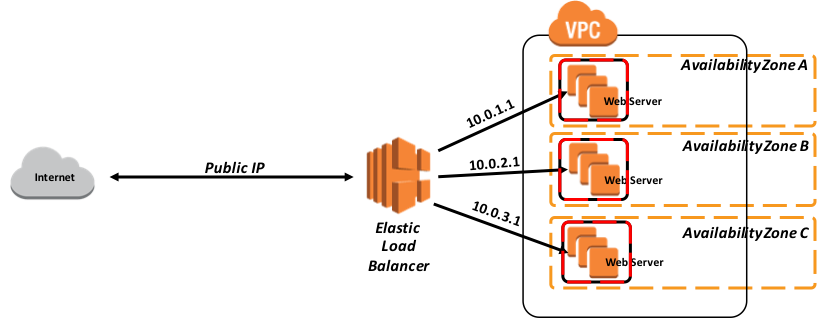
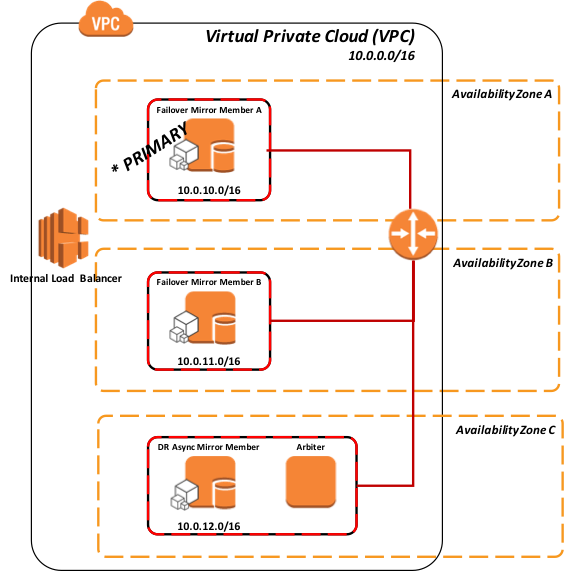
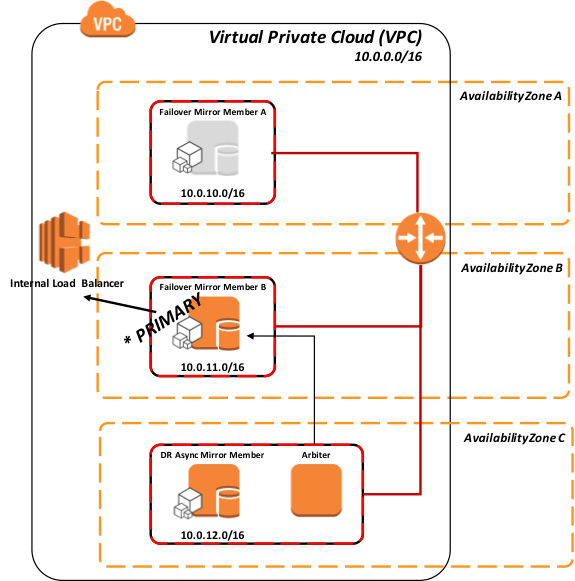
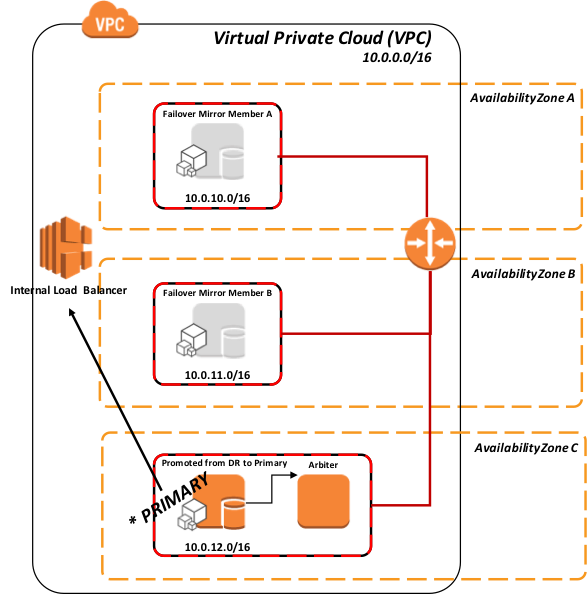
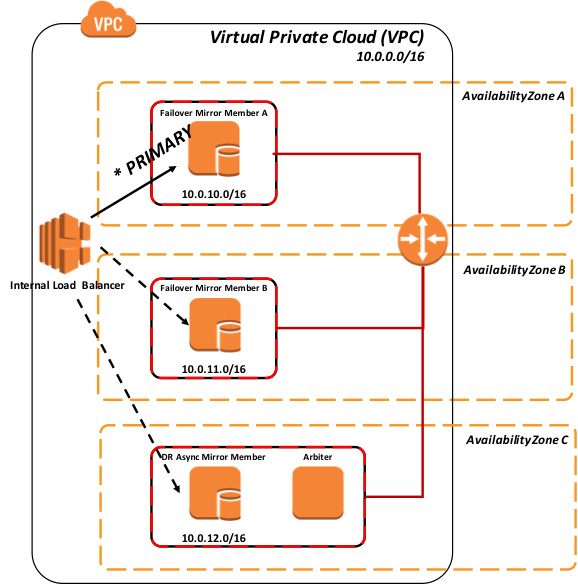
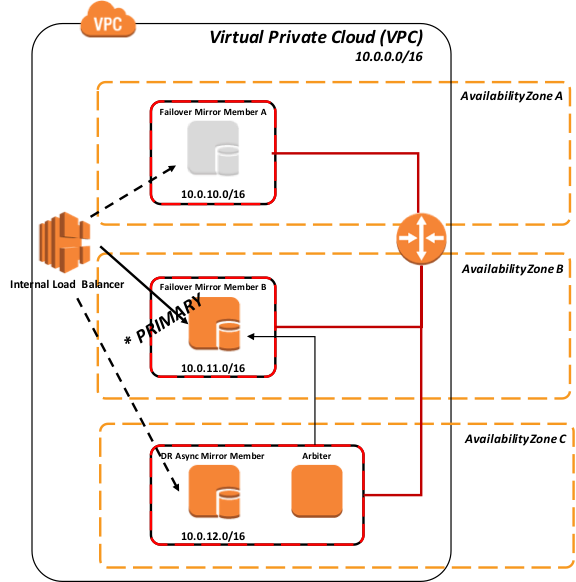
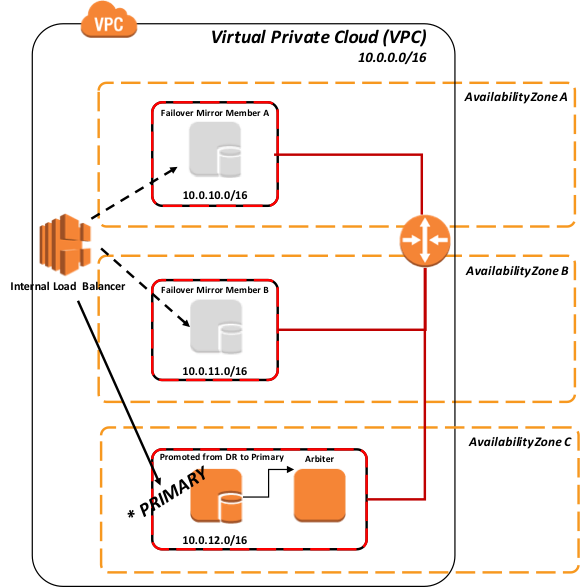
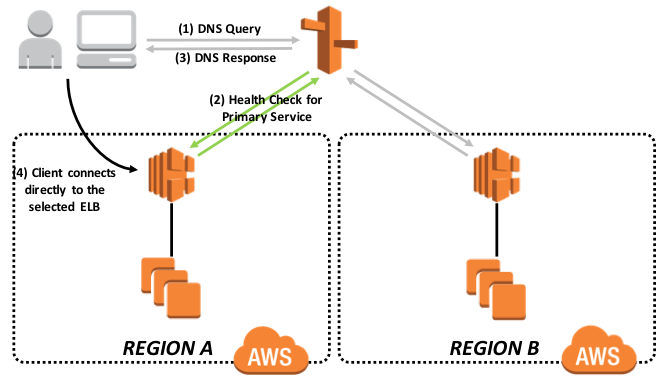
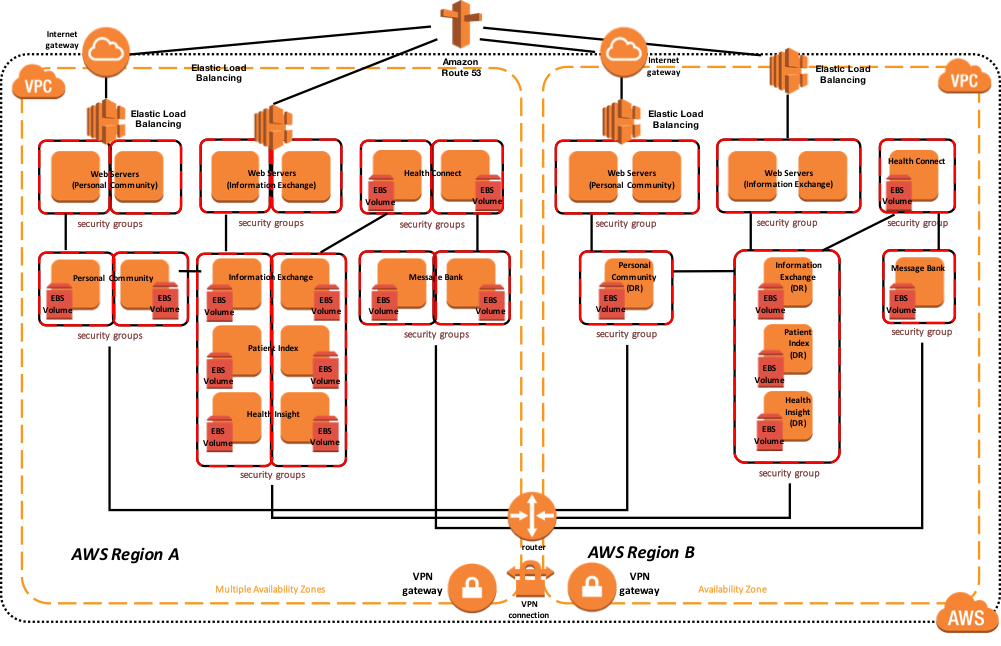
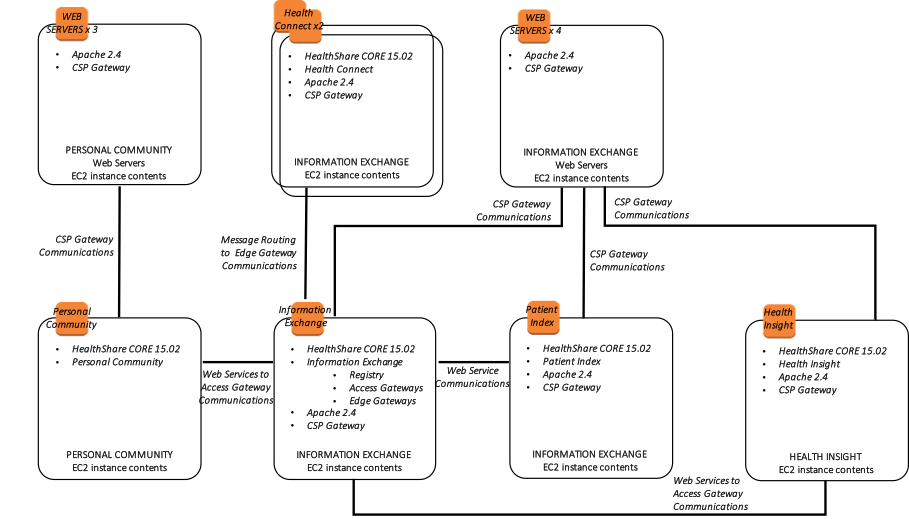
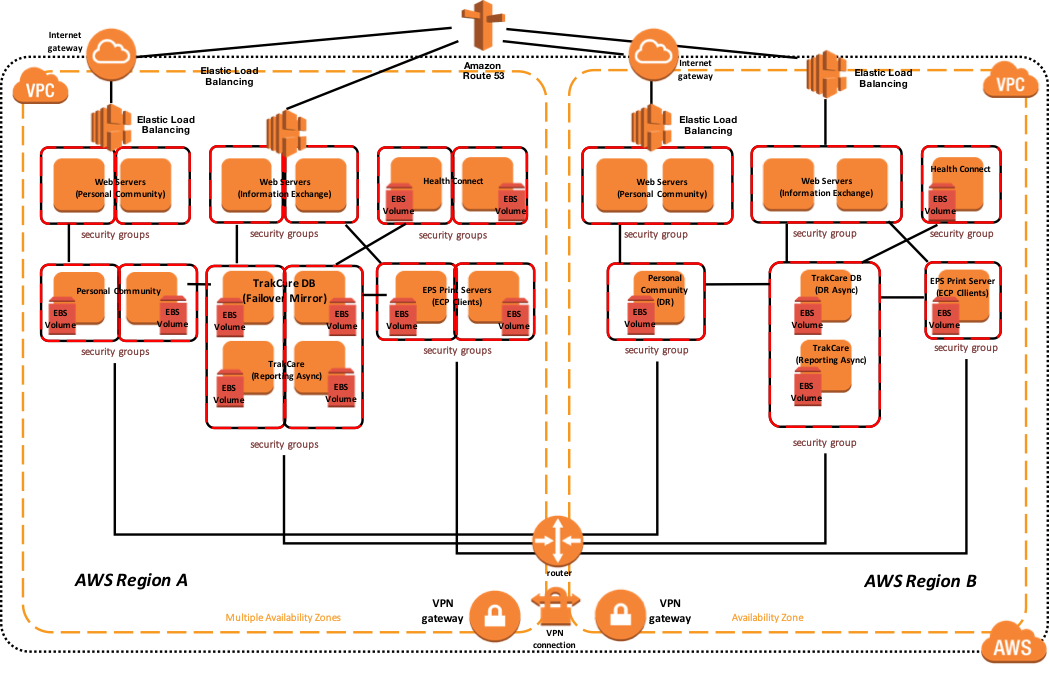 さらに、次の図は、関連するインストールされたエンドユーザ向けソフトウェア製品と機能的な目的で、より論理的なアーキテクチャを示しています。
さらに、次の図は、関連するインストールされたエンドユーザ向けソフトウェア製品と機能的な目的で、より論理的なアーキテクチャを示しています。

 画像のように、AUTHSERVER にはその秘密鍵と証明書がありますが、CLIENT に関しては公開鍵を含む証明書しかありません。
画像のように、AUTHSERVER にはその秘密鍵と証明書がありますが、CLIENT に関しては公開鍵を含む証明書しかありません。 ここで、CLIENT には秘密鍵と証明書がありますが、AUTHSERVER に関しては公開鍵を含む証明書しかありません。
ここで、CLIENT には秘密鍵と証明書がありますが、AUTHSERVER に関しては公開鍵を含む証明書しかありません。



 サーバー構成を定義したら、サーバークライアント構成を入力する必要があります。 サーバー構成フォームのページ内で、「Client Configurations」(クライアント構成)ボタンをクリックし、CLIENT インスタンスおよび RESSERVER インスタンスの「Create New Configuration」(新しい構成の作成)をクリックします。
(IRISを使用して構成している場合は、「クライアントディスクリプション」の構成ページから以下の設定を行います。)
以下の画像は CLIENT の構成を示しています。
サーバー構成を定義したら、サーバークライアント構成を入力する必要があります。 サーバー構成フォームのページ内で、「Client Configurations」(クライアント構成)ボタンをクリックし、CLIENT インスタンスおよび RESSERVER インスタンスの「Create New Configuration」(新しい構成の作成)をクリックします。
(IRISを使用して構成している場合は、「クライアントディスクリプション」の構成ページから以下の設定を行います。)
以下の画像は CLIENT の構成を示しています。


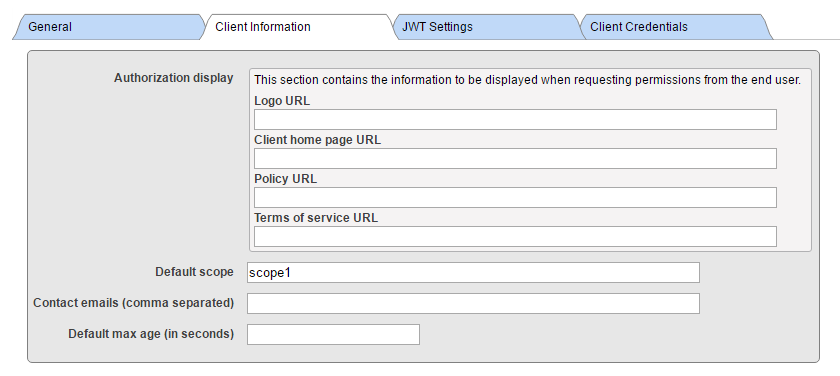
 JWT Token(JWT トークン)タブはデフォルト値である空のままにします。 ご覧のとおり、実際のアプリケーションの場合とは異なり、フィールドには無意味なデータが入力されています。
同様に、RESSERVER の構成を示します。
JWT Token(JWT トークン)タブはデフォルト値である空のままにします。 ご覧のとおり、実際のアプリケーションの場合とは異なり、フィールドには無意味なデータが入力されています。
同様に、RESSERVER の構成を示します。

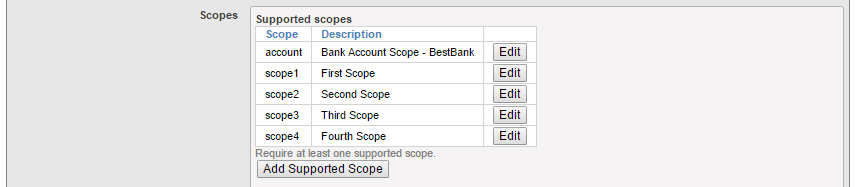
 ご覧のとおり、リソースサーバーに必要なのは非常に基本的な情報だけです。具体的には、Client type(クライアント種別)をリソースサーバーに設定する必要があります。 CLIENT では、より詳細な情報とクライアント種別を入力する必要があります(クライアントはクライアントシークレットをサーバーで維持し、クライアントエージェントには送信しない Web アプリケーションとして動作するため、機密(confidential)を選択します)。
ご覧のとおり、リソースサーバーに必要なのは非常に基本的な情報だけです。具体的には、Client type(クライアント種別)をリソースサーバーに設定する必要があります。 CLIENT では、より詳細な情報とクライアント種別を入力する必要があります(クライアントはクライアントシークレットをサーバーで維持し、クライアントエージェントには送信しない Web アプリケーションとして動作するため、機密(confidential)を選択します)。 Issuer Endpoint(発行者エンドポイント)が、AUTHSERVER インスタンスで前に定義した値に対応していることを必ず確認してください! また、認可サーバーのエンドポイントを Web サーバーの構成に従って変更する必要があります。 この場合は各入力フィールドに「authserver」を埋め込んだだけです。
次に、新しく作成された発行者エンドポイントの横にある「Client Configurations」(クライアント構成)リンクをクリックし、「Create Client Configuration」(クライアント構成の作成)ボタンをクリックします。
Issuer Endpoint(発行者エンドポイント)が、AUTHSERVER インスタンスで前に定義した値に対応していることを必ず確認してください! また、認可サーバーのエンドポイントを Web サーバーの構成に従って変更する必要があります。 この場合は各入力フィールドに「authserver」を埋め込んだだけです。
次に、新しく作成された発行者エンドポイントの横にある「Client Configurations」(クライアント構成)リンクをクリックし、「Create Client Configuration」(クライアント構成の作成)ボタンをクリックします。


 以上です! ここまでの手順で CLIENT と AUTHSERVER の両方を構成しました。 多くの使用事例ではこれだけで十分です。リソースサーバーは単なる AUTHSERVER のネームスペースにすぎず、結果的にすでに保護されている場合があるからです。 しかし、外部の医師が内部の臨床システムからデータを取得しようとしている使用事例に対応する場合を考えてみましょう。 このような医師がデータを取得できるようにするため、この医師のアカウント情報を監査目的と法医学的な理由でリソースサーバー内に確実に保存したいと思います。 この場合は、続けて RESSERVER を定義する必要があります。
以上です! ここまでの手順で CLIENT と AUTHSERVER の両方を構成しました。 多くの使用事例ではこれだけで十分です。リソースサーバーは単なる AUTHSERVER のネームスペースにすぎず、結果的にすでに保護されている場合があるからです。 しかし、外部の医師が内部の臨床システムからデータを取得しようとしている使用事例に対応する場合を考えてみましょう。 このような医師がデータを取得できるようにするため、この医師のアカウント情報を監査目的と法医学的な理由でリソースサーバー内に確実に保存したいと思います。 この場合は、続けて RESSERVER を定義する必要があります。 ここでは、Cache 2017.1 に実装された新機能である検出機能を使用しました。
ご覧のように、この構成は CLIENT インスタンスの対応する構成と同じデータを使用しています。
次に、新しく作成された発行者エンドポイントの横にある「Client Configurations」(クライアント構成)リンクをクリックし、「Create Client Configuration」(クライアント構成の作成)ボタンをクリックします。
ここでは、Cache 2017.1 に実装された新機能である検出機能を使用しました。
ご覧のように、この構成は CLIENT インスタンスの対応する構成と同じデータを使用しています。
次に、新しく作成された発行者エンドポイントの横にある「Client Configurations」(クライアント構成)リンクをクリックし、「Create Client Configuration」(クライアント構成の作成)ボタンをクリックします。

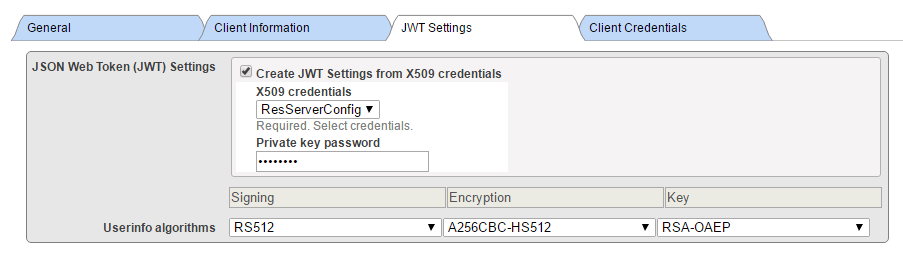 X.509 資格情報から JWT を作成することはお勧めしませんが、ここでは互換性のために使用しました。
X.509 資格情報から JWT を作成することはお勧めしませんが、ここでは互換性のために使用しました。
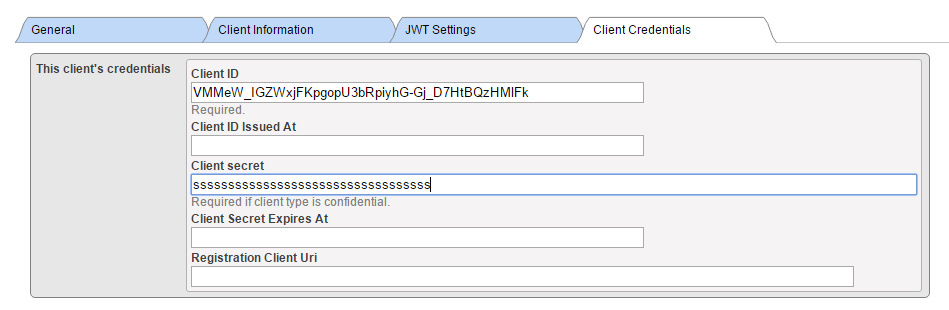 CLIENTとほとんど同じ手順でしたが、必要なものでした。 しかし、これで先に進んでコーディングできるようになりました!
CLIENTとほとんど同じ手順でしたが、必要なものでした。 しかし、これで先に進んでコーディングできるようになりました!